이 리뷰는 오직 학습과 참고 목적으로 작성되었으며, 해당 논문을 통해 얻은 통찰력과 지식을 공유하고자 하는 의도에서 작성된 것입니다. 본 리뷰를 통해 수익을 창출하는 것이 아니라, 제 학습과 연구를 위한 공부의 일환으로 작성되었음을 미리 알려드립니다.
오늘은 LLM 모델의 발전을 전반적으로 이해할 수 있는 Survey 논문에 대한 리뷰인데 전체적인 LLM의 발전과 흐름을 이해하는데 도움이 될 것 같아 리뷰하였다. 이 포스트의 논문 리뷰는 25년에 업데이트된 Large Language Models: A Survey v3버전을 기준으로 작성되었다.
S. Minaee, T. Mikolov, N. Nikzad, M. Chenaghlu, R. Socher, X. Amatriain, and J. Gao, "Large Language Models: A Survey," arXiv preprint arXiv:2402.06196, 2025. [Online]. Available: https://arxiv.org/abs/2402.06196.
ABSTRACT
대형 언어 모델(LLMs)은 2022년 11월 ChatGPT 출시 이후 다양한 자연어 처리 작업에서 뛰어난 성능을 보여 주목받고 있음. LLM은 수십억 개의 모델 파라미터를 대규모 텍스트 데이터로 학습하여 언어 이해 및 생성 능력을 습득하며, 이는 스케일링 법칙에 의해 예측됨. LLM 연구 분야는 최근에 시작되었지만, 빠르게 발전하고 있으며 여러 가지 방향으로 진화하고 있음. 본 논문에서는 GPT, LLaMA, PaLM과 같은 대표적인 LLM 계열을 포함한 주요 LLM들을 살펴보고, 이들의 특징, 기여 및 한계를 논의함. 또한 LLM을 구축하고 보강하는 데 사용된 기술들을 개괄적으로 설명함. 이후 LLM 학습, 세부 조정 및 평가에 사용되는 인기 있는 데이터셋을 조사하고, 널리 사용되는 LLM 평가 지표를 리뷰하며, 대표적인 벤치마크에서 여러 인기 있는 LLM의 성능을 비교함.
I. INTRODUCTION
Introduction에서는 대형 언어 모델(LLM)에 대한 발전과 특성을 소개함

- 언어 모델의 역사적 발전:
- 언어 모델링은 1950년대 Shannon의 정보 이론을 기반으로 시작됨.
- 이후 통계적 언어 모델(SLM)은 텍스트를 단어 시퀀스로 보고, n-그램 모델을 사용해 단어 확률을 추정했음. 하지만 데이터 희소성 문제로 한계가 있었음.
- 신경망 언어 모델(NLM)은 이를 해결하기 위해 단어를 임베딩 벡터로 변환하고, 신경망을 통해 다음 단어를 예측하는 방식으로 발전했음.
- 사전 학습된 언어 모델(PLM)은 사전 학습과 미세 조정 패러다임을 사용해 더 넓은 범위의 작업을 수행할 수 있도록 했음.
- 대형 언어 모델(LLM)은 수십억 개에서 수백억 개의 파라미터를 가진 모델로, 웹 규모의 데이터에서 학습하여 자연어 이해와 생성 능력을 획기적으로 확장했음.
SLM → NLM → PLM → LLM
- SLM(Small Language Model) : 제한된 양의 텍스트 데이터를 학습하여, 국소적인 문맥 이해에 초점을 둠. 작은 규모이기 때문에 가볍고 빠르게 실행가능한 특성을 가진다.
- NLM(Neural Language Model) : 단어 임베딩, 문장 완성, 기계 번역 등의 NLP작업에 활용되는 언어모델로, 기존의 통계 기반 언어 모델보다 더 정확한 성능을 제공하는 것으로 알려져 있습니다.
- PLM(Pretrained Language Model) : 대규모 데이터 셋으로 미리 학습된(Pre-trained) 언어모델로, 전이학습(Transfer Learning)을 통해 다양한 NLP 작업에 활용됩니다. BERT와 GPT와 같은 주요 모델들이 이 PLM에 해당한다고 할 수 있습니다.
PLM의 데이터 셋 규모가 점차 증가한 것을 대형 PLM이라고 칭하다가, '대규모 언어모델(LLM)'이라는 용어로 사용하는 것이 지금의 LLM이다.
- LLM의 주요 특성:
- Emergent abilities: LLM은 이전 모델에서는 볼 수 없었던 능력들을 보였음. 예를 들어, 맥락 내 학습, 지침 따르기, 다단계 추론 등이 가능했음.
- AI 에이전트로서의 가능성: LLM은 AI 에이전트로 배포될 수 있으며, 동적 환경에서 행동을 취하고 외부 지식과 도구를 활용하여 상호작용할 수 있었음.
- LLM의 구성과 발전:
- LLM은 트랜스포머 기반 신경망 언어 모델로, GPT, LLaMA, PaLM과 같은 대표적인 모델이 있었음. 이들 모델은 대규모 텍스트 데이터를 기반으로 사전 학습되어 강력한 언어 이해 및 생성 능력을 가졌음.
