
이 리뷰는 오직 학습과 참고 목적으로 작성되었으며, 해당 논문을 통해 얻은 통찰력과 지식을 공유하고자 하는 의도에서 작성된 것입니다. 본 리뷰를 통해 수익을 창출하는 것이 아니라, 제 학습과 연구를 위한 공부의 일환으로 작성되었음을 미리 알려드립니다.
Object detection의 역사를 전반적으로 이해할 수 있는 2023년에 출간된 Survey 논문에 대한 리뷰인데 전체적인 흐름을 이해하는데 도움이 될 것 같아 리뷰하였다. 19년에 출간된 같은 이름의 논문도 있는데 가장 최근의 논문으로 리뷰하였다.
Z. Zou, K. Chen, Z. Shi, Y. Guo and J. Ye, "Object Detection in 20 Years: A Survey," in Proceedings of the IEEE, vol. 111, no. 3, pp. 257-276, March 2023, doi: 10.1109/JPROC.2023.3238524.
keywords: {Object detection;Detectors;Computer vision;Feature extraction;Deep learning;Convolutional neural networks;Computer vision;convolutional neural networks (CNNs);deep learning;object detection;technical evolution},
ABSTRACT
이 글은 객체 탐지(Object Detection) 분야의 기술 발전을 1990년대부터 2022년까지 25년에 걸쳐 리뷰한 것입니다. 객체 탐지는 컴퓨터 비전에서 중요한 문제로, 딥 러닝의 발전과 함께 빠르게 진화해왔습니다. 이 기사에서는 역사적인 탐지 기술, 데이터셋, 평가 지표, 시스템 구성 요소, 속도 향상 기법, 그리고 최신 탐지 방법 등 다양한 주제를 다룹니다.
I. INTRODUCTION
객체 탐지(Object detection)는 디지털 이미지에서 인간, 동물, 자동차 등 특정 클래스의 시각적 객체 인스턴스를 탐지하는 컴퓨터 비전의 중요한 작업입니다. 객체 탐지의 주요 목표는 컴퓨터 비전 애플리케이션에 필요한 가장 기본적인 정보를 제공하는 계산 모델과 기법을 개발하는 것입니다: 어떤 객체가 어디에 있는지입니다. 객체 탐지의 가장 중요한 지표는 정확도(accuracy, 분류 정확도 및 위치 정확도 포함)와 속도입니다.
객체 탐지는 인스턴스 분할(instance segmentation), 이미지 캡셔닝(image captioning), 객체 추적(object tracking)과 같은 다른 컴퓨터 비전 작업의 기초가 됩니다. 최근 몇 년 동안, 딥 러닝(deep learning) 기법의 빠른 발전은 객체 탐지의 발전을 크게 촉진시켰고, 이로 인해 눈에 띄는 돌파구가 이루어졌으며 객체 탐지는 전례 없는 주목을 받는 연구 분야가 되었습니다. 현재 객체 탐지는 자율 주행(autonomous driving), 로봇 비전(robot vision), 비디오 감시(video surveillance)와 같은 많은 실제 응용 분야에서 널리 사용되고 있습니다.
객체 탐지 작업은 각기 다른 목표와 제약을 가지므로 그 어려움은 상이할 수 있습니다. 다른 컴퓨터 비전 작업에서 공통적으로 마주치는 문제들(예: 다양한 시점, 조명, 클래스 내 변이) 외에도, 객체 탐지에서는 다음과 같은 특정한 어려움들이 존재합니다: 객체 회전과 크기 변화(예: 작은 객체), 정확한 객체 위치 추정, 밀집된 객체 및 가려진 객체 탐지, 탐지 속도 향상 등입니다.
이 논문은 객체 탐지 기술을 여러 관점에서 완전히 이해할 수 있도록 돕고, 그 발전 과정을 강조하는 데 중점을 둡니다. 주요 특징은 세 가지입니다: 기술 발전을 기반으로 한 종합적인 리뷰, 주요 기술과 최신 상태에 대한 심층적인 탐구, 그리고 탐지 속도 향상 기법에 대한 종합적인 분석입니다.
II. OBJECT DETECTION IN 20 YEARS
이 섹션에서는 객체 탐지의 역사를 여러 관점에서 리뷰합니다. 여기에는 주요 탐지기법(milestone detectors), 데이터셋, 평가 지표(metrics), 그리고 핵심 기술들의 발전이 포함됩니다.
