오늘은 Two-Stage Object Detection 모델중 저번 R-CNN에 이어서 SPPNet과 Fast RCNN에 대해 알아보려고 한다.
[Object Detection] Two-Stage Object Detection – R-CNN
Two-Stage Object Detection 논문들을 하나씩 살펴볼건데 오늘은 R-CNN논문을 다루어 보려고 한다논문 링크 : https://arxiv.org/pdf/1311.2524 Recap) 먼저 Two-Stage Object Detection이란?2024.12.27 - [Computer Vision1/Computer Visi
c0mputermaster.tistory.com
SPPNet / Fast R-CNN
https://arxiv.org/abs/1406.4729
Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
Existing deep convolutional neural networks (CNNs) require a fixed-size (e.g., 224x224) input image. This requirement is "artificial" and may reduce the recognition accuracy for the images or sub-images of an arbitrary size/scale. In this work, we equip th
arxiv.org
https://arxiv.org/abs/1504.08083
Fast R-CNN
This paper proposes a Fast Region-based Convolutional Network method (Fast R-CNN) for object detection. Fast R-CNN builds on previous work to efficiently classify object proposals using deep convolutional networks. Compared to previous work, Fast R-CNN emp
arxiv.org
RCNN의 문제점 3가지

- 매우 느린 속도
- 학습: 약 84시간 소요
- 추론: GPU 사용 시 이미지 1장당 13초, CPU만 사용할 경우 53초
- 원인: 모든 Region Proposal(약 2000개)을 각각 CNN에 넣어 Feature를 추출해야 하기 때문
- Warping 필요
- CNN 입력 크기가 고정(예: 227×227)이므로 ROI를 강제로 크롭 및 리사이즈해야 함
- 비율이 왜곡되어 객체 모양이 달라지고 성능 저하 가능
- End-to-End 학습 불가
- CNN Feature 추출, SVM 분류기, Bounding Box Regression을 각각 따로 학습해야 함
SPPNet (Spatial Pyramid Pooling Network)
핵심 아이디어

- Region Proposal을 CNN에 일일이 넣지 않고, 이미지를 통째로 한 번만 CNN에 통과시킴
- 나온 Feature Map 위에서 Region Proposal을 Projection(좌표 변환)하여 관심 영역을 찾음
- 이후 Spatial Pyramid Pooling을 통해 다양한 크기의 ROI를 고정된 크기 벡터로 변환
Spatial Pyramid Pooling

- 문제: Fully Connected Layer 입력은 고정 크기를 필요로 함
- 해결 방법:
- 임의 크기의 Feature Map에서 ROI를 선택
- ROI를 일정한 bin(셀)으로 나누어 pooling 수행
- 예시: 32×24 영역을 4×4 bin으로 나누면 각 bin은 8×6 크기 → Max Pooling → 16개 값 → 일렬 벡터화
- 멀티스케일 적용: 4×4, 2×2, 1×1 등 다양한 크기로 풀링 → 최종적으로 고정된 크기의 벡터 생성
- 효과: 어떤 크기의 ROI든지 Fully Connected Layer에 입력할 수 있도록 변환 가능
RCNN 대비 SPPNet의 개선점
- 크롭 및 와핑 불필요
- CNN 연산 횟수 대폭 감소
- RCNN: ROI마다 CNN 통과 (2000번 이상)
- SPPNet: 입력 이미지를 CNN에 1번만 통과
- 속도 향상
여전히 남아 있는 한계
- 분류(SVM)와 바운딩 박스 회귀가 여전히 분리되어 있어 End-to-End 학습 불가
Classification은 SVM으로, Bounding Box Regression은 별도의 퍼셉트론으로 따로 학습
CNN Feature와 두 가지 태스크가 연결되지 않아 멀티태스크 학습의 시너지 효과 부족
- 따라서 RCNN 구조에서 CNN 부분만 개선된 모델로 이해 가능
Fast R-CNN
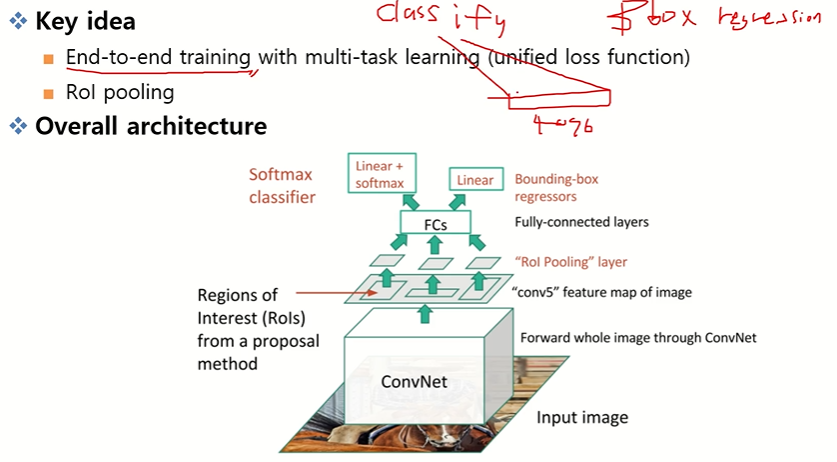
핵심 기여: End-to-End Training 가능
- CNN에서 뽑은 Feature를 공통으로 활용
- Classification(Softmax)과 Bounding Box Regression 모두 뉴럴 네트워크로 연결
- 두 가지 Loss(분류용, 바운딩 박스 회귀용)를 동시에 Backpropagation → 멀티태스크 학습 실현
=> Spatial Pyramid Pooling 대신 ROI polling을 사용한다.

