YOLO 개요
YOLO(You Only Look Once) 모델은 객체 탐지(Object Detection) 분야에서 큰 혁신을 일으킨 모델로, 빠르고 정확한 성능 덕분에 많은 분야에서 활발히 사용되고 있습니다. 객체 탐지는 이미지나 영상 내에서 특정 객체를 식별하고 위치를 파악하는 작업으로, 자율 주행, 보안 시스템, 로봇 비전 등에서 필수적인 기술로 자리 잡았습니다.
YOLO 알고리즘의 탄생은 컴퓨터 비전과 객체 탐지 분야에서 중요한 변화를 가져왔습니다. YOLO는 2015년경 개발되었으며, 당시의 기술적 배경과 발전을 이해하면 이 알고리즘의 혁신적인 접근 방식과 그 중요성을 잘 알 수 있습니다.
오늘은 이 모델의 발전과 각 모델별 주요 특징을 살펴보려고 합니다. 이전에 yolo에 대한 리뷰 논문도 리뷰한 적이 있으니 참고 하면 도움이 될 것 같습니다.
[논문 리뷰] Evaluating the Evolution of YOLO (You Only Look Once) Models: A Comprehensive Benchmark Study of YOLO11 and Its
이 리뷰는 오직 학습과 참고 목적으로 작성되었으며, 해당 논문을 통해 얻은 통찰력과 지식을 공유하고자 하는 의도에서 작성된 것입니다. 본 리뷰를 통해 수익을 창출하는 것이 아니라, 제 학
c0mputermaster.tistory.com
기존의 객체 검출(detection) 모델은 분류기(classifier)를 재정의하여 검출기(detector)로 사용하고 있습니다. 객체 검출은 하나의 이미지 내에서 각 객체의 위치를 판단하는 작업으로, 단순히 객체의 위치를 찾는 것뿐만 아니라 해당 객체가 무엇인지를 분류하는 작업도 추가로 수행해야 합니다. 이 과정은 많은 컴퓨터 비전 모델들이 해결하고자 했던 문제였고, 그 중 대표적인 모델이 R-CNN입니다.
R-CNN은 이미지 안에서 bounding box를 생성하기 위해 'Region Proposal' 방식을 사용합니다. 이 방식은 다음과 같은 절차를 따릅니다:
- 생성된 bounding box에 classifier를 적용하여 분류: 먼저 후보 영역을 추출하고, 이 영역에 분류기를 적용하여 객체를 분류합니다.
- 분류 후 bounding box를 조정: 분류된 객체의 위치가 정확하지 않다면 bounding box를 다시 조정합니다.
- 중복된 검출을 제거: 동일한 객체가 여러 번 검출될 수 있기 때문에 중복된 영역을 제거하는 작업이 필요합니다.
- 후처리: 객체에 따라 bounding box의 점수를 재산정하여 최종적으로 정확한 객체 위치를 확보합니다.
하지만 이러한 과정은 매우 복잡하고 시간이 많이 걸리며, 계산 비용이 크고 각 절차가 독립적으로 훈련되기 때문에 최적화가 어려운 단점이 존재합니다. 그래서 속도와 비용 측면에서 실시간 처리가 어려운 문제가 있었습니다.

이러한 문제를 해결하기 위해 YOLO 알고리즘은 객체 검출을 하나의 회귀 문제로 재정의했습니다. YOLO는 이미지의 픽셀로부터 bounding box의 위치와 클래스 확률을 동시에 예측하는 방식을 도입하였습니다. 기존처럼 여러 단계로 나누어 검출하지 않고, 하나의 파이프라인을 통해 모든 작업을 수행함으로써 속도와 정확도를 동시에 개선할 수 있었습니다.