A. Road Map of Object Detection
지난 20년 간 객체 탐지의 발전은 일반적으로 두 가지 역사적 시기로 나누어집니다: “전통적인 객체 탐지 시기 (2014년 이전)”와 “딥 러닝 기반 탐지 시기 (2014년 이후)”
1. Milestones: Traditional Detectors
오늘날의 객체 탐지 기술을 딥 러닝에 의해 촉발된 혁명으로 본다면, 1990년대에는 초기 컴퓨터 비전의 독창적인 설계와 장기적인 관점을 볼 수 있습니다. 초기의 대부분의 객체 탐지 알고리즘은 수작업으로 만든 특성(feature)을 기반으로 구축되었습니다. 당시에는 효과적인 이미지 표현 방법이 부족했기 때문에, 사람들은 복잡한 특징 표현과 다양한 속도 향상 기법들을 설계해야 했습니다.
- Viola-Jones Detectors: 2001년, Viola와 Jones는 인간 얼굴을 실시간으로 탐지하는 데 성공했습니다. 이 탐지기는 어떤 제약(예: 피부 색상 분할)도 없이 작동했으며, 700MHz Pentium III CPU에서 실행될 때 당시 다른 알고리즘들보다 수십 배 또는 수백 배 더 빠른 성능을 보였습니다. VJ 탐지기는 가장 직관적인 방식인 슬라이딩 윈도우(sliding windows)를 사용하여 이미지 내의 모든 가능한 위치와 크기를 통해 인간 얼굴을 찾습니다. 이 과정은 매우 단순해 보이지만, 당시 컴퓨터의 계산 능력을 넘는 복잡한 연산을 요구했습니다. VJ 탐지기는 "적분 이미지(integral image)", "특징 선택(feature selection)", "탐지 캐스케이드(detection cascades)"라는 세 가지 중요한 기법을 결합하여 탐지 속도를 획기적으로 개선했습니다
- HOG Detector: 2005년, Dalal과 Triggs 는 방향성 히스토그램(HOG) 특징 기술자를 제안했습니다. HOG는 당시 스케일 불변 특징 변환(SIFT)과 형태 맥락(shape contexts) 의 중요한 개선으로 볼 수 있습니다. HOG는 변환, 스케일, 조명 등을 포함한 특징 불변성(feature invariance)과 비선형성(nonlinearity) 간의 균형을 맞추기 위해 설계되었습니다.
- Deformable Part-Based Model (DPM): DPM은 VOC-07, -08, -09 탐지 챌린지에서 우승한 전통적인 객체 탐지 방법의 전형적인 예입니다. DPM은 2008년 Felzenszwalb et al.에 의해 HOG 탐지기의 확장으로 제안되었습니다. DPM은 “분할하여 정복하라(divide and conquer)”는 탐지 철학을 따르며, 훈련 과정은 객체를 분해하는 적합한 방법을 학습하는 것으로 간주하고, 추론 과정은 다양한 객체 부분에서의 탐지를 집합적으로 수행하는 것으로 볼 수 있습니다. 예를 들어, "자동차"를 탐지하는 문제는 자동차의 창문, 본체, 바퀴를 탐지하는 문제로 분해할 수 있습니다.
[10] P. Viola, M. Jones, “단순 특징들의 부스팅 계단을 이용한 빠른 객체 탐지,” Proc. IEEE Comput. Soc. Conf. Comput. Vis. Pattern Recognit. (CVPR), Dec. 2001, pp. 1–9.
[12] N. Dalal, B. Triggs, “사람 탐지를 위한 방향성 히스토그램,” Proc. IEEE Comput. Soc. Conf. Comput. Vis. Pattern Recognit., vol. 1, no. 1, Jun. 2005, pp. 886–893.
[13] P. Felzenszwalb, D. McAllester, D. Ramanan, “다중 규모로 훈련된 분류 가능한 부위 기반 모델,” Proc. IEEE Conf. Comput. Vis. Pattern Recognit., Jun. 2008, pp. 1–8.
[14] P. F. Felzenszwalb, R. B. Girshick, D. McAllester, “변형 가능한 부위 모델을 이용한 객체 탐지의 계단식 접근,” Proc. IEEE Comput. Soc. Conf. Comput. Vis. Pattern Recognit., Jun. 2010, pp. 2241–2248.
오늘날의 객체 탐지기는 DPM의 탐지 정확도를 훨씬 능가하지만, 그 중 많은 탐지기들이 여전히 DPM의 귀중한 통찰력, 예를 들어 혼합 모델, 어려운 부정 예제 학습(HNM), 바운딩 박스 회귀, 그리고 컨텍스트 프라이밍 등의 영향을 깊게 받고 있습니다. 2010년, Felzenszwalb와 Girshick은 PASCAL VOC로부터 "평생 공로상(lifetime achievement)"을 수여받았습니다.