- 실제 애플리케이션에서의 사용:
- LLM은 다양한 응용 분야에서 활용되었고, 특히 AI 에이전트와 관련된 보강 기술을 통해 더 효율적인 시스템을 구축할 수 있었음.
- 향후 연구 방향:
- 이 논문에서는 LLM의 평가에 사용되는 데이터셋과 벤치마크를 소개하고, LLM의 성능을 평가하는 데 필요한 새로운 연구와 방법론이 필요함을 강조했음. 또한, LLM을 기반으로 한 AGI(인공지능 일반)의 발전 가능성에 대해 논의했음.
II. LARGE LANGUAGE MODELS
A. 초기 사전 훈련된 신경망 언어 모델들 ( Early Pre-trained Neural Language Models )
신경망 기반 언어 모델링은 n-그램 모델과 비교할 수 있는 신경망 언어 모델(NLM)을 개발한 연구자들에 의해 시작되었고, 이후 기계 번역에 성공적으로 적용됨. Mikolov가 공개한 RNNLM 툴킷은 NLM의 인기를 높였고, RNN, LSTM, GRU 기반의 모델들이 기계 번역, 텍스트 생성 등에서 널리 사용됨.
Transformer 아키텍처는 NLM 발전에 중요한 이정표가 되었음. Transformer는 셀프 어텐션을 통해 단어 간의 관계를 모델링하고, RNN보다 높은 병렬화를 가능하게 했음. 이로 인해 대규모 데이터를 효율적으로 사전 훈련할 수 있게 되었으며, 사전 훈련된 언어 모델(PLM)은 미세 조정을 통해 다양한 작업에 활용될 수 있음.
초기 Transformer 기반 PLM의 주요 범주:
- 인코더만 있는 모델: 텍스트 분류 등 언어 이해 작업에 사용됨. 대표 모델: BERT, RoBERTa, ALBERT, DeBERTa, XLM, XLNet 등.
- BERT: 마스크드 언어 모델링(MLM)과 다음 문장 예측을 통해 사전 훈련되고, 다양한 언어 이해 작업에 미세 조정됨.
- RoBERTa: BERT의 강건성을 향상시키기 위해 더 큰 배치 크기와 학습률을 사용.
- ALBERT: BERT의 메모리 소비를 줄이고 훈련 속도를 높이기 위해 파라미터 감소 기법 사용.
- DeBERTa: 분리된 어텐션 메커니즘과 강화된 마스크 디코더를 통해 BERT와 RoBERTa를 개선.
- ELECTRA: 교체된 토큰 감지(RTD) 방식을 사용하여 샘플 효율성을 높임.
- 디코더만 있는 모델: 대표 모델: GPT-1, GPT-2, GPT-3, GPT-4. OpenAI에서 개발되었음.
- GPT-1: 자기 지도 학습(self-supervised learning) 방식으로 사전 훈련된 디코더만 있는 모델.
- GPT-2: 대규모 웹 텍스트 데이터에서 훈련되었고, 감독 없이 특정 작업을 수행할 수 있음.
- 인코더-디코더 모델: 대표 모델: T5, mT5.
- T5: 텍스트-투-텍스트 방식으로 모든 NLP 작업을 변환하여 전이 학습을 효과적으로 활용.
- mT5: T5의 다국어 변형 모델로, 다양한 언어에서 훈련됨.
B. 대형 언어 모델(LLM) 계열
대형 언어 모델(LLM)은 주로 수십억에서 수백억 개의 파라미터를 가진 Transformer 기반의 언어 모델로, 모델 크기와 언어 이해 및 생성 능력이 훨씬 더 강력하고 emergent 능력도 보임. 여기서는 GPT, LLaMA, PaLM 세 가지 LLM 계열을 다룸.
- GPT 계열: GPT는 OpenAI에서 개발한 디코더 전용 Transformer 모델로, GPT-1부터 GPT-4까지 다양한 버전이 있음. GPT-3는 1750억 개의 파라미터를 가진 모델로, 컨텍스트 학습이라는 능력을 보이며, 미세 조정 없이 텍스트로 여러 작업을 수행할 수 있음. CODEX는 GPT-3를 기반으로 한 프로그래밍 모델로, GitHub Copilot에서 사용됨. WebGPT는 웹 브라우저를 통해 정보를 찾고 답변을 제공할 수 있는 모델. GPT-4는 멀티모달 모델로 텍스트와 이미지를 입력받아 텍스트로 응답할 수 있음. 또한 여러 전문 시험에서 인간 수준의 성능을 보였음.
- LLaMA 계열: LLaMA는 Meta에서 개발한 오픈소스 모델로, 여러 연구자들이 사용하고 있음. LLaMA 모델은 GPT-3의 아키텍처를 기반으로 하되, 몇 가지 수정이 있음. LLaMA-2는 Microsoft와 협력하여 출시된 모델로, 대화용으로 미세 조정된 LLaMA-2 Chat 모델이 여러 공개 벤치마크에서 우수한 성능을 보였음. LLaMA는 오픈소스라 많은 연구자들이 새로운 모델을 개발하거나 임무별 LLM을 구축하는 데 사용하고 있음.
