[Deep learning] 데이터 분석과 1D CNN
CNN이란?
CNN(Convolutional Neural Network, 합성곱 신경망)은 딥러닝에서 이미지나 영상, 음성 등의 데이터 처리에 자주 사용되는 신경망 구조
1. Convolution(합성곱)
입력 이미지에서 특징(엣지, 윤곽 등)을 추출하는 필터(커널)를 사용해 연산을 수행
이 과정을 통해 특징 맵(feature map)을 생성
2. Pooling(풀링)
합성곱 결과에서 중요한 정보만 남기고 차원을 축소
주로 Max Pooling이 쓰이며, 연산량을 줄이고 과적합 방지에도 도움
3. Fully Connected Layer(완전 연결 계층)
앞에서 추출한 특징들을 기반으로 분류(classification) 등의 작업을 수행
이 부분은 일반적인 MLP(다층 퍼셉트론)와 유사하게 작동
CNN(Convolutional Neural Networks)이란 무엇일까?
CNN이 무엇일까?CNN의 주요 컨셉들CNN의 전체적인 네트워크 구조매개변수(parameter)와 Hyper-매개변수(hyper-parameter)CNN이 무엇일까? — 큰 그림 그리기CNN은 Convolutional Neural Networks의 약자로 딥러닝에서
velog.io
여기까지는 다 아는 사실
1D CNN과 2D CNN?
CNN도 차원으로 구분을 한다고?
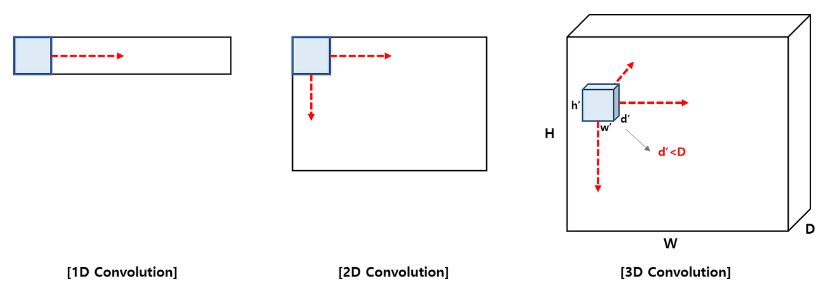
1D Convolution v.s. 2D Convolution v.s. 3D Convolution
합성곱은 이동하는 방향의 수에 따라서 1D, 2D, 3D로 분류할 수 있다.
Convolution Neural Networks (합성곱 신경망)
CNN 이란?CNN은 Convolutional Neural Networks의 줄임말로 인간의 시신경을 모방하여 만든 딥러닝 구조 중 하나입니다. 특히 convolution 연산을 이용하여 이미지의 공간적인 정보를 유지하고, Fully connected Neu
yjjo.tistory.com
1D CNN과 2D CNN은 모두 Convolution 연산을 사용하는 딥러닝 구조지만, 입력 데이터의 차원과 필터가 움직이는 방식이 다르기 때문에 적용하는 데이터 종류와 목적이 다름
1D CNN:
- 데이터 예: ECG 심전도 파형, 음성 신호, 자연어 처리에서의 단어 임베딩 시퀀스
- 사용 예: 텍스트 감성 분류, 음성 인식, 시계열 이상 탐지
시계열 데이터: [0.2, 0.5, 0.1, 0.9, 0.7, ...]
→ 1D 커널이 슬라이딩하면서 각 구간의 패턴을 추출
2D CNN:
- 데이터 예: RGB 이미지 (e.g. [H, W, C])
- 사용 예: 이미지 분류, 객체 검출, 얼굴 인식
이미지 (28x28):
→ 2D 커널이 좌우, 상하로 슬라이딩하면서 공간적 특징 추출
단순하게 딥러닝을 컴퓨터 비전으로 처음 입문하던 필자는 CNN 지칭할 때 단순하게 필터의 차원에 따라 변한다고 생각해서 1D CNN이라는 용어가 있는지 몰랐던 것...