2024.12.27 - [CV/CV 기초] - [Object Detection] 1-Stage vs. 2-Stage Object Detection 아키텍처 비교
[Object Detection] 1-Stage vs. 2-Stage Object Detection 아키텍처 비교
Object Detection detector 객체 탐지(Object Detection) 시스템에서 이미지나 비디오 내의 객체를 식별하고 위치를 추정하는 알고리즘 또는 모델을 의미합니다. 객체 탐지에서 detector는 특정 객체가 이미지
c0mputermaster.tistory.com
1-stage detection에 대한 더 자세한 내용은 이전 포스트 참조
YOLO의 접근 방식은 다음과 같습니다:
- 하나의 네트워크를 통해 이미지를 한 번만 처리하여 객체의 위치와 분류를 동시에 예측합니다.
- 이 방식은 이미지 내의 객체 검출을 하나의 회귀 문제로 재정의하여 효율성을 크게 향상시켰습니다.
이로 인해 YOLO는 기존의 복잡한 절차를 단순화하고, 실시간 처리에 적합한 성능을 제공하며, 객체 검출의 속도와 정확도에서 혁신적인 변화를 이끌어냈습니다.
YOLO v1 (2016)
2025.01.25 - [CV/논문 리뷰] - [논문 리뷰] You Only Look Once: Unified, Real-Time Object Detection 2
[논문 리뷰] You Only Look Once: Unified, Real-Time Object Detection 2
이 리뷰는 오직 학습과 참고 목적으로 작성되었으며, 해당 논문을 통해 얻은 통찰력과 지식을 공유하고자 하는 의도에서 작성된 것입니다. 본 리뷰를 통해 수익을 창출하는 것이 아니라, 제 학
c0mputermaster.tistory.com
- Backbone: Darknet
- 주요 특징:
- 입력 이미지를 SxS 그리드 셀로 나누어 각 셀에서 bounding boxes (bbox), confidence score, class probabilities를 예측.
- Non-Maximum Suppression (NMS)을 사용하여 겹치는 박스를 제거하고 가장 높은 점수의 bbox를 선택.
- 각 그리드 셀에서 하나의 클래스만 예측.
YOLO v2 (2017)
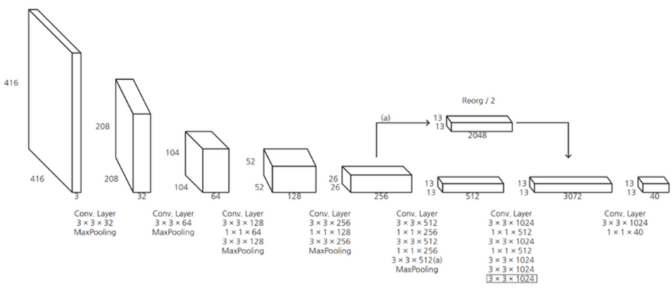
- Backbone: Darknet-19
- 주요 특징:
- fully connected layers를 1x1 convolution layers로 교체.
- global average pooling을 사용하여 파라미터를 줄이고 속도 향상.
- Anchor boxes 도입으로 미리 정의된 형태의 bbox를 사용.
- 더 높은 해상도(448x448)로 pre-training하여 mAP 4% 향상.
YOLO v3 (2018)
- Backbone: Darknet-53
- Feature Pyramid Network (FPN)
- 주요 특징:
- Skip connections 적용 및 pooling layer 제거.
- loss function을 softmax가 아닌 모든 class에 대해 sigmoid를 사용하여 각 클래스별 binary classification을 수행.
- 작은 객체에 대한 성능 개선.
- 속도보다는 성능 개선에 초점을 맞춤.
YOLO v4 (2020)
- Backbone: CSPDarknet53
- Neck: SPP + PANet
- 주요 특징:
- 작은 객체 검출을 개선하기 위해 input image size를 512로 사용.
- 기존의 모델들은 Backbone과 Head로 구성되어 있었는데 서로 다른 scale의 Feature map을 수집하는 Neck layer 추가
- 여러 레이어를 추가해 receptive field를 확장.
- 다양한 data augmentation과 quantization 기법을 도입해 성능과 모델 크기 최적화.