- PaLM 계열: PaLM은 Google에서 개발한 모델로, 540B 파라미터를 가진 대형 모델임. PaLM은 여러 언어 이해 및 생성 작업에서 뛰어난 성과를 보였으며, 멀티스텝 추론 작업에서 좋은 성능을 기록함. Flan-PaLM은 PaLM 모델을 여러 작업에 대해 미세 조정한 버전으로, 이전 모델보다 더 높은 성능을 보임. Med-PaLM은 의료 질문에 대한 답변을 제공하는 모델로, 의료 분야에서 유용하게 사용될 수 있음.
C. 기타 대표적인 LLM들
이전 섹션에서 다룬 세 가지 모델 계열 외에도, 성능이 뛰어나고 LLM 분야를 발전시킨 다른 인기 있는 LLM들이 있음. 이들에 대해 간단히 설명함.
- FLAN: Wei et al.는 언어 모델의 제로샷 학습 능력을 향상시키는 간단한 방법을 제시. FLAN은 137B 파라미터의 사전 학습된 모델을 60개 이상의 NLP 데이터셋을 기반으로 자연어 지침으로 미세 조정하여 제로샷 성능을 크게 향상시킴.
- Gopher: Rae et al.는 다양한 크기의 Transformer 기반 모델 성능을 분석하여 280B 파라미터를 가진 Gopher를 제시. Gopher는 152개 다양한 작업에서 뛰어난 성능을 보였음.
- T0: Sanh et al.는 자연어 작업을 사람이 읽을 수 있는 형식으로 쉽게 변환할 수 있는 시스템 T0를 개발. 이 시스템은 다양한 데이터셋을 사용해 모델의 제로샷 성능을 평가함.
- ERNIE 3.0: Sun et al.는 ERNIE 3.0이라는 지식 기반 모델을 제시. 이 모델은 자동 회귀 및 자동 인코딩 네트워크를 결합해 자연어 이해 및 생성 작업을 처리함.
- RETRO: Borgeaud et al.는 문서 덩어리를 기준으로 이전 토큰과 유사한 데이터를 조건으로 하는 방식으로 성능을 향상시킨 모델 RETRO를 소개. 이를 통해 GPT-3와 비슷한 성능을 유지하면서도 파라미터를 절감할 수 있었음.
- GLaM: Du et al.는 전문가 혼합(Mixture-of-Experts) 아키텍처를 사용하여 모델 용량을 확장한 GLaM을 제시. 이 모델은 GPT-3보다 7배 더 큰 모델이지만 훈련 비용이 적고 성능이 뛰어났음.
- LaMDA: Thoppilan et al.는 대화형 모델인 LaMDA를 발표. 이 모델은 안전성 및 사실 기반 강화에 대한 미세 조정을 통해 대화 성능을 향상시킴.
- OPT: Zhang et al.는 Open Pre-trained Transformers(OPT)라는 모델을 발표. 이 모델은 125M에서 175B 파라미터까지 다양한 크기를 제공하며 연구자들과 공유됨.
- Chinchilla: Hoffmann et al.는 컴퓨팅 예산에 최적화된 모델 크기와 훈련 데이터 양을 제시. Chinchilla는 70B 파라미터와 4% 더 많은 데이터를 사용하여 성능을 개선함.
- Galactica: Taylor et al.는 과학적 지식을 처리할 수 있는 모델인 Galactica를 개발. 이 모델은 수학적 추론에서 뛰어난 성과를 보였음.
- CodeGen: Nijkamp et al.는 자연어와 프로그래밍 언어 데이터를 기반으로 한 모델 CODEGEN을 발표. 이 모델은 Python 코드 생성에서 제로샷 성능을 보였음.
- AlexaTM: Soltan et al.는 멀티언어 처리 모델인 AlexaTM을 발표. 이 모델은 20B 파라미터로, 1샷 요약 작업에서 뛰어난 성능을 보임.
- Sparrow: Glaese et al.는 정보 탐색 대화형 모델 Sparrow를 개발. 이 모델은 인간의 피드백을 통해 더 정확하고 안전한 대화형 응답을 제공함.
- Minerva: Lewkowycz et al.는 수학, 과학 및 공학 문제를 해결할 수 있는 모델 Minerva를 발표. 이 모델은 이전의 LLM들이 겪었던 수치적 추론 문제를 해결함.
- MoD: Tay et al.는 다양한 전처리 방법을 결합한 Mixture-of-Denoisers(MoD)라는 새로운 학습 방식을 제시. 이를 통해 LLM의 성능을 향상시킬 수 있었음.
- BLOOM: Scao et al.는 176B 파라미터를 가진 오픈 액세스 모델 BLOOM을 발표. 이 모델은 다양한 자연어와 프로그래밍 언어에서 뛰어난 성능을 보였음.
- GLM: Zeng et al.는 130B 파라미터를 가진 GLM-130B 모델을 발표. 이 모델은 영어와 중국어를 처리할 수 있는 이중 언어 모델임.
- Pythia: Biderman et al.는 Pythia라는 16개의 다양한 모델을 발표. 이 모델들은 공개 데이터로 학습되어 연구자들이 재구성하여 사용할 수 있음.
- Orca: Mukherjee et al.는 GPT-4의 사고 과정을 모방하여 학습하는 Orca를 개발. 이 모델은 복잡한 지침을 따라 학습함.