2. Milestones: CNN-Based Two-Stage Detectors
수작업 특징(feature)의 성능이 포화 상태에 이르면서, 객체 탐지 연구는 2010년 이후 한동안 정체기에 접어들었습니다. 2012년, 세계는 컨볼루션 신경망(CNNs)의 부활을 목격했습니다. 깊은 컨볼루션 네트워크는 이미지의 강건하고 고수준의 특징 표현을 학습할 수 있기 때문에, 자연스럽게 떠오르는 질문은: 이를 객체 탐지에 도입할 수 있을까? Girshick et al.은 2014년에 Regions with CNN features (RCNN)를 제안하며 이 정체기를 깨뜨렸습니다. 그 이후로 객체 탐지는 전례 없는 속도로 발전하기 시작했습니다. 딥 러닝 시대에는 두 가지 종류의 탐지기가 있습니다: “두 단계 탐지기(two-stage detectors)”와 “한 단계 탐지기(one-stage detectors)”로, 전자는 탐지를 "거칠게부터 세밀하게(coarse-to-fine)" 처리하는 방식으로, 후자는 "한 번의 단계로 완성(complete in one step)"하는 방식으로 구성됩니다.
A. Krizhevsky, I. Sutskever, G. E. Hinton, “심층 합성곱 신경망을 이용한 ImageNet 분류,” Proc. Adv. Neural Inf. Process. Syst., 2012, pp. 1097–1105.
R. Girshick, J. Donahue, T. Darrell, J. Malik, “정확한 객체 탐지 및 의미론적 분할을 위한 풍부한 특징 계층,” Proc. IEEE Conf. Comput. Vis. Pattern Recognit., Jun. 2014, pp. 580–587.
R. Girshick, J. Donahue, T. Darrell, J. Malik, “영역 기반 합성곱 신경망을 이용한 정확한 객체 탐지 및 분할,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 38, no. 1, pp. 142–158, Jan. 2016.
- RCNN: RCNN의 아이디어는 간단합니다. 먼저, 선택적 검색(selective search)를 통해 객체 제안(object proposals, 객체 후보 상자)을 추출합니다. 그런 다음 각 제안은 고정된 크기의 이미지로 리사이즈되어 ImageNet에서 미리 학습된 CNN 모델(예: AlexNet)에 입력되어 특징을 추출합니다. 마지막으로, 선형 SVM 분류기를 사용하여 각 영역에서 객체의 존재 여부를 예측하고 객체 범주를 인식합니다. RCNN은 VOC07에서 큰 성능 향상을 이루었으며, 평균 정밀도(mAP)가 33.7% (DPM-v5 )에서 58.5%로 크게 향상되었습니다. RCNN은 큰 발전을 이루었지만, 그 단점도 분명합니다. 많은 겹치는 제안들(한 이미지에서 2000개 이상의 상자)에 대해 중복된 특징 계산을 수행하기 때문에 탐지 속도가 매우 느립니다(GPU에서 이미지당 14초 소요). 같은 해, SPPNet이 제안되어 이 문제를 해결했습니다.
- SPPNet: 2014년, He et al.은 공간 피라미드 풀링 네트워크(SPPNet)를 제안했습니다. 이전의 CNN 모델들은 고정 크기 입력을 요구했습니다. 예를 들어, AlexNet의 경우 224 × 224 크기의 이미지를 사용합니다. SPPNet의 주요 기여는 공간 피라미드 풀링(SPP) 계층을 도입하여, 이미지나 관심 영역의 크기에 관계없이 CNN이 고정 길이 표현을 생성할 수 있도록 하는 것입니다. SPPNet을 객체 탐지에 사용할 때, 특징 맵은 전체 이미지를 한 번만 계산하면 되며, 그 후 임의의 영역에 대해 고정 길이 표현을 생성하여 탐지기를 학습할 수 있습니다. 이렇게 하면 컨볼루션 특징을 반복적으로 계산할 필요가 없습니다. SPPNet은 R-CNN보다 20배 이상 빠르면서도 탐지 정확도를 희생하지 않았습니다(VOC07 mAP = 59.2%). SPPNet은 탐지 속도를 크게 향상시켰지만, 여전히 몇 가지 단점이 있습니다. 첫째, 훈련은 여전히 다단계로 이루어져 있습니다. 둘째, SPPNet은 완전하게 연결된 층에서만 학습하고 이전의 모든 층은 단순히 무시하는 방식으로 훈련이 이루어졌습니다. 그 다음 해, Fast RCNN 이 제안되어 이러한 문제들을 해결했습니다.
[45] J. R. R. Uijlings, K. E. A. van de Sande, T. Gevers, and A. W. M. Smeulders, "객체 인식을 위한 선택적 검색," 국제 컴퓨터 비전 저널, 제 104권, 제 2호, pp. 154–171, 2013년 4월.
[35] A. Krizhevsky, I. Sutskever, G. E. Hinton, “심층 합성곱 신경망을 이용한 ImageNet 분류,” Proc. Adv. Neural Inf. Process. Syst., 2012, pp. 1097–1105.