YOLO v5 (2020)
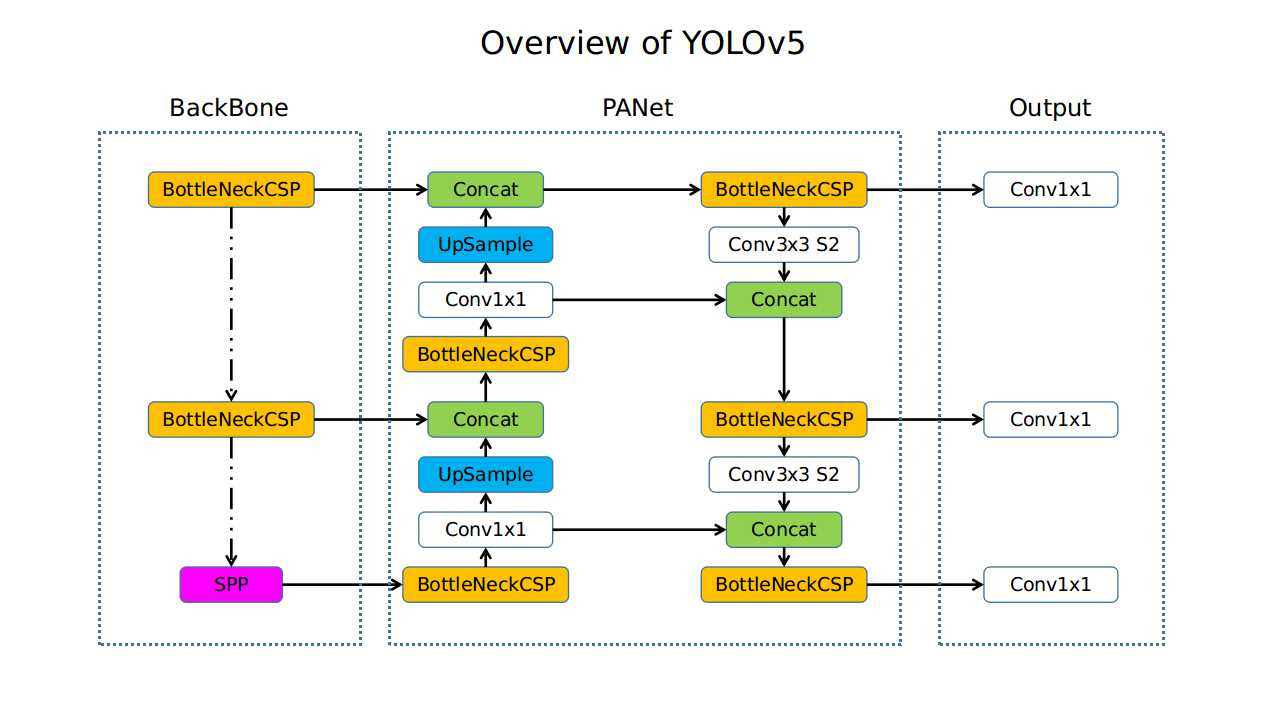
- Backbone: CSPDarknet53
- 주요 특징:
- 모델 구조는 V4와 유사하며 V3의 darknet 프레임워크를 pytorch로 변환
- 다양한 모델 크기(소형, 중형, 대형 등) 제공.
- 다양한 augmentation 적용 -> mosaic augmentation으로 인해 작은 객체에 대한 성능 개선
- CNN 연산 최적화를 통해 파라미터 사용과 계산량의 균형을 맞춤.
YOLOX (2021)
- Backbone: Darknet-53
- Neck: SPP
- 주요 특징:
- Anchor-free model로 center coordinates만 사용해 bbox를 예측.
- SimOTA (Optimal Transport) 기법을 도입하여 여러 박스를 다룰 때 발생하는 문제 해결.