- StarCoder: Li et al.는 15.5B 파라미터를 가진 StarCoder 모델을 발표. 이 모델은 Python 코드 생성에서 뛰어난 성과를 보였음.
- KOSMOS: Huang et al.는 다중 모달 모델인 KOSMOS-1을 발표. 이 모델은 텍스트와 이미지를 동시에 처리하며 뛰어난 성능을 보였음.
- Gemini: Gemini 팀은 이미지, 오디오, 비디오, 텍스트를 처리할 수 있는 다중 모달 모델을 발표. 이 모델은 고급 작업을 처리하는 Ultra 버전, 성능 및 배치 처리에 최적화된 Pro 버전, 디바이스에서 사용 가능한 Nano 버전을 포함함.
기타 인기 있는 LLM 프레임워크나 기술로는 InnerMonologue, Megatron-Turing NLG, LongFormer, OPT-IML, MeTaLM, Dromedary, Palmyra 등이 있음.
III. HOW LLMS ARE BUILT

이 섹션에서는 LLM에 사용되는 인기 있는 아키텍처를 살펴보고, 데이터 준비, 토크나이징, 사전 학습, 지시 튜닝, 정렬 등 데이터와 모델링 기법에 대해 논의함. 모델 아키텍처가 선택되면 LLM을 훈련시키기 위한 주요 단계는 데이터 준비(수집, 청소, 중복 제거 등), 토크나이징, 모델 사전 학습(자기 지도 학습 방식), 지시 튜닝, 정렬 등이 있음.
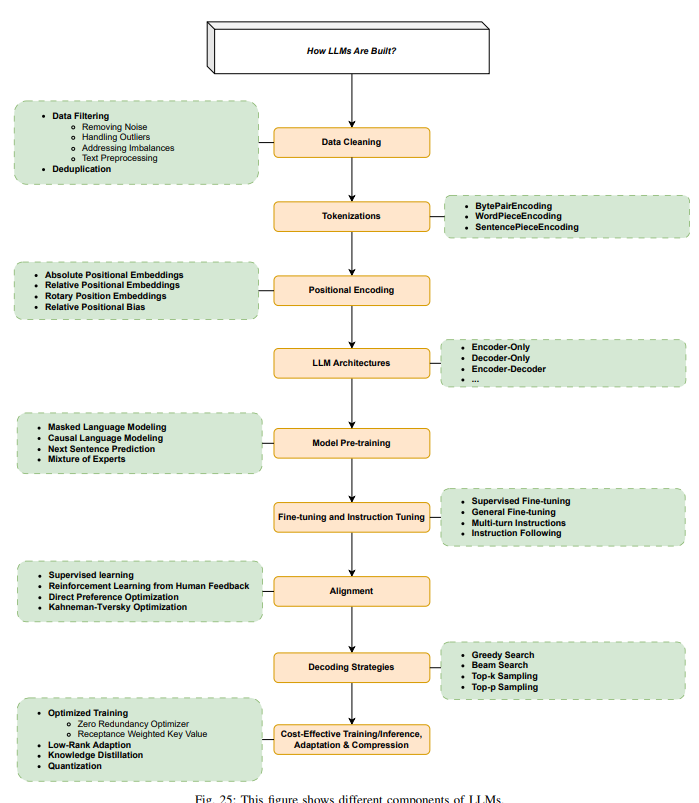
A. 주요 LLM 아키텍처
가장 널리 사용되는 LLM 아키텍처는 인코더 전용, 디코더 전용, 인코더-디코더로 나뉨. 대부분의 LLM은 Transformer를 기반으로 하고 있기 때문에, Transformer 아키텍처도 함께 살펴봄.
- Transformer
Transformer는 원래 GPU를 활용한 효율적인 병렬 컴퓨팅을 위해 설계됨. Transformer의 핵심은 자기 주의(attention) 메커니즘으로, 이는 긴 문맥을 효율적으로 처리할 수 있게 해줌. Transformer는 기계 번역을 위해 처음 제안되었으며, 인코더와 디코더로 구성됨. 인코더는 여러 개의 동일한 Transformer 레이어로 이루어져 있으며, 각 레이어는 두 개의 하위 층으로 구성됨. 첫 번째 하위 층은 다중 헤드 자기 주의 층, 두 번째 하위 층은 완전 연결된 피드포워드 네트워크임. 디코더는 인코더와 비슷하지만, 추가적으로 인코더 출력에 대해 다중 헤드 주의 메커니즘을 적용하는 세 번째 하위 층이 있음. 이 자기 주의 메커니즘은 쿼리와 키-값 쌍을 매핑하여 출력을 계산하며, 쿼리와 키 간의 호환성 함수로 값을 가중합으로 구함. 또한, 각 입력의 위치 정보를 반영하기 위해 위치 인코딩을 사용함. - 인코더 전용
인코더 전용 모델은 각 단계에서 입력된 문장의 모든 단어를 참조할 수 있음. 이러한 모델은 보통 주어진 문장을 일부러 변형시켜(예: 무작위로 일부 단어를 마스킹) 원래의 문장을 예측하는 방식으로 사전 학습됨. 인코더 전용 모델은 문장의 전체적인 이해가 중요한 작업에 적합함. 예를 들어, 문장 분류, 개체명 인식, 추출적 질문 응답 등의 작업에서 유용함. 대표적인 인코더 전용 모델은 BERT(Bidirectional Encoder Representations from Transformers)임. BERT는 문맥을 양방향으로 이해할 수 있어서, 텍스트에서 단어 간의 관계를 잘 파악할 수 있음. - 디코더 전용
디코더 전용 모델은 각 단계에서 해당 단어 앞에 나온 단어들만 참조할 수 있음. 이런 모델들은 주로 "자기 회귀적(auto-regressive)" 방식으로 훈련되며, 주어진 단어 다음에 올 단어를 예측하는 방식으로 학습됨. 디코더 전용 모델은 텍스트 생성 작업에 적합함. 예를 들어, GPT 모델은 텍스트 생성, 문장 완성, 대화형 생성 등에 주로 사용됨. - 인코더-디코더