1D CNN과 RNN 비교
| 항목 | 1D CNN | RNN |
| 특징 | 지역적 특징에 민감 | 시간적 순서와 의존성에 민감 |
| 장점 | 병렬 처리 가능, 빠른 학습 | 장기 의존성 모델링 가능 |
| 단점 | 문맥 파악 한계 | 느린 학습 속도, 그래디언트 소실 문제 |
| 활용 예시 | n-gram 패턴 감지, 짧은 시계열 | 언어 모델링, 번역, 긴 문맥 기반 감정 분류 |
1D CNN과 RNN(Recurrent Neural Networks)은 모두 시퀀스 데이터를 처리하는 데 사용되지만, 정보를 처리하고 학습하는 방식에는 중요한 차이점이 있다
- 1D CNN: 주로 짧은 범위 내의 패턴을 빠르게 인식할 때 유용함 → 텍스트에서 n-gram 특성을 추출하거나, 간단한 시계열 패턴을 인식할 때 적합함
- RNN: 시퀀스 내의 데이터가 서로 강하게 연결되어 있고, 전체 시퀀스를 통한 문맥의 흐름이 중요할 때 사용됨 → 자연어 처리에서의 언어 모델링이나 음성 인식에서 긴 의존성을 모델링해야 할 때 효과적임
- 1D CNN의 각 합성곱 커널은 텍스트 내에서 일정 범위의 단어들(예: n-gram)을 처리하여 그 범위 내에서의 정보를 요약하고, 여러 커널을 통해 다양한 크기의 문맥을 포착할 수 있음
N-gram?
https://datasciencebeehive.tistory.com/114
[Machine Learning] N-gram이란 무엇인가? 텍스트 분석의 핵심 이해하기
언어는 인간 커뮤니케이션의 기본 요소입니다. 디지털 시대에 접어들며, 우리는 매일 방대한 양의 텍스트 데이터와 상호작용하게 되었고, 이로 인해 텍스트 분석의 중요성이 급격히 증가했습니
datasciencebeehive.tistory.com
- N-gram은 텍스트 분석에서 문장을 구성하는 단어나 문자의 연속된 조합을 나타내며, 특히 자연어 처리(NLP) 분야에서 문맥적 특성을 포착하기 위해 사용됨 → 문자열에서 연속적으로 발생하는 n개의 아이템(단어, 문자 등)을 하나의 토큰으로 간주함
쉽게 말해 특정 순서로 인접한 n개의 기호 시퀀스이다.
| Unigram | 단어 하나를 하나의 토큰으로 간주 | "I", "like", "to", "play", "football" | 문맥적 의미 없이 각 단어를 독립적으로 처리 | - 계산 비용이 낮음 - 구현이 간단함 |
| Bigram | 연속된 두 단어의 조합을 하나의 토큰으로 간주 | "I like", "like to", "to play", "play football" | 인접한 단어 간의 관계를 포착하여 문맥 반영 | - 문장의 간단한 문맥을 포착할 수 있음 - 문법적 구조가 더 잘 반영됨 |
| Trigram | 연속된 세 단어의 조합을 하나의 토큰으로 간주 | "I like to", "like to play", "to play football" | 더 넓은 범위의 문맥 정보를 포착하여 텍스트의 의미 파악 | - 더 풍부한 문맥 정보 제공 - 연속적인 단어의 관계를 더 잘 포착함 |
CNN을 이용한 데이터 분석 해보기
1. 데이터 전처리
df = pd.read_csv('sample_amazon.csv')
print(df.shape)
print(df.columns)
# 레이블 처리(overall 점수가 3 이상이면 긍정(1), 그렇지 않으면 부정(0)으로 레이블링)
df['label'] = df['overall'].apply(lambda x: 1 if x >= 3 else 0)
df.head()
긍정 데이터 50000개 부정 데이터 50000개 샘플 생성
# 레이블 처리(overall 점수가 3 이상이면 긍정(1), 그렇지 않으면 부정(0)으로 레이블링)
df['label'] = df['overall'].apply(lambda x: 1 if x >= 3 else 0)
df.head()
# 긍정과 부정 레이블이 균일한 분포를 갖도록 샘플링
df_pos = df[df['label'] == 1].sample(50000) # 긍정 리뷰 50000개 샘플링
df_neg = df[df['label'] == 0].sample(50000) # 부정 리뷰 50000개 샘플링
# 데이터 결합
df_concat = pd.concat([df_pos, df_neg])
df_concat.reset_index(drop=True, inplace=True) # 인덱스 초기화
모델 학습을 위한 데이터 분할 및 준비 ( 테스트 2: 학습 8 )
# 훈련 및 테스트 데이터 분할
df_train, df_test = train_test_split(df_concat, test_size=0.2, random_state=42, stratify=df_concat["label"])
# 훈련 데이터 리뷰 텍스트와 라벨 추출
x_train = df_train['reviewText']
y_train = np.array(df_train['label'])