YOLO v6 (2022)
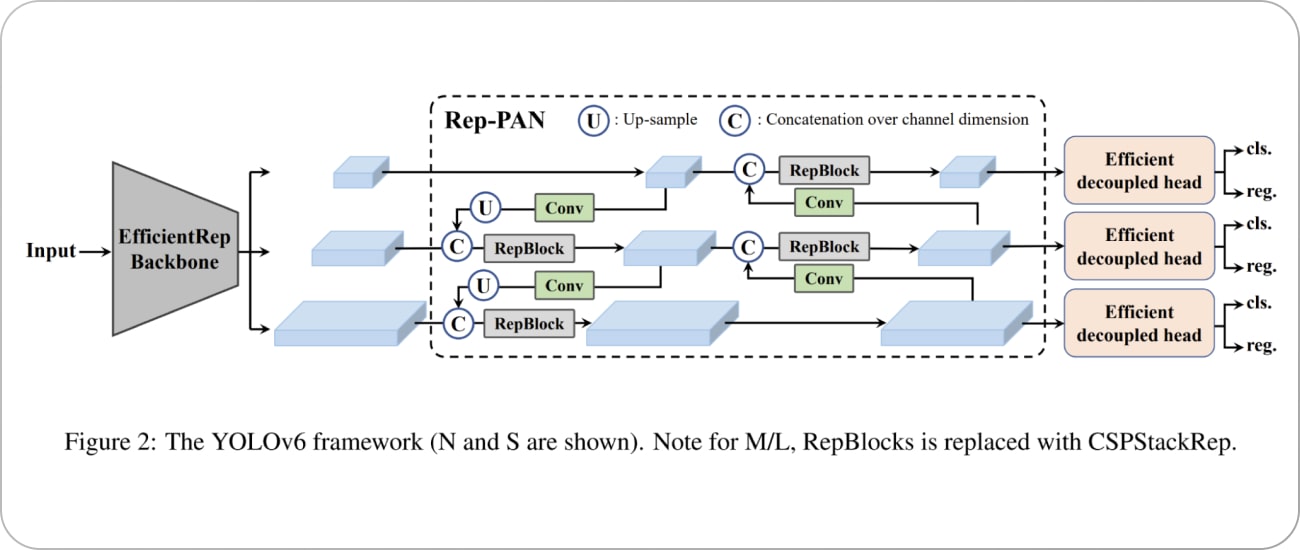
- Backbone: EfficientRep
- Neck: Rep-PAN
- 주요 특징:
- knowledge distillation 시 모든 학습 단계에서 student model이 지식을 효율적으로 학습할 수 있도록 teacher와 label의 지식을 동적으로 조정
- PTQ(Post-Training Quantization)와 QAT(Quantization-Aware Training)을 활용한 양자화 체계 최적화.
YOLO v7 (2022)
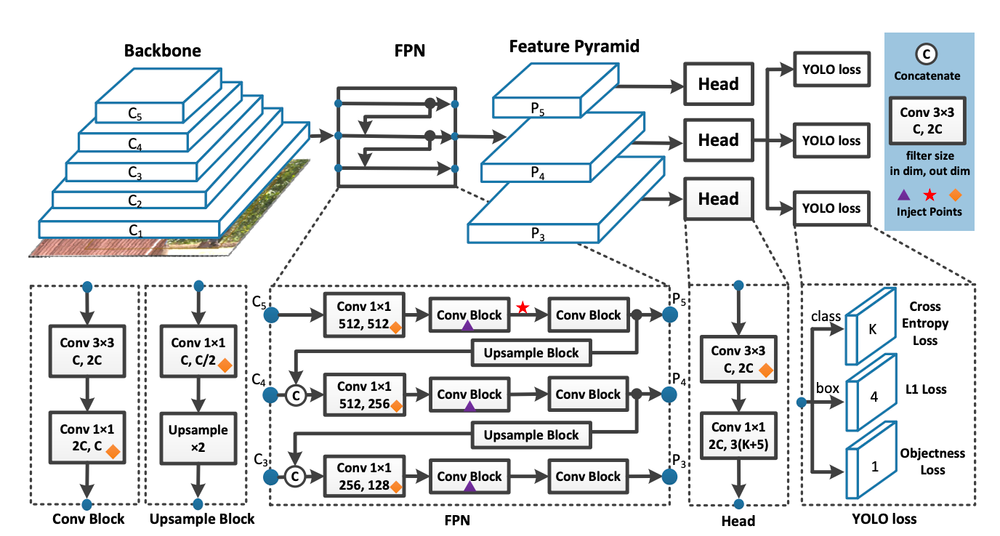
- Backbone: E-ELAN
- 주요 특징:
- 이전 모델은 computation block을 어느 정도 많이 쌓아도 잘 학습되지만 무한대로 쌓으면 파라미터가 많아지는 문제가 있음 => E-ELAN을 도입하여 파라미터 활용 효율성 개선.