인코더-디코더 모델은 두 가지 구조를 모두 사용하는 모델로, 주로 입력 텍스트를 기반으로 새로운 문장을 생성하는 작업에 적합함. 예를 들어, 문장 요약, 번역, 생성적 질문 응답 등에서 사용됨. 이 모델은 인코더가 입력 문장의 모든 단어를 참조할 수 있도록 하고, 디코더는 그 앞선 단어들만 참조하는 방식임. 인코더-디코더 모델은 사전 학습에서 단순히 인코더 또는 디코더 모델을 사용하는 것 외에도, 더 복잡한 방식으로 훈련되기도 함. 예를 들어, 텍스트의 일부분을 마스크 처리한 후, 그 마스크된 부분을 예측하도록 훈련될 수 있음.
B. Data Cleaning
데이터 품질은 모델의 성능에 중요한 영향을 미침. 데이터 정제 기법, 예를 들어 필터링과 중복 제거는 모델 성능에 큰 영향을 미친다고 알려져 있음. 예를 들어, Falcon40B에서는 Penedo 등이 적절히 필터링하고 중복 제거한 웹 데이터를 사용하면, 최신 모델들이 훈련된 The Pile을 능가하는 성능을 낼 수 있음을 보여줌. 이들은 CommonCrawl에서 5조 개의 토큰을 얻어냈으며, 600억 개의 토큰을 포함하는 REFINEDWEB 데이터를 이용해 모델을 훈련함.
- 데이터 필터링
데이터 필터링은 훈련 데이터의 품질을 향상시키고 훈련된 LLM의 효과성을 높이는 것을 목표로 함. 대표적인 데이터 필터링 기법은 다음과 같음:
- 노이즈 제거: 모델의 일반화 능력에 영향을 미칠 수 있는 불필요하거나 노이즈가 있는 데이터를 제거하는 것. 예를 들어, 잘못된 정보를 훈련 데이터에서 제거하여 모델이 잘못된 응답을 생성할 확률을 낮추는 것.
- 이상치 처리: 데이터에서 이상치나 특이값을 찾아 처리하여 모델에 미치는 영향을 줄이는 것.
- 불균형 해결: 데이터셋 내 클래스나 카테고리의 분포를 균형 있게 맞추어 모델이 편향되지 않도록 하는 것.
- 텍스트 전처리: 텍스트 데이터를 정리하고 표준화하는 것. 불용어, 구두점 등 모델 학습에 큰 기여를 하지 않는 요소들을 제거하는 것이 포함됨.
- 모호성 처리: 훈련 중 모델을 혼동시킬 수 있는 모호하거나 상충되는 데이터를 해결하거나 제외하는 것. 이를 통해 모델이 더 확실하고 신뢰할 수 있는 답변을 제공할 수 있게 됨.
- 중복 제거
중복 제거는 데이터셋에서 동일한 데이터 인스턴스를 제거하는 과정임. 중복 데이터는 모델 훈련 시 과적합을 유발할 수 있으며, 특정 패턴이나 특성이 과도하게 중요해지게 만듦. 중복 제거는 특히 큰 데이터셋에서 중요하며, 다양한 훈련 데이터를 사용하여 모델이 더 잘 일반화될 수 있도록 함. 중복을 제거하면 모델이 같은 예시를 여러 번 학습하는 것을 방지하고, 모델이 새로운 데이터에서 더 잘 일반화되도록 도와줌. 중복 제거 방법은 데이터의 성격과 모델 요구 사항에 따라 다를 수 있으며, 일반적으로는 고차원 특성(예: n-그램의 겹침)을 기반으로 중복을 식별하고 제거함.
C. Tokenizations
Tokenizations 은 텍스트를 작은 단위인 토큰으로 변환하는 과정임. 가장 간단한 토크나이징 방법은 공백을 기준으로 텍스트를 자르는 방식이지만, 대부분의 토크나이징 도구는 단어 사전을 기반으로 함. 그러나 사전에서 단어를 찾지 못하는 "OOV(Out Of Vocabulary)" 문제가 발생할 수 있음. 이를 해결하기 위해 LLM에서 사용되는 주요 토크나이저는 부분 단어(sub-words) 기반으로, 훈련 데이터에 없거나 다른 언어의 단어도 표현할 수 있도록 함. 여기서는 세 가지 주요 토크나이저를 설명함.