[17] K. He, X. Zhang, S. Ren, J. Sun, “시각적 인식을 위한 심층 합성곱 신경망에서의 공간 피라미드 풀링,” Proc. ECCV. Cham, Switzerland: Springer, 2014, pp. 346–361.
- Fast RCNN: 2015년, Girshick은 R-CNN과 SPPNet을 개선한 Fast RCNN 탐지기를 제안했습니다. Fast RCNN은 동일한 네트워크 구성에서 탐지기와 바운딩 박스 회귀기를 동시에 훈련할 수 있게 해줍니다. VOC07 데이터셋에서, Fast RCNN은 mAP를 58.5% (RCNN)에서 70.0%로 증가시키며 R-CNN보다 탐지 속도는 200배 이상 빨라졌습니다. Fast RCNN은 R-CNN과 SPPNet의 장점을 성공적으로 통합했지만, 여전히 제안 탐지 단계에서 속도 제한이 있었습니다. 그 후, 자연스럽게 “CNN 모델로 객체 제안을 생성할 수 있을까?”라는 질문이 떠오르게 되었고, 그 답은 나중에 Faster R-CNN 이었습니다.
- Faster RCNN: 2015년, Ren et al.은 Fast RCNN 직후에 Faster RCNN 탐지기를 제안했습니다. Faster RCNN은 첫 번째 실시간 근접 딥러닝 탐지기입니다 (COCO mAP@.5 = 42.7%, VOC07 mAP = 73.2%, ZF-Net으로 17fps). Faster RCNN의 주요 기여는 거의 비용이 들지 않는 영역 제안(region proposal)을 가능하게 하는 영역 제안 네트워크(RPN)의 도입입니다. R-CNN에서 Faster RCNN으로 넘어가면서, 객체 탐지 시스템의 개별 블록들, 예를 들어 제안 탐지, 특징 추출, 바운딩 박스 회귀 등이 점차적으로 통합되어 단일한 엔드 투 엔드 학습 프레임워크로 발전했습니다. Faster RCNN은 Fast RCNN의 속도 병목 현상을 개선 했지만, 이후 탐지 단계에서 여전히 계산 중복이 있었습니다. 그 후 RFCN과 Light head RCNN등 다양한 개선이 제안되었습니다
- Feature Pyramid Networks (FPNs): 2017년, Lin et al.은 FPN을 제안했습니다. FPN 이전에는 대부분의 딥러닝 기반 탐지기들이 네트워크의 상위 계층에서만 탐지를 수행했습니다. CNN의 더 깊은 계층에서의 특징은 범주 인식에는 유리하지만, 객체를 로컬라이징하는 데는 도움이 되지 않습니다. 이를 해결하기 위해, FPN에서는 모든 스케일에서 고수준의 의미를 구축할 수 있도록 위에서 아래로(top-down) 아키텍처와 측면 연결을 개발했습니다. CNN은 자연스럽게 피라미드 형태의 특징을 형성하므로, FPN은 다양한 스케일의 객체를 탐지하는 데 큰 진전을 이루었습니다. 기본 Faster R-CNN 시스템에 FPN을 사용하면, COCO 데이터셋에서 최신 모델 탐지 결과를 얻을 수 있습니다 (COCO mAP@.5 = 59.1%). FPN은 이제 많은 최신 탐지기들의 기본 구성 요소가 되었습니다.
[18] R. Girshick, “Fast R-CNN,” Proc. IEEE Int. Conf. Comput. Vis. (ICCV), Dec. 2015, pp. 1440–1448.
[19] S. Ren, K. He, R. Girshick, J. Sun, “Faster R-CNN: 지역 제안 네트워크를 이용한 실시간 객체 탐지,” Proc. Adv. Neural Inf. Process. Syst., 2015, pp. 91–99.
[24] T.-Y. Lin, P. Dollar, R. Girshick, K. He, B. Hariharan, S. Belongie, “객체 탐지를 위한 특징 피라미드 네트워크,” Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Jul. 2017, pp. 2117–2125.
R-CNN 계열의 프로세스

3. Milestones: CNN-Based One-Stage Detectors
두 단계 탐지기는 "거칠게부터 세밀하게" 처리하는 방식으로, 첫 단계에서 재현 능력을 개선하고, 두 번째 단계에서는 탐지 기반으로 로컬라이제이션을 정밀하게 다듬으며 정보 구분 능력을 강조합니다. 그러나 속도가 느리고 복잡도가 커서 실제 엔지니어링에서는 잘 사용되지 않습니다. 반면, 한 단계 탐지기는 한 번의 추론으로 모든 객체를 탐지할 수 있어 실시간 처리와 모바일 기기에서의 배포에 유리하지만, 밀집된 작은 객체를 탐지할 때 성능이 떨어집니다.
