[LLM] LLM 기반의 시스템을 평가하는 방법을 알아보자
LLM 성능 평가
1. Performance Metrics
(1) 통계적인 방식의 Metrics

- BLEU Score: 기계 번역 품질을 평가. LLM의 출력과 레퍼런스 번역의 일치 정도를 평가 (단어 일치 중심).
- ROUGE Score: 텍스트 요약 품질 평가. 출력 요약이 레퍼런스 요약의 핵심 키워드를 얼마나 잘 반영하는지 평가.
딥러닝 기반의 생성 모델(Generative Model)은 텍스트 생성, 챗봇, 문서 요약 등 다양한 분야에서 사용. 생성된 문장을 평가하는 방법으로는 BLEU와 ROUGE 두 가지가 있으며, 이를 통해 모델의 성능을 측정할 수 있음
BLEU와 ROUGE의 차이
- ROUGE: Reference Sentence의 단어가 Generated Sentence에 포함되는 정도를 측정.
- BLEU: Generated Sentence의 단어가 Reference Sentence에 포함되는 정도를 측정.
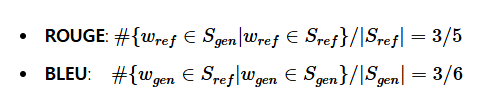
예시:
- 생성된 문장: "I was generated by the model"
- 정답 문장: "I was referenced by human"
공통 단어: "I", "was", "by" [ ROUGE: 3/5 / BLEU: 3/6 ]
- ROUGE: 주로 텍스트 요약(Text Summarization)에서 사용.
- BLEU: 주로 기계 번역(Machine Translation)에서 사용.
- 여러 개의 정답이 있을 수 있으므로, BLEU를 계산할 때 중복된 Reference도 고려하여 계산함.
- BLEU는 0에서 1 사이의 값을 가지며, 값이 클수록 생성된 문장이 더 정확함을 의미.
- ROUGE는 텍스트 요약에서의 평가에 주로 사용되고, BLEU는 기계 번역에서 자주 사용됨.
- Perplexity (PPL): 텍스트 예측의 난이도를 측정. 모델이 예측하는 정확도를 나타내는 지표.
- METEOR Score: 기계 번역 품질 평가 지표. BLEU Score와는 달리 의미적 유사성도 고려.
- Classification metrics: 정확도(Accuracy), 정밀도(Precision), 재현율(Recall), F1 Score 등으로 분류 성능 평가.
통계적인 방식의 metrics는 단어나 토큰에 내재된 의미(meaning-preserving lexical)와 통사구조의 다양성(compositional diversity)을 제대로 평가하지 못한다는 한계가 있다.
(2) 딥러닝 방식의 Metrics
- BERTScore: BERT의 Contextual Embedding을 활용하여, 문장 간 의미적 유사성을 평가.
BERT의 Contextual Embedding을 활용하여 모델이 생성한 후보 문장과 사람이 직접 만든 레퍼런스 문장 간의 의미적 유사성을 평가하는 지표이다. 문장 수준과 시스템 수준의 평가에서 인간의 판단과 높은 상관관계를 보이며, 텍스트 생성의 품질을 평가하기 위해 사용된다.
https://velog.io/@tobigs-nlp/BERTScore-Evaluating-Text-Generation-with-BERT
BERTScore: Evaluating Text Generation with BERT
BERT Embedding을 가지고 문장의 유사성을 평가하자! | 17기 장준원
velog.io
- MoverScore: Earth Mover’s Distance를 사용하여 문장 간 의미적 유사성을 평가하는 지표.
ERTScore와 비슷하지만, 각 토큰 사이에 soft alignment를 사용하여 더 유연하게 토큰간 유사성을 평가할 수 있고, Earth Mover’s Distance(EMD) 알고리즘을 변형 사용하여 후보 문장과 레퍼런스 문장 사이의 의미적 거리를 계산하여 좀 더 정교하게 유사도 측정이 가능하다.
2. Benchmarks
대표적인 벤치마크 데이터셋을 사용하여 LLM의 성능을 평가할 수 있습니다.
- ARC: 과학 문제 해결 능력 평가.
- HellaSwag: 상식 추론 능력 평가.
- MMLU: 다양한 분야에 걸친 멀티태스크 언어 이해 능력 평가.
- TruthfulQA: 모델의 진실성 평가.
- Winogrande: 대명사 해석을 통한 문맥 추론 능력 평가.
- GSM8k: 초등학교 수준 수학 문제를 통한 수학적 추론 능력 평가.
한국어 벤치마크
- Ko-ARC, Ko-HellaSwag, Ko-MMLU, Ko-TruthfulQA, Ko-CommonGen V2 등 다양한 한국어 벤치마크가 존재.