# 테스트 데이터 리뷰 텍스트와 라벨 추출
x_test = df_test['reviewText']
y_test = np.array(df_test['label'])토큰화
tokenizer = Tokenizer(num_words=10000, oov_token='<OOV>')
tokenizer.fit_on_texts(x_train) # 단어 사전 구축
word_index = tokenizer.word_index # 단어 → 인덱스 매핑
토큰화 단계는 텍스트를 개별 단어(토큰)로 분리하는 과정
- 아래 코드에서 'num_words=10000' 파라미터는 단어 사전의 크기를 의미하며, 가장 빈도가 높은 10,000개의 단어만을 사용하여 텍스트를 토큰화하고 인코딩함
- 메모리를 효율적으로 사용하고, 분석 과정에서 중요하지 않은 단어를 제외하여 연산 속도를 효율적으로 향상시킬 수 있음
- oov_token: 어휘 사전에 없는(out-of-vocabulary, OOV) 단어를 처리하기 위한 토큰을 설정함 → 어휘 사전에 없는 단어는 'OOV'로 지정된 토큰으로 대체됨
- 모델이 처음 보는 단어를 처리할 때 오류 없이 처리할 수 있으며, 학습 중에 보지 못한 단어에 대한 일반화 능력을 향상시킬 수 있음
정수 인코딩 (Integer Encoding)
텍스트를 모델이 이해할 수 있는 숫자 시퀀스로 변환
train_sequences = tokenizer.texts_to_sequences(x_train)
test_sequences = tokenizer.texts_to_sequences(x_test)
패딩 (Padding)
- 목적: 모든 시퀀스를 동일한 길이로 맞춤
- 이유: 딥러닝 모델은 고정된 입력 크기를 필요로 함
padded_train_text = pad_sequences(train_sequences, maxlen=1000, padding='post')
padded_test_text = pad_sequences(test_sequences, maxlen=1000, padding='post')- 패딩 방식 비교:
| padding='pre' | 앞에 0을 추가 | RNN에서 뒷부분 정보 중요할 때 사용 |
| padding='post' | 뒤에 0을 추가 | CNN, Transformer처럼 앞부분이 중요할 때 사용 |
텍스트 토큰화 및 Word2Vec 임베딩
1. 문장 단어 토큰화
def tokenize_text(text):
return word_tokenize(text.lower())
# x_train을 토큰화하여 각 문장을 단어의 리스트로 변환
tokenized_x_train = x_train.apply(tokenize_text)
2. Word2Vec 모델 학습
w2v = Word2Vec(sentences=tokenized_x_train, vector_size=100, window=5, min_count=1, workers=4)
최종 텍스트 전처리 함수
# 텍스트 전처리 함수
def tokenize_and_create_embedding_matrix(train_text, test_text, max_words=10000, max_sequence_length=1000):
# 토크나이저 초기화 (OOV 토큰 포함)
tokenizer = Tokenizer(num_words=max_words, oov_token='<OOV>')
# 훈련 데이터에 토크나이저를 적용해 학습
tokenizer.fit_on_texts(train_text)
# 텍스트 데이터를 시퀀스로 변환
train_sequences = tokenizer.texts_to_sequences(train_text)
test_sequences = tokenizer.texts_to_sequences(test_text)
# 시퀀스 패딩 처리 (post 방식 사용)
padded_train_text = pad_sequences(train_sequences, maxlen=max_sequence_length, padding='post')
padded_test_text = pad_sequences(test_sequences, maxlen=max_sequence_length, padding='post')
# 단어 인덱스 맵 생성 및 임베딩 행렬 준비
word_index = tokenizer.word_index
total_words = min(max_words, len(word_index))
embedding_matrix = np.zeros((total_words + 1, 100)) # 임베딩 차원을 100으로 가정
# Word2Vec 모델에서 단어에 해당하는 벡터를 임베딩 행렬에 할당
for word, i in word_index.items():
if i > max_words:
continue
if word in w2v.wv:
embedding_matrix[i] = w2v.wv[word]