- BytePairEncoding (BPE)
BytePairEncoding은 원래 데이터 압축 알고리즘으로, 자주 사용되는 바이트 수준의 패턴을 이용해 데이터를 압축함. 이 알고리즘은 자주 사용되는 단어는 그대로 유지하고, 덜 사용되는 단어는 분해하는 방식으로 작동함. 이 방식은 어휘를 크게 늘리지 않으면서도 흔히 사용되는 단어를 잘 표현할 수 있음. - WordPieceEncoding
WordPieceEncoding은 BERT나 Electra와 같은 유명한 모델에서 사용되는 알고리즘임. 훈련 초기에는 훈련 데이터에 있는 모든 알파벳을 고려하여 "UNK"(알 수 없는 단어) 문제를 해결하려고 함. 이 방식은 주어진 단어가 토크나이저에서 처리할 수 없을 때 발생하는 문제를 처리하는 데 유용하며, BPE와 유사하게 빈도수를 기반으로 어휘를 최적화함. - SentencePieceEncoding
SentencePieceEncoding은 이전의 두 토크나이저가 공백을 기준으로 단어를 나누는 방식에 의존하는 단점을 해결하려고 시도함. 특히 일부 언어에서는 단어가 공백 없이 결합되거나 불필요한 공백이나 창작된 단어가 포함될 수 있음. SentencePiece는 이러한 문제를 해결하기 위해 설계됨.
D. Positional Encoding (위치 인코딩)
- 절대 위치 임베딩 (APE)
절대 위치 임베딩은 원래 Transformer 모델에서 시퀀스의 순서 정보를 유지하기 위해 사용됨. 이 정보는 인코더와 디코더 스택의 입력 임베딩에 추가되어 단어의 위치 정보를 전달함. 주로 사인(sine)과 코사인(cosine) 함수를 사용하여 고정된 방식으로 위치를 인코딩함. 하지만 APE는 토큰 수에 제한이 있으며, 상대적인 거리 정보를 반영하지 못하는 단점이 있음. - 상대 위치 임베딩 (RPE)
상대 위치 임베딩은 입력 요소 간의 상대적 링크를 반영하도록 자기 주의 메커니즘을 확장한 방식임. 이 방식은 입력을 완전 연결된 그래프로 보고, 상대적 위치 차이를 캡처할 수 있는 기능을 제공함. RPE는 긴 시퀀스에서도 잘 작동할 수 있도록 설계되어 모델이 훈련 데이터에 없는 시퀀스 길이에 대해서도 예측할 수 있도록 도움. - 회전 위치 임베딩 (RoPE)
회전 위치 임베딩은 기존 방식의 문제를 해결하기 위해 설계됨. RoPE는 단어의 절대 위치를 인코딩할 때 회전 행렬을 사용하고, 동시에 상대 위치 정보를 자기 주의에서 고려함. 이를 통해 문장의 길이에 유연하고, 상대적 거리가 커질수록 단어 의존성이 감소하는 특징을 제공함. - 상대 위치 편향 (Relative Positional Bias)
상대 위치 편향은 훈련 시퀀스보다 긴 시퀀스에 대해 예측을 할 때 모델이 잘 일반화되도록 돕는 방법임. 예를 들어, Attention with Linear Biases(ALiBi)는 단순히 위치 임베딩을 더하는 대신, 쿼리-키 쌍의 주의 점수에 편향을 추가하여 위치 차이에 비례하는 패널티를 부여함.
E. Model Pre-training
사전 학습은 LLM 훈련 파이프라인에서 첫 번째 단계로, 모델이 언어에 대한 기본적인 이해 능력을 습득할 수 있도록 함. 사전 학습은 보통 비라벨 텍스트를 사용하여 자가 지도 학습(self-supervised learning) 방식으로 이루어짐. 대표적인 사전 학습 방식으로는 다음 단어 예측(자기 회귀적 언어 모델링)과 마스킹된 언어 모델링이 있음.
- 자기 회귀적 언어 모델링: 주어진 토큰 시퀀스에서 다음에 올 토큰을 예측하는 방식임.
- 마스킹된 언어 모델링: 시퀀스에서 일부 단어를 마스킹하고, 모델이 주변 문맥을 기반으로 마스크된 단어를 예측하도록 훈련함.
최근에는 Mixture of Experts (MoE) 기법도 인기를 끌고 있음. MoE는 모델 훈련에 필요한 계산 자원을 줄이면서 모델 크기나 데이터셋 크기를 확장할 수 있게 해줌. MoE는 희소한 MoE 레이어와 "전문가"들로 구성되며, 각 전문가 네트워크는 토큰을 처리함. 이 모델은 특정 토큰을 여러 전문가에게 전달할 수 있으며, 라우터 네트워크는 어떤 전문가가 어떤 토큰을 처리할지를 결정함.
F. Fine-tuning과 Instruction Tuning
초기 언어 모델인 BERT는 특정 작업을 수행할 수 없었음. 이를 해결하기 위해 미세 조정이 필요했음. 예를 들어, BERT는 11개 작업에 대해 미세 조정됨. 최신 LLM은 일반적인 사용에는 미세 조정이 필요 없지만, 특정 작업에 맞는 미세 조정은 성능을 향상시킬 수 있음. 예를 들어, GPT-3.5 Turbo는 GPT-4보다 작은 크기에도 불구하고 특정 작업에 맞게 미세 조정하면 더 좋은 성능을 냄.