- You Only Look Once (YOLO): YOLO는 2015년 Joseph et al.에 의해 제안되었습니다. YOLO는 딥러닝 시대의 첫 번째 한 단계 탐지기입니다. YOLO는 매우 빠릅니다: 빠른 버전의 YOLO는 VOC07에서 mAP = 52.7%를 기록하며 155 fps로 동작하고, 향상된 버전은 VOC07에서 mAP = 63.4%를 기록하며 45 fps로 동작합니다. YOLO는 두 단계 탐지기들과 전혀 다른 패러다임을 따릅니다: 전체 이미지를 대상으로 단일 신경망을 적용하는 방식입니다. 이 신경망은 이미지를 여러 영역으로 나누고 각 영역에 대해 바운딩 박스와 확률을 동시에 예측합니다. 탐지 속도의 큰 향상에도 불구하고, YOLO는 특히 작은 객체에 대한 로컬라이제이션 정확도가 두 단계 탐지기들보다 떨어지는 문제를 겪습니다. YOLO의 후속 버전들과 나중에 제안된 SSD는 이 문제에 더 많은 주의를 기울였습니다. 최근 YOLOv7이 YOLOv4 팀에 의해 제안되었으며, 동적 라벨 할당과 모델 구조 재매개화와 같은 최적화된 구조를 도입하여 속도와 정확도 면에서 대부분의 기존 객체 탐지기들을 능가합니다 (5fps에서 160fps 사이).
- Single-Shot Multibox Detector (SSD): SSD는 2015년 Liu et al.에 의해 제안되었습니다. SSD의 주요 기여는 다중 참조 및 다중 해상도 탐지 기법을 도입한 것입니다 (이 기법은 II-C1 섹션에서 설명됨), 이 기법은 특히 작은 객체의 탐지 정확도를 크게 향상시킵니다. SSD는 탐지 속도와 정확도 모두에서 장점이 있습니다 (COCO mAP@.5 = 46.5%, 빠른 버전은 59 fps로 동작). SSD와 이전 탐지기들 간의 주요 차이점은 SSD가 네트워크의 다른 층에서 다양한 크기의 객체를 탐지하는 반면, 이전 탐지기들은 상위 층에서만 탐지를 수행했다는 점입니다.
- RetinaNet: 높은 속도와 단순성에도 불구하고, 한 단계 탐지기들은 수년 동안 두 단계 탐지기의 정확도에 뒤처졌습니다. Lin et al.는 그 이유를 탐구하고 2017년에 RetinaNet을 제안했습니다. 그들은 밀집된 탐지기의 훈련 중 겪는 극단적인 전경-배경 클래스 불균형이 주요 원인임을 발견했습니다. 이를 해결하기 위해, RetinaNet에서는 "초점 손실(focal loss)"이라는 새로운 손실 함수를 도입하여 표준 교차 엔트로피 손실을 재구성했습니다. 이를 통해 탐지기가 훈련 중 어려운 예제와 잘못 분류된 예제에 더 집중하도록 했습니다. 초점 손실은 한 단계 탐지기들이 매우 높은 탐지 속도를 유지하면서 두 단계 탐지기들과 비슷한 정확도를 달성할 수 있게 해줍니다 (COCO mAP@.5 = 59.1%).
[20] J. Redmon, S. Divvala, R. Girshick, A. Farhadi, “YOLO: 통합된 실시간 객체 탐지,” Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2016, pp. 779–788.
[23] W. Liu et al., “SSD: 싱글 샷 멀티박스 탐지기,” Proc. ECCV. Cham, Switzerland: Springer, 2016, pp. 21–37.
[25] T.-Y. Lin, P. Goyal, R. Girshick, K. He, P. Dollar, “밀집 객체 탐지를 위한 포컬 손실,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 42, no. 2, pp. 318–327, Feb. 2020.
- CornerNet: 이전의 방법들은 주로 앵커 박스를 사용하여 분류 및 회귀 참조를 제공했습니다. 객체는 수, 위치, 크기, 비율 등에서 자주 변화를 보입니다. 이들은 고성능을 달성하기 위해 더 많은 참조 박스를 설정해야 했지만, 그로 인해 네트워크는 범주 불균형, 많은 하이퍼파라미터 설계 및 긴 수렴 시간 등의 문제를 겪게 됩니다. 문제 해결을 위해 Law와 Deng은 기존의 탐지 패러다임을 버리고 이를 키포인트(박스의 모서리) 예측 문제로 보고했습니다. 키포인트를 얻은 후, 추가 임베딩 정보를 사용하여 모서리 점들을 분리하고 다시 그룹화하여 바운딩 박스를 형성합니다. CornerNet은 그 당시 대부분의 한 단계 탐지기를 능가했습니다 (COCO mAP@.5 = 57.8%).