1. Open Ko-LLM 리더보드(AI Hub):
- 한국어 LLM을 대상으로 한국어 벤치마크 데이터에 대해 성능을 평가 &리더보드 운영
- https://www.aihub.or.kr/leaderboard/view.do?currMenu=500&topMenu=102
- 평가 항목:
- 추론능력 (ARC, AI2 Reasoning Challenge) - 초등학교 수준의 과학 질문 등에 대해 AI의 답변이 얼마나 적절한지 측정
- 상식 능력 (HellaSwag) - 짧은 글 혹은 지시사항에 알맞은 문장을 생성하는지 측정
- 언어 이해력 (MMLU) - 57가지 다양한 분야의 질문에 대해 답변이 얼마나 측정했는지 측정
- TruthfulQA - AI가 생성한 답변이 얼마나 진실한지 측정
- 한국어 상식 생성 능력 - 역사 왜곡, hallucination, 혐오표현 등 광범위한 질문에 대한 일반 상식 측정
2. LogicKor
https://github.com/instructkr/LogicKor
GitHub - instructkr/LogicKor: 한국어 언어모델 다분야 사고력 벤치마크
한국어 언어모델 다분야 사고력 벤치마크. Contribute to instructkr/LogicKor development by creating an account on GitHub.
github.com
https://docs.vllm.ai/en/v0.5.5/models/lora.html
3. TTFT
TTFT(Time To First Token) 평가지표는 모델의 input에 대한 ouput까지의 시간을 측정하는 것
예시 코드:
import time
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
model_name = "gpt2" # TTFT 측정 원하는 LLM 모델
model = AutoModelForCausalLM.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# 입력
input_text = "What is the capital of France?"
# TTFT 측정을 위한 함수
def measure_ttft(input_text):
inputs = tokenizer(input_text, return_tensors="pt")
start_time = time.time() # 시간 측정 시작
with torch.no_grad():
outputs = model.generate(
**inputs,
max_length=50,
num_return_sequences=1
)
# 첫 번째 토큰이 생성된 시간 (TTFT 결과)
ttft = time.time() - start_time
return ttft, tokenizer.decode(outputs[0], skip_special_tokens=True)
# TTFT 측정
ttft, output_text = measure_ttft(input_text)
print(f"TTFT (Time to First Token): {ttft:.4f} seconds")
print(f"Generated Text: {output_text}")3. Human Evaluation
사람이 직접 기준을 설정하여 LLM 출력을 평가하는 방식:
- Golden Dataset 준비: 사람이 검증한 질문-답변을 레퍼런스로 사용.
- 점수화 기준 설정: 정확성, 유창성, 일관성 등 다양한 기준을 설정.
- 점수화 및 평가: 정성적인 기준을 통해 LLM의 성능 평가.
- LMSYS Chatbot Arena: LMSYS Chatbot Arena는 블라인드 상태에서 LLM 성능을 상대적으로 비교, 평가하기 위한 크라우드소싱 방식의 벤치마크 플랫폼이다. 사용자는 블라인드 상태에서 두가지 다른 LLM 출력 결과 중 더 성능이 좋다고 판단되는 LLM에게 투표를 하며, 사용자 투표를 통해 축적된 점수를 통해 LLM의 순위가 산정된다. 이 방식을 통해 다양한 human feedback 바탕의 평가가 가능하다는 장점이 있다.

4. Model-based Evaluation
(1) LLM 측정 Metric 방식
- GPTScore: 사전학습된 생성 모델을 기반으로, LLM 출력의 점수를 계산.
- G-Eval: LLM의 생성 결과물을 평가하는 프레임워크. Chain-of-Thought(연쇄적 사고)와 양식 채우기 기법을 활용.
(2) LLM-as-a-Judge (모델로 모델 성능 평가)
- MT-bench: LLM의 대화 및 추론 능력을 평가하는 데이터셋. 고성능 LLM을 평가자로 사용.
MT-bench는 총 80개의 고품질 multi-turn 질문으로 구성되어 LLM의 ‘대화 및 추론’ 능력을 종합적으로 평가하는 데이터셋이다. writing, roleplay, extraction, reasoning, math, coding, knowledge I (STEM), and knowledge II (humanities/social science)라는 8가지의 주제에 대하여 각각 10개씩 멀티턴 질문셋으로 구성되어 있다. 이 때 MT-bench는 주관식이고 패턴화하기 어려운 답변들이기 때문에 그 결과를 평가할 때 GPT4와 같이 고성능의 LLM을 Evaluator, 즉 LLM-as-a-judge의 역할로 사용한다. LLM을 통해 LLM의 성능을 평가하는 방식을 통해 인간이 직접 평가할 때보다 빠르고 확장 가능하다.