# 임베딩 행렬의 크기 출력
print(embedding_matrix.shape)
# 패딩 처리된 텍스트 데이터와 임베딩 행렬, 사용된 총 단어 수, 시퀀스 최대 길이 반환
return padded_train_text, padded_test_text, embedding_matrix, total_words, max_sequence_lengthtrain_text, test_text, embedding_matrix, total_words, max_sequence_length = tokenize_and_create_embedding_matrix(x_train, x_test, max_words=10000, max_sequence_length=1000)
2. 1D CNN 모델 구성 및 학습 과정
1D Convolutional Neural Network 이해하기 (CNN in numpy & keras)
목차 도입 머신러닝 분야에서 예측 모델을 만드는데 가장 많이 사용되는 신경망 모델은 바로 Convolutional Neural Network(CNN)일 것이다. CNN은 특히 이미지 분류에서 높은 정확도를 보이며 많은 예측 모
gmnam.tistory.com
엄청 이해하기 쉽도록 설명된 블로그가 있어서 스크랩
2.1. 임베딩 계층 (Embedding Layer)
- 역할: 단어를 고정된 차원의 밀집 벡터(Dense Vector)로 변환
- 장점: 희소한 One-Hot 벡터보다 공간 효율적이며, 단어 간 의미를 반영
- 파라미터 설명:
| input_dim | 사용되는 단어 사전 크기 (total_words + 1) |
| output_dim | 임베딩 벡터 차원 (예: 100) |
| weights | 사전학습된 Word2Vec, GloVe 등 임베딩 행렬 |
| input_length | 입력 시퀀스 길이 (max_sequence_length) |
| trainable | True면 학습 중 임베딩 벡터가 업데이트됨 |
text_input = Input(shape=(1000,))
embedding_layer = Embedding(input_dim=total_words+1, output_dim=100,
weights=[embedding_matrix], input_length=max_sequence_length,
trainable=True, name='Embedding_text')(text_input)
2.2. 합성곱 계층 (Conv1D Layer)
- 역할: 지역적인 n-gram 패턴(문맥)을 감지
- 중요 파라미터:
| filters=32 | 출력 채널 수 (특성맵 수) |
| kernel_size=3 | 커널(필터)의 크기 |
| activation='relu' | 활성화 함수 |
conv_layer = Conv1D(filters=32, kernel_size=3, activation='relu')(embedding_layer)
멀티채널 합성곱: 다양한 커널 크기를 병렬 적용하여 문맥 다양성 확보
conv1_layer = Conv1D(filters=32, kernel_size=3, activation='relu')(embedding_layer)
conv2_layer = Conv1D(filters=32, kernel_size=4, activation='relu')(embedding_layer)
conv3_layer = Conv1D(filters=32, kernel_size=5, activation='relu')(embedding_layer)
2.3. 풀링 계층 (MaxPooling1D / GlobalMaxPooling1D)
MaxPooling1D
- 기능: 각 구간 내 최댓값을 추출하여 특징 압축
- 파라미터:
| pool_size | 풀링 윈도우 크기 (예: 2) |
| strides | 풀링 이동 간격 (기본은 pool_size) |
| padding | 'valid' (기본) or 'same' |
max_pooling = MaxPooling1D(pool_size=2)(conv_layer)
GlobalMaxPooling1D
- 기능: 전체 시퀀스에서 하나의 최댓값만 추출 → 1D 벡터로 압축
global_max_pooling = GlobalMaxPooling1D()(conv_layer)두 풀링 방식 비교
| MaxPooling1D | GlobalMaxPooling1D | |
| 적용 영역 | 로컬 영역 (윈도우 단위) | 전체 시퀀스 전체 |
| 출력 크기 | 줄어든 시퀀스 형태 | (채널 수,) 형태의 벡터 |
| 적합한 경우 | 구조 유지, 단계별 처리 | 전체 중 가장 강한 특징 추출 시 |
2.4. 완전 연결 계층 (Dense Layer)
일반 구조 (Flatten + Dense)
# MaxPooling1D의 출력을 1차원 벡터로 변환
flattened = Flatten()(max_pooling)