- CenterNet: Zhou et al.은 2019년에 CenterNet을 제안했습니다. 이 모델은 키포인트 기반 탐지 패러다임을 따르지만, CornerNet ExtremeNet 등에서 사용된 그룹 기반 키포인트 할당 및 NMS와 같은 비용이 큰 후처리 과정들을 제거하여 완전한 엔드-투-엔드 탐지 네트워크를 구현합니다. CenterNet은 객체를 하나의 포인트(객체의 중심)로 보고, 그 참조 중심점을 기반으로 객체의 크기, 방향, 위치 및 자세와 같은 모든 속성을 회귀합니다. 이 모델은 간단하고 우아하며, 3D 객체 탐지, 인간 자세 추정, 광학 흐름 학습, 깊이 추정 등 여러 작업을 단일 프레임워크로 통합할 수 있습니다. 이렇게 간결한 탐지 개념을 사용하면서도 CenterNet은 비교 가능한 탐지 결과를 얻을 수 있습니다 (COCO mAP@.5 = 61.1%).
- DETR: 최근 몇 년 간, Transformer는 딥러닝 전체 분야, 특히 컴퓨터 비전 분야에 깊은 영향을 미쳤습니다. Transformer는 전통적인 합성곱 연산을 버리고 주의(attention)만으로 계산을 수행하여 CNN의 한계를 극복하고 글로벌 크기의 수용 영역을 얻습니다. 2020년, Carion et al.은 DETR을 제안했으며, 객체 탐지를 집합 예측 문제로 보고 Transformer를 활용한 엔드-투-엔드 탐지 네트워크를 제안했습니다. 이로써 객체 탐지는 더 이상 앵커 박스나 앵커 포인트 없이도 이루어질 수 있는 새로운 시대에 접어들었습니다. 후에 Zhu et al.은 작은 객체 탐지에서 DETR의 긴 수렴 시간과 제한된 성능 문제를 해결하기 위해 Deformable DETR을 제안했습니다. 이 모델은 MSCOCO 데이터셋에서 최첨단 성능을 기록하며 (COCO mAP@.5 = 71.9%) 성능을 개선했습니다.
[26] H. Law, J. Deng, “CornerNet: 객체를 쌍으로 된 키포인트로 탐지,” Proc. Eur. Conf. Comput. Vis. (ECCV), Sep. 2018, pp. 734–750.
[40] X. Zhou, D. Wang, P. Krähenbühl, “객체를 포인트로 다루기,” 2019, arXiv:1904.07850.
[26] H. Law, J. Deng, “CornerNet: 객체를 쌍으로 된 키포인트로 탐지,” Proc. Eur. Conf. Comput. Vis. (ECCV), Sep. 2018, pp. 734–750.
[53] X. Zhou, J. Zhuo, and P. Krahenbuhl, "극단 및 중심 점을 그룹화하여 바텀업 객체 탐지," IEEE/CVF 컴퓨터 비전 및 패턴 인식 회의(CVPR), 2019년 6월, pp. 850–859.
[28] N. Carion, F. Massa, G. Synnaeve, N. Usunier, A. Kirillov, S. Zagoruyko, “변환기를 이용한 끝에서 끝까지의 객체 탐지,” Proc. Eur. Conf. Comput. Vis., Cham, Switzerland: Springer, 2020, pp. 213–229.
[43] X. Zhu, W. Su, L. Lu, B. Li, X. Wang, and J. Dai, "변형 가능한 DETR: 엔드 투 엔드 객체 탐지를 위한 변형 가능한 트랜스포머," 2020, arXiv:2010.04159.
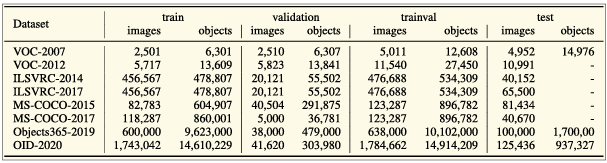
B. Object Detection Datasets and Metrics
- PASCAL VOC:
- VOC2007와 VOC2012 버전이 주로 사용됨.
- VOC07은 5천 개 학습 이미지와 12,000개의 객체 주석을 포함하며, VOC12는 11,000개 학습 이미지와 27,000개의 객체 주석을 포함.
- 20개 객체 클래스를 주석으로 제공 (예: 사람, 고양이, 자전거 등).
- MS-COCO:
- 객체 탐지에서 가장 도전적인 데이터셋 중 하나.
- MS-COCO-17은 164,000개의 이미지와 897,000개의 객체 주석을 포함하며 80개 객체 카테고리로 구성됨.
- 바운딩 박스 외에도 객체별 세그멘테이션 정보 제공.