- SPP-net과 Fast R-CNN 모두 R-CNN보다 빠르게 동작
Region Proposal(ROI) Projection과 Pooling

- SPPNet의 SPP 대신 단순화된 ROI Pooling 사용
- SPP가 다양한 크기의 Feature map 이라면 ROI Pooling은 ROI 크기와 상관없이 고정된 7×7×채널 하나의 크기로 변환

*Pooling 할때 커널 사이즈와 스트라이드를 적절하게 조절한다면 어떤 크기라도 7x7 사이즈의 아웃풋을 얻을 수 있다.
학습

- Classification Loss: Cross-Entropy Loss (Log Loss)
- Bounding Box Regression Loss: Smooth L1 Loss
- 0 근처에서는 L2 Loss 성질 → 작은 오차에 민감
- 큰 오차 영역에서는 L1 Loss 성질 → 안정적인 학습
- 두 Loss를 합산하여 최종 Loss로 설정 → End-to-End 학습 가능
정리하자면
1. 입력: 원본 이미지 1장
2. 이미지를 CNN에 한 번만 통과시켜 Feature Map 생성
(RCNN처럼 Region Proposal마다 CNN을 돌리지 않음 → 큰 속도 향상)
3. Region Proposal (ROI 생성) => 추출된 ROI 좌표를 Feature Map 좌표계로 Projection
4. ROI Pooling = ROI 영역을 일정한 grid로 나누고, 각 grid 내에서 Max Pooling 수행 (7×7×채널)
5. Fully Connected Layer
- ROI Pooling 결과를 일렬 벡터로 펼쳐 4096차원 등 고정된 크기로 입력
- Fully Connected Layer 통과 후 두 가지 분기로 나뉨
6. 두 가지 출력 (멀티태스크 학습)
- Classification
- Softmax 분류기로 객체의 클래스 예측
- Loss: Cross-Entropy Loss
- Bounding Box Regression
- 객체 위치 보정을 위한 좌표 4개(x, y, w, h) 예측
- Loss: Smooth L1 Loss
최종 Loss = Classification Loss + Bounding Box Regression Loss
그렇게 속도가 빨라졌지만 그렇게 학습하고 추론 속도가 2.3초인데 Selective search가 2초 정도 걸려서 이걸 해결하고자 했다.

=> Faster RCNN에서 이어서
2025.08.06 - [분류 전체보기] - [Object Detection] Faster R-CNN
[Object Detection] Faster R-CNN
이번에는 Selective Search 시간이 너무 오래 걸리는 Fast RCNN을 NN으로 바꿔서 속도를 줄여보자는 아이디어에서 나온 Faster R-CNN에 대해 리뷰하여 볼것이다. 2025.07.17 - [분류 전체보기] - [Object Detection] SP
c0mputermaster.tistory.com
'Computer Vision > Paper reviews' 카테고리의 다른 글
| [ILSVRC 논문 정리해 보기] VGGNet, GoogleNet, ResNet (0) | 2025.09.05 |
|---|---|
| [Object Detection] Faster R-CNN (0) | 2025.08.06 |
| [Object Detection] Two-Stage Object Detection – R-CNN (0) | 2025.07.10 |
| [ILSVRC 논문 정리해 보기] AlexNet (ImageNet Classification with Deep Convolutional Neural Networks) (0) | 2025.05.07 |
| [논문 리뷰] ImageNet Classification with Deep ConvolutionalNeural Networks (AlexNet) (0) | 2025.02.02 |