# 최종 출력 계층: sigmoid를 사용한 이진 분류 (0 또는 1 확률)
output_layer = Dense(1, activation='sigmoid')(flattened)
- Flatten()은 2D 데이터를 1D로 변환해 Dense 계층에 전달 가능하게 만듦
- Dense(1, activation='sigmoid')는 이진 분류용 출력층으로, 확률 값 출력 (예: 긍정/부정)
GlobalMaxPooling 사용 시
# 특성맵의 각 채널에서 가장 큰 값 하나만 선택 (전체 시퀀스 중 가장 강한 특징)
output_layer = Dense(1, activation='sigmoid')(global_max_pooling)
- GlobalMaxPooling1D()는 각 필터(채널)별로 전체 시퀀스 중 최댓값만 추출 → 간단한 벡터로 요약
- 복잡한 Flatten 과정을 생략하고 모델의 파라미터 수를 줄이며 과적합 방지 효과
커널 크기별 Conv → Pool → Concatenate 처리
conv_layers = []
# 다양한 커널 크기(3,4,5)를 사용하여 다양한 문맥 범위의 특징을 추출
for kernel_size in [3, 4, 5]:
conv = Conv1D(filters=100, kernel_size=kernel_size, padding='same', activation='relu')(embedding_layer)
# 각 Conv1D 출력에 대해 MaxPooling 적용 → 중요 특징만 추출
conv = MaxPooling1D()(conv)
# 리스트에 추가
conv_layers.append(conv)
# 모든 커널의 출력 결과를 하나로 연결 → 다양한 문맥 정보가 결합된 하나의 텐서 생성
CNN_output_layer = concatenate(conv_layers, axis=-1)
# 완전 연결 계층에 넣기 위해 Flatten 처리
CNN_output_layer = Flatten(name='Flat_CNN')(CNN_output_layer)
# 최종 출력층
output_layer = Dense(1, activation='sigmoid')(CNN_output_layer)
- 커널 크기를 다양하게 설정해 여러 문맥 크기(n-gram 패턴)를 포착
- Conv + Pool 결과를 concatenate()로 연결 → 풍부한 특징 맵 생성
- 이 구조는 텍스트 CNN (Kim Yoon, 2014) 논문에서 자주 사용되는 패턴임
- 이후 Flatten 후 Dense를 통해 이진 분류 수행
2.5 학습 및 최적화
- 모델 컴파일
model = Model(inputs=text_input, outputs=output_layer)
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
- 하이퍼파라미터:
| validation_split | 0.125 → 12.5% 데이터를 검증용으로 사용 |
| epochs | 3~20 정도 → 과적합 방지 위해 적절 조절 |
| batch_size | 512 → 학습 성능 및 메모리 효율 고려 |
| callbacks | EarlyStopping 등으로 과적합 방지 |
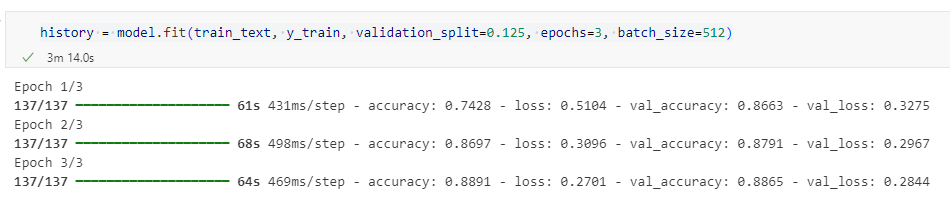
history = model.fit(train_text, y_train, validation_split=0.125,
epochs=3, batch_size=512)
예측 수행
예측 함수 생성
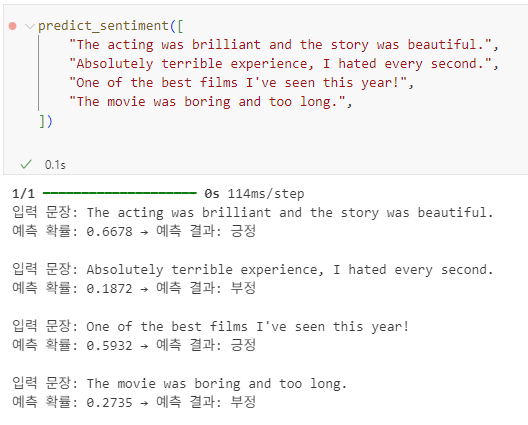
def predict_sentiment(texts):
# 1. 시퀀스로 변환
sequences = tokenizer.texts_to_sequences(texts)
# 2. 패딩 처리
padded = pad_sequences(sequences, maxlen=max_sequence_length, padding='post')
# 3. 예측 수행
predictions = model.predict(padded)
# 4. 결과 출력
for i, pred in enumerate(predictions):
sentiment = "긍정" if pred[0] >= 0.5 else "부정"
print(f"입력 문장: {texts[i]}")
print(f"예측 확률: {pred[0]:.4f} → 예측 결과: {sentiment}\n")
예측
predict_sentiment([
"The acting was brilliant and the story was beautiful.",
"Absolutely terrible experience, I hated every second.",
"One of the best films I've seen this year!",
"The movie was boring and too long.",
])