- GT를 그냥 사용하는 것이 아닌 prediction, gt의 distribution(분포)을 고려 해 새로운 soft label을 생성
YOLO v8 (2023)
- Backbone: CSPDarknet53
- Neck: SPP + PANet + SAM (Spatial Attention Module)
- 주요 특징:
- Anchor-free model (앵커박스 대신 객체 중심을 예측하여 NMS 속도 향상)로 더 빠른 처리 속도.
- backbone에서 첫번째 6x6 conv를 3x3 conv로 교체
- 두개의 conv layer 삭제
- ConvBottleneck에서 첫번째 1x1 Conv를 3x3 Conv로 교체
- 분리된 head 사용
- C3 모듈을 C2f 모듈로 교체하여 성능 개선.
YOLO v9 (2024)
- Backbone: GELAN
- Neck: PGI (Programmable Gradient Information)
- 주요 특징:
- PGI 기법을 통해 information bottleneck 문제를 해결.
- gradient path planning에 기반한 경량화된 네트워크 아키텍처 제안.
YOLO v10 (2024)
- Backbone: CSPNet
- 주요 특징:
- NMS를 제거하고 dual label assignments 방식을 사용.
- Rank-guided block design을 통해 중복 연산을 제거하고 CIB (Compact Inverted Block)을 도입하여 파라미터 효율성 향상.
YOLO v11 (2024)
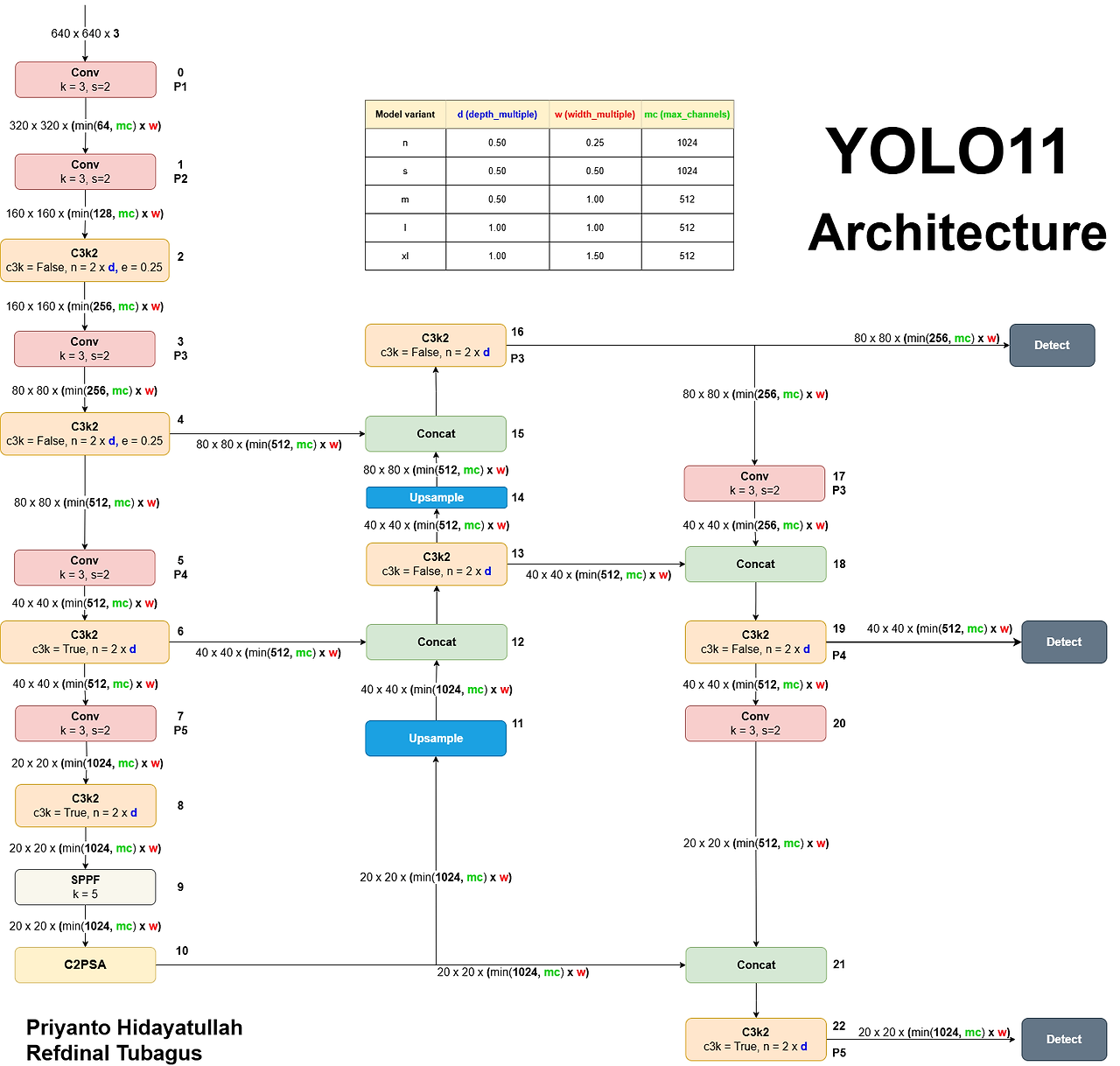
- YOLOv11의 주요 아키텍쳐 개선사항은 C3k2 block, SPPF, C2PSA를 통해 모델의 특징 추출과 성능 개선을 이뤄냈다.
- YOLOv11은 object detection, instance segmentation, pose estimation, and oriented object detection (OBB)와 같은 다양한 비전 태스크 기능을 제공한다.
- YOLOv11은 성능적인 측면에서 mAP(mean Average Precision)와 이전 버전 대비 계산 효율성을 높였음.