미세 조정은 하나의 작업에만 국한되지 않으며, 여러 작업을 동시에 미세 조정할 수도 있음. 이렇게 하면 성능이 향상되고 프롬프트 설계가 더 쉬워짐. 또한, 미세 조정은 훈련 중에 사용하지 않았던 새로운 데이터나 독점적인 데이터를 모델에 추가하는 데 유용함.
미세 조정의 중요한 목적 중 하나는 모델이 인간의 기대에 맞게 응답하도록 만드는 것인데, 이를 위해 instruction tuning이 사용됨. instruction tuning은 모델이 주어진 지시를 제대로 수행할 수 있도록 훈련시키는 과정임. Self-Instruct는 모델이 스스로 지침을 생성하고 이를 통해 미세 조정하는 방법임.
G. Alignment
AI alignment는 AI 시스템이 인간의 목표와 선호에 맞도록 만드는 과정임. LLM은 원래 단어 예측을 위해 훈련되었기 때문에 종종 유해하거나 편향된 내용을 생성할 수 있음. 이를 해결하기 위해 강화 학습을 통한 인간 피드백(RLHF)이나 AI 피드백(RLAIF)을 사용함. RLHF는 인간의 피드백을 통해 모델을 조정하는 방식이며, RLAIF는 잘 정렬된 모델을 사용해 학습하는 방식임.
최근 연구에서는 DPO(Direct Preference Optimization)라는 방법이 제시되었음. DPO는 RLHF의 복잡성과 불안정성을 해결하고, 감정 조절이나 요약 품질 향상에서 RLHF를 능가하는 성과를 냄. 또한, Kahneman-Tversky Optimization(KTO)은 선호 데이터 없이도 잘 동작하며, DPO보다 더 실용적이고 간단함.
H. 디코딩 전략 ( Decoding Strategies )
디코딩은 주어진 프롬프트를 바탕으로 텍스트를 생성하는 과정임. 다양한 디코딩 전략이 있으며, 각 전략은 생성되는 텍스트의 특성에 영향을 미침.
- Greedy Search: 가장 확률이 높은 토큰을 선택하는 방식으로 빠르지만, 일관성이 떨어질 수 있음.
- Beam Search: 여러 개의 가장 확률이 높은 토큰을 고려하여 시퀀스를 생성하는 방식으로 계산이 더 복잡하지만 더 나은 시퀀스를 생성함.
- Top-k Sampling: 가장 확률이 높은 k개의 토큰 중 하나를 무작위로 선택하는 방식으로, 다양성을 추가할 수 있음.
- Top-p (Nucleus) Sampling: 확률 합이 p 이상이 될 때까지 토큰을 선택하는 방식으로, 더 다양한 결과를 생성할 수 있음.
I. 비용 효율적인 훈련/추론/적응/압축
LLM의 훈련, 추론 및 적응을 더 비용 효율적이고 계산적으로 효율적으로 만드는 여러 방법들이 있음.
- ZeRO: 메모리 사용 최적화와 훈련 속도 향상을 위해 설계됨. 모델 크기를 키우면서도 효율적인 훈련을 가능하게 함.
- RWKV 아키텍처: Transformer의 병렬 훈련과 RNN의 효율적인 추론을 결합한 아키텍처로, 메모리와 계산 효율성이 뛰어남.
- Low-Rank Adaptation (LoRA): 적은 수의 학습 가능한 파라미터로 훈련 속도를 높이고, 작은 모델을 생성하는 방법임.
- Knowledge Distillation: 큰 모델의 지식을 작은 모델로 전이하여 더 작은 모델을 훈련시키는 방법임.
- Quantization: 모델의 가중치 정밀도를 낮추어 모델을 작고 빠르게 만드는 방법으로, 성능 저하 없이 효율적인 모델을 생성할 수 있음.