- Chatbot Arena: GPT-4와 같은 모델을 사용하여 LLM 성능을 평가.
[한국어 LLM 벤치마크] Korean MT-bench score 계산하기 (1)
한국어 LLM 리더보드인 호랑이에 대해 리뷰를 진행해보고, 외부 오픈소스 모델 및 내부 사내 자체 개발 모델에 대해 평가를 진행해보기로 결정! 호랑이 한국어 LLM 리더보드에 대한 소개는 아래
didi-universe.tistory.com
한국어 버전도 있음
5. Evaluation Frameworks
LLM 평가를 위한 오픈소스 프레임워크들이 존재:
- DeepEval: 다양한 LLM 평가 지표를 사용하여 벤치마크 평가.
- Phoenix: 실험, 평가, 트러블슈팅 등을 위한 프레임워크. 다양한 환경에서 실행 가능.
- RAGAs: RAG 파이프라인을 평가하는 프레임워크.
추가 참고 자료
https://devocean.sk.com/blog/techBoardDetail.do?ID=166716&boardType=techBlog
LLM 성능, 어떻게 평가하는 것일까? (feat. lm-eval-harness)
devocean.sk.com
LLM 성능 평가 시스템 구축의 어려움
LLM(대형 언어 모델)의 성능을 평가하는 일은 여러 가지 이유로 매우 어려운 과제가 됨. 이 어려움을 이해하려면 먼저 LLM의 특성에 대해 살펴볼 필요가 있음. LLM은 텍스트 데이터를 기반으로 작동하며, 정해진 "정답"이 없기 때문에 평가 기준을 설정하는 것이 매우 주관적이고 복잡한 문제임. 이 외에도 다양한 외부 요인과 변수들이 성능 평가에 영향을 미침.
1. 정답의 부재
- LLM의 답변은 정해진 정확한 답을 제공하는 것보다는 다양한 가능성 중 가장 합리적이고 적합한 답을 생성함. 하지만 "올바른" 답이 무엇인지를 판단하는 것은 매우 주관적임. 이는 성능 평가에 큰 장애물로 작용함.
2. 모델 내부의 복잡성
- LLM의 성능은 단순히 모델의 크기나 파라미터 수로 결정되지 않음. 학습 과정에서 사용된 데이터셋, 학습된 파라미터, 모델 아키텍처, 그리고 외부 시스템(예: 검색증강생성(RAG))과의 통합 등 다양한 요소가 영향을 미침. 각 요소들이 성능에 미치는 영향을 정확히 평가하는 것은 매우 어려운 일이 됨.
3. RAG 시스템의 영향
- LLM의 성능을 평가할 때 RAG(검색증강생성) 시스템의 복잡성을 고려해야 함. RAG는 벡터DB, 청킹, 임베딩 등 여러 구성 요소를 포함하고 있으며, 이들 각 요소들이 LLM의 출력 품질에 중요한 영향을 미침. 따라서, RAG 컴포넌트를 포함한 전체 시스템의 성능을 평가하는 것은 매우 복잡한 작업임.
4. 유용성 및 실용성 평가의 어려움
- LLM의 답변이 얼마나 유용하고 실용적인지, 비즈니스나 기술적 요구 사항에 맞는지 여부를 평가하는 것은 중요한 평가 지표이지만 이를 정확히 측정하는 방법은 명확히 정의되지 않음. 이러한 유용성과 실용성을 평가하는 기준을 설정하는 일은 여전히 연구되고 있는 분야임.
LLM을 평가하는 것과 LLM 기반의 시스템을 평가하는 것은 다른 개념
https://littlefoxdiary.tistory.com/122
LLM Evaluation | LLM 기반의 시스템을 어떻게 평가할 수 있을까
지난 포스팅에서 다루었던 것처럼 LLM의 문맥 이해 및 자연어 생성 능력 능력이 향상되었고, fine-tuning API, Plug-in 지원 등이 이루어지면서 다양한 애플리케이션 개발이 가능해졌다. 개인의 창의성
littlefoxdiary.tistory.com
LLM 평가와 LLM 기반 시스템 평가
1. LLM 평가
- LLM 평가는 기본 LLM의 전반적인 성능을 평가하는 것입니다.
- 주로 벤치마크 데이터셋에 대해 LLM의 생성 결과를 ground truth label과 비교하여 점수를 매깁니다.
- OpenAI Eval 라이브러리
- 다양한 생성 기반 태스크에 대해 LLM 성능을 평가하는 리더보드를 운영합니다.
- 예시:
- HellaSwag: 모델이 문장을 얼마나 잘 완성할 수 있는지 평가.