- 작은 객체와 밀집된 객체도 포함되어 있음.
- Open Images:
- Open Images Detection 챌린지는 1910,000개의 이미지와 1544,000개의 주석된 바운딩 박스를 제공하며 600개의 객체 카테고리를 다룸.
- 두 가지 작업: 표준 객체 탐지와 시각적 관계 탐지.
- ILSVRC (ImageNet Large Scale Visual Recognition Challenge):
- 2010~2017년 동안 매년 개최된 대회.
- ILSVRC 탐지 데이터셋은 200개 객체 클래스를 포함하고 있으며, VOC보다 훨씬 많은 이미지와 객체 인스턴스를 제공.
C. 객체 탐지의 기술적 발전 (Technical Evolution in Object Detection)
이 섹션에서는 탐지 시스템의 중요한 구성 요소와 그 기술적 발전을 소개합니다. 먼저 모델 설계에서의 다중 스케일과 맥락 프라이밍을 설명하고, 그 다음으로 샘플 선택 전략과 훈련 과정에서의 손실 함수 설계, 마지막으로 추론에서의 비최대 억제(Non-Maximum Suppression)에 대해 설명합니다. 차트와 텍스트에 표시된 타임스탬프는 논문 발표 시점을 기준으로 제공됩니다. 그림에서 보여지는 발전 순서는 주로 독자가 이해하는 데 도움이 되도록 제공되며, 시간적으로 중첩되는 부분이 있을 수 있습니다.
- 다중 스케일 탐지의 기술적 발전 (Technical Evolution of Multiscale Detection): "다른 크기" (different sizes)와 "다른 종횡비" (different aspect ratios)를 가진 객체를 다중 스케일로 탐지하는 것은 객체 탐지의 주요 기술적 도전 과제 중 하나입니다. 지난 20년 동안 다중 스케일 탐지는 여러 역사적인 단계를 거쳐 발전했습니다
특징 피라미드 + 슬라이딩 윈도우 (Feature Pyramids + Sliding Windows): VJ 탐지기 (VJ detector) 이후, 연구자들은 "특징 피라미드 + 슬라이딩 윈도우"라는 직관적인 탐지 방법에 더 많은 관심을 기울이기 시작했습니다. 2004년부터는 HOG 탐지기 (HOG detector), DPM 등 여러 중요한 탐지기들이 이 패러다임을 바탕으로 개발되었습니다. 이들은 고정 크기의 탐지 윈도우를 이미지 위로 미끄러뜨리며 탐지를 수행하며, "다양한 종횡비" (different aspect ratios)에 대해서는 큰 관심을 두지 않았습니다. 더 복잡한 모양을 가진 객체를 탐지하기 위해 Girshick et al.은 특징 피라미드 외의 더 나은 해결책을 모색하기 시작했습니다. 당시의 해결책 중 하나는 "혼합 모델" (mixture model) 이었습니다. 즉, 서로 다른 종횡비를 가진 객체들을 위한 여러 탐지기를 훈련시키는 방법이었습니다. 이 외에도 예제 기반 탐지 (exemplar-based detection)는 각 객체 인스턴스 (exemplar)에 대해 개별 모델을 훈련시키는 또 다른 해결책을 제공했습니다.
[15] P. F. Felzenszwalb, R. B. Girshick, D. McAllester, D. Ramanan, “분류 가능한 부위 기반 모델을 이용한 객체 탐지,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 32, no. 9, pp. 1627–1645, Sep. 2010. 혼합모델
[32] T. Malisiewicz, A. Gupta, A. A. Efros, “객체 탐지 및 그 이상을 위한 예시-SVM의 앙상블,” Proc. Int. Conf. Comput. Vis., Nov. 2011, pp. 89–96. 예제 기반 탐지
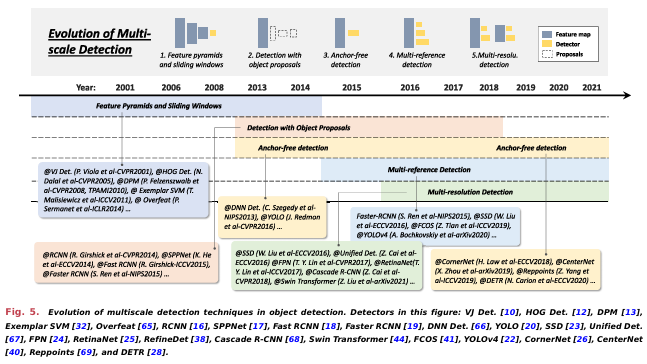
Detection With Object Proposals: 객체 제안(Object proposals)은 객체를 포함할 가능성이 있는 클래스에 구애받지 않는 참조 상자들의 집합을 의미합니다. 객체 제안을 사용한 탐지는 이미지 전역에서의 소모적인 슬라이딩 윈도우 검색을 피할 수 있도록 도와줍니다. 이 주제에 대한 포괄적인 리뷰는 아래 논문들을 참고하시기 바랍니다. 초기 객체 제안 탐지 방법은 바텀업 탐지 철학(bottom-up detection philosophy)을 따랐습니다. 2014년 이후, 시각적 인식에서 딥 CNN의 인기로 인해, 상향식(top-down) 학습 기반 접근 방식이 이 문제에서 더 많은 장점을 보이기 시작했습니다. 현재 객체 제안 탐지는 원스테이지 탐지기의 등장 후 점차 주목받지 않게 되었습니다.