YOLO v12 (2025)
- 영역 주의 메커니즘
- 대규모 수용 필드 효율적 처리, 계산 비용 절감함
- 잔여 효율적 계층 집계 네트워크 (R-ELAN)
- ELAN 기반, 병목 현상 해결 및 최적화 개선됨
- 최적화된 주의 집중 아키텍처
- 플래시어텐션과 MLP 비율 조정으로 성능 향상됨
https://docs.ultralytics.com/ko/models/yolo12/
YOLO12
타의 추종을 불허하는 정확성과 효율성으로 최첨단 물체 감지를 위한 획기적인 주의 집중 아키텍처를 갖춘 YOLO12를 만나보세요.
docs.ultralytics.com
참고 자료
https://www.ultralytics.com/ko
Ultralytics | 비전 AI의 세계 혁신
Ultralytics의 사명은 사람과 기업이 AI의 긍정적인 잠재력을 발휘할 수 있도록 지원하는 것입니다. 유니티의 비전 AI 도구로 모델에 생명을 불어넣으세요.
www.ultralytics.com
https://devocean.sk.com/blog/techBoardDetail.do?ID=166976&boardType=techBlog
From One to Ten: YOLO 시리즈 변천사
devocean.sk.com
https://velog.io/@juneten/YOLO-v1v9
YOLO모델 및 버전별 차이점 분석
2016년에 발표된 최초 버전물체가 작을수록 정확도가 감소한다.여러 물체가 겹쳐있을 경우 제대로된 예측이 어렵다.Bounding Box 형태가 data를 통해 학습되므로 새로운 형태의 Bounding Box의 경우 정확
velog.io
'Computer Vision > Computer Vision' 카테고리의 다른 글
| [Segmentation] Semantic Segmentation 알아보기 FCN, U-Net (0) | 2025.09.24 |
|---|---|
| [Anomaly Detection] Industrial Image Anomaly Detection: Survey (1) | 2025.08.10 |
| [Object Detection] 1-Stage vs. 2-Stage Object Detection 아키텍처 비교 (0) | 2024.12.27 |