- TruthfulQA: 모델 출력의 진실성을 평가.
- MMLU: LLM이 여러 태스크를 얼마나 잘 수행할 수 있는지 평가.
- Open Ko-LLM 리더보드 (AI Hub)
- 한국어 LLM을 대상으로, 한국어 벤치마크 데이터에 대해 성능을 평가하고 리더보드를 운영합니다.
- 평가 항목:
- 추론 능력: 초등학교 수준의 과학 질문 등에 대해 AI가 얼마나 적절히 답변하는지.
- 상식 능력: 짧은 글이나 지시 사항에 맞는 문장을 생성하는지 평가.
- 언어 이해력: 57가지 다양한 분야의 질문에 대해 LLM이 얼마나 잘 답변하는지 평가.
- TruthfulQA: AI가 생성한 답변이 얼마나 진실한지 평가.
- 한국어 상식 생성 능력: 역사 왜곡, hallucination, 혐오 표현 등 광범위한 질문에 대한 일반 상식 측정.
- OpenAI Eval 라이브러리
2. LLM 기반 시스템 평가
- LLM 기반의 시스템 평가는 단순히 LLM의 성능을 평가하는 것에서 벗어나, 실제 시스템에서 어떻게 동작하는지를 평가하는 것임
- 시스템 내에서 중요한 요소는 프롬프트와 컨텍스트. 이 요소들이 입력에 따라 어떻게 출력을 결정짓는지에 대한 평가가 필요함.
시스템 평가의 특징:
- LLM의 성능은 그대로 두고, 프롬프트 템플릿을 변경하여 결과를 관찰하는 방식으로 진행됨.
- 프롬프트는 시스템에서 자주 바뀌는 요소이므로, 프로젝트 진행 중 여러 번 평가가 이루어져야 함. 예를 들어, 유용성, 정중함 등 챗봇 응답의 다양한 평가가 가능.
- LLM 기반 시스템의 평가에서는, 시스템이나 유즈케이스에 따라 평가 지표(metric)가 달라진다. 각 유즈케이스에 맞는 평가 지표를 도입해야 함.
예시 지표:
- 구조화된 정보 추출: 완전성(입력에 있는 모든 정보가 결과에 포함되었는지)과 같은 LLM이 정보를 얼마나 잘 추출하는지 평가.
- 질문답변 시스템: 정확성, 간결성, 정중함 등의 지표를 사용하여, LLM이 사용자의 질문에 얼마나 잘 답변하는지 평가.
- RAG (Retrieval Augmented Generation): 검색 정확도 및 최종 답변의 정확성 등.
평가 지표 예시:
- 답변의 관련성, hallucination 여부, 정확성, 유해성 등의 항목들이 주로 사용
- 시스템 및 시스템이 수행하는 태스크에 따라, 시스템 디자이너는 어떤 측면을 평가해야 할지를 결정해야함.
예시:
- AI 과외 앱에서는 출력이 연령대에 적합한지, 유해한 답변이 포함되지 않는지 평가가 필요할
여러 한국어 밴치마크
LLM 한국어 사용성 순위(구 평가 기준 적용)
[제가 손수 만든 문제](226033)로 LLM들을 시험을 치르게 해서, 한국어로 사용하기가 얼마나 좋은지를 평가하고 100점 만점으로 환산해서 순위를 매긴 결과입니다. [[T…
wikidocs.net
이건 수능 지문을 통해여 LLM 모델은 한국어에 잘 적응하였는지 평가하는 밴치마크
https://github.com/Marker-Inc-Korea/Korean-SAT-LLM-Leaderboard/blob/main/Korean_README.md
Korean-SAT-LLM-Leaderboard/Korean_README.md at main · Marker-Inc-Korea/Korean-SAT-LLM-Leaderboard
Korean SAT leader board. Contribute to Marker-Inc-Korea/Korean-SAT-LLM-Leaderboard development by creating an account on GitHub.
github.com
참고
초거대언어모델(LLM) 의 성능평가지표 (feat. MMLU, Helloswag)
chatGPT로 부터 시작된 초거대 언어모델 경쟁!! Meta의 LLaMa, Google의 Palm 그리고 이로 부터 파생된 Alpace, Falcon 등 여러 LLM 모델들이 공개되고있는데요! 2023.04.12 - [일등박사의 생각/데이터분석] - GPT를
drfirst.tistory.com
[LLM] LLM 모델의 평가 지표 (LogicKor, TTFT)
서비스에 사용할 모델 선정 시에는 모델 간의 성능 수치를 비교를 진행하여, 높은 성능을 보이는 모델을 최종적으로 선정하게 된다. 작년, 학부 연구생이었을 때는 Vision 쪽 연구(Object Detection)를
velog.io