Deep Regression and Anchor-Free Detection: 최근 몇 년 간 GPU의 연산 능력 증가로 다중 스케일 탐지가 점점 더 직관적이고 강력한 방법으로 발전했습니다. 다중 스케일 문제를 해결하기 위한 딥 회귀(deep regression) 방법은 간단해졌습니다. 즉, 딥 러닝 특징을 기반으로 바운딩 박스의 좌표를 직접 예측하는 방식입니다. 2018년 이후, 연구자들은 객체 탐지 문제를 키포인트 탐지 관점에서 생각하기 시작했습니다. 이 방법들은 두 가지 아이디어를 따릅니다: 첫 번째는 키포인트(코너, 중심 또는 대표 점)를 탐지한 후 객체별로 그룹화(grouping)를 수행하는 그룹 기반 방법입니다, 두 번째는 객체를 하나 또는 여러 점으로 보고, 그 점들을 기준으로 객체의 속성(크기, 비율 등)을 회귀하는 그룹 프리(group-free) 방법입니다.
Multireference/Multiresolution Detection: 멀티레퍼런스(multireference) 탐지는 현재 다중 스케일 탐지에서 가장 많이 사용되는 방법입니다. 멀티레퍼런스 탐지의 주요 아이디어는 이미지의 각 위치에 참조(또는 앵커, 박스와 점 등)를 정의한 후, 이 참조를 바탕으로 탐지 박스를 예측하는 것입니다. 또 다른 인기 있는 기술은 멀티해상도(multiresolution) 탐지입니다. 이는 네트워크의 다른 레이어에서 다양한 크기의 객체를 탐지하는 방법입니다. 멀티레퍼런스와 멀티해상도 탐지는 현재 최신 객체 탐지 시스템에서 두 가지 기본 구성 요소로 자리 잡고 있습니다.
[71] J. Hosang, R. Benenson, P. Dollár, 및 B. Schiele, “효과적인 검출 제안을 위한 요소는 무엇인가?” IEEE 패턴 분석 및 기계 지능 저널, 제38권, 제4호, pp. 814–830, 2016년 9월.
[72] J. Hosang, R. Benenson, 및 B. Schiele, “검출 제안이 정말 좋은가?” 2014, arXiv:1406.6962.
[73] B. Alexe, T. Deselaers, 및 V. Ferrari, “객체란 무엇인가?” 컴퓨터 비전 및 패턴 인식 컨퍼런스 (CVPR), 2010년 6월, pp. 73–80.
[74] B. Alexe, T. Deselaers, 및 V. Ferrari, “이미지 창에서 객체성 측정,” IEEE 패턴 분석 및 기계 지능 저널, 제34권, 제11호, pp. 2189–2202, 2012년 11월.
[20] J. Redmon, S. Divvala, R. Girshick, A. Farhadi, “YOLO: 통합된 실시간 객체 탐지,” Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2016, pp. 779–788.
[66] C. Szegedy, A. Toshev, 및 D. Erhan, “객체 검출을 위한 심층 신경망,” 신경 정보 처리 시스템 (NIPS) 컨퍼런스, 2013, pp. 2553–2561.
[26] H. Law, J. Deng, “CornerNet: 객체를 쌍으로 된 키포인트로 탐지,” Proc. Eur. Conf. Comput. Vis. (ECCV), Sep. 2018, pp. 734–750.
[40] X. Zhou, D. Wang, P. Krähenbühl, “객체를 포인트로 다루기,” 2019, arXiv:1904.07850.
[19] S. Ren, K. He, R. Girshick, J. Sun, “Faster R-CNN: 지역 제안 네트워크를 이용한 실시간 객체 탐지,” Proc. Adv. Neural Inf. Process. Syst., 2015, pp. 91–99.
[23] W. Liu et al., “SSD: 싱글 샷 멀티박스 탐지기,” Proc. ECCV. Cham, Switzerland: Springer, 2016, pp. 21–37.
논문의 내용이 길어 나누어 정리하였다.
2024.12.25 - [CV] - [논문 리뷰] Object Detection in 20 Years: A Survey 2