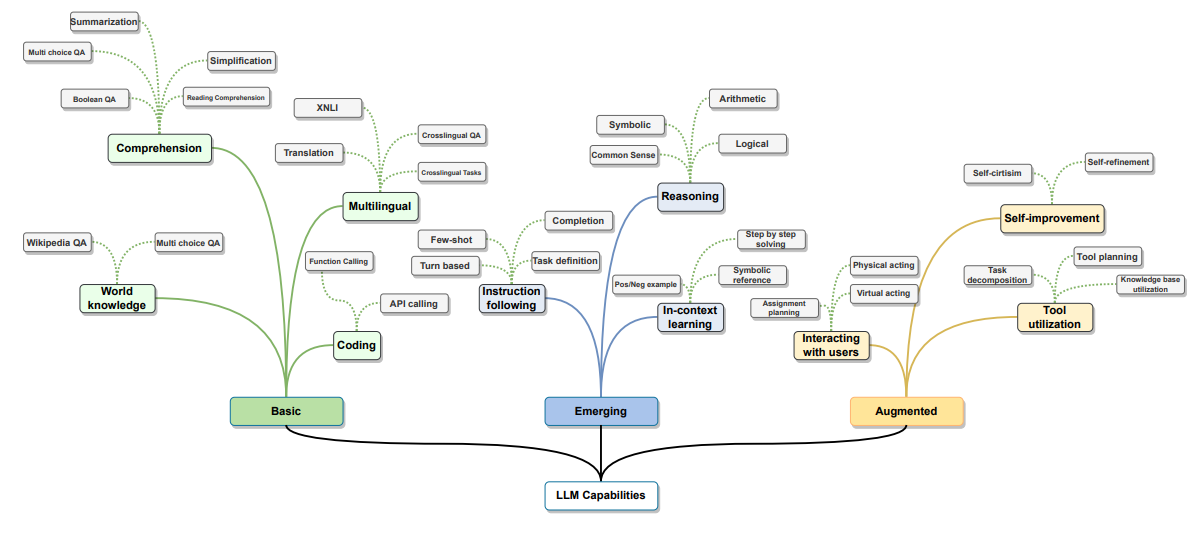
V. HOW LLMS ARE USED AND AUGMENTED
LLM(대형 언어 모델)이 훈련된 후에는 다양한 작업을 수행할 수 있는 출력을 생성하는 데 적용할 수 있음. 기본적인 프롬프트를 통해 LLM을 직접 사용할 수 있지만, 그들의 잠재력을 완전히 활용하고 몇 가지 한계를 해결하려면 외부 방법으로 모델을 증강해야 함. 이 섹션에서는 LLM의 주요 단점을 살펴보고, 특히 hallucinations(환각) 문제에 대해 집중적으로 다룬 후, 고급 prompting(프롬프트 기법) 기법과 증강 방법들이 어떻게 LLM의 능력을 향상시킬 수 있는지, 심지어 LLM이 외부 세계와 상호작용할 수 있는 완전한 AI agents(AI 에이전트)로 기능할 수 있도록 하는 방법을 설명함.
A. LLM의 한계 (Limitations of LLMs)
LLM은 매우 강력하지만 훈련 방식에 따라 내재된 몇 가지 한계가 존재함. 이러한 한계는 신뢰성과 정확성이 중요한 애플리케이션에서 LLM을 사용할 때 특히 중요한 고려 사항이 됨. 주요 한계는 다음과 같음:
- 기억/상태 없음 (No Memory/State): LLM은 기억을 갖고 있지 않으며, 프롬프트 간에 정보를 유지할 수 없음. 이전 입력이나 출력을 기억할 수 없으므로, 시간이 지나면서 상태를 유지해야 하는 작업에서는 중요한 한계가 됨.
- 확률적 특성 (Stochastic Nature): LLM은 확률을 기반으로 출력을 생성하므로 동일한 프롬프트에 대해서도 응답이 달라질 수 있음. 온도와 같은 매개변수는 변동성을 줄일 수 있지만, 이는 LLM의 설계 특성상 본질적인 속성이 됨.
- 오래된 정보 (Stale Information): LLM은 외부 데이터에 실시간으로 접근할 수 없음. 현재 사건이나 최신 연구, 현재 시간에 대한 정보도 알지 못하며, 훈련 데이터에 포함되지 않은 최신 정보는 제공할 수 없음.
- 크기와 비용 (Large and Costly): LLM은 매우 커서 훈련과 추론에 상당한 계산 자원을 필요로 함. 이는 종종 고성능 GPUs(그래픽 처리 장치)가 필요하게 되어, 비용과 지연 시간 측면에서 문제가 될 수 있음.
- 환각 (Hallucinations): LLM에서 가장 중요한 문제 중 하나는 '환각'임. 이는 모델이 그럴듯하지만 사실과 일치하지 않는 또는 근거 없는 답변을 생성하는 현상임.
이러한 한계들은 LLM을 사용하는 데 영향을 미치지만, hallucinations(환각) 문제는 최근에 큰 관심을 받고 있으며, 이를 완화하기 위한 여러 전략들이 개발됨.
LLM의 환각 (Hallucinations in LLMs)
LLM에서의 '환각'은 제공된 자료와 모순되는 콘텐츠를 생성하거나, 사실적으로 부정확하거나 확인할 수 없는 내용을 생성하는 현상임. 환각은 크게 두 가지 유형으로 나눌 수 있음:
- 내재적 환각 (Intrinsic Hallucinations): 이는 출처와 직접적으로 충돌하는 콘텐츠를 생성하는 것으로, 사실적 부정확성이나 논리적 불일치 등을 포함함.
- 외재적 환각 (Extrinsic Hallucinations): 이는 출처와 모순되지 않지만, 확인할 수 없거나 추측적인 요소를 포함하는 경우로, 검증할 수 없는 내용을 도입할 수 있음.
'출처'라는 개념은 환각의 맥락에서 다르게 해석될 수 있음. 예를 들어, 대화형 작업에서는 출처가 세계 지식(World Knowledge)일 수 있고, 텍스트 요약에서는 입력 텍스트(Input Text) 자체가 출처가 될 수 있음.
환각은 사실의 정확성이 중요한 작업에서 문제를 일으킬 수 있음. 그러나 창의적인 작업(예: storytelling(이야기 생성), poem generation(시 생성))에서는 환각이 허용되거나 심지어 유용할 수도 있음.
최근의 발전(예: Reinforcement Learning from Human Feedback (RLHF)(인간 피드백을 통한 강화 학습) 및 instruction tuning(지시 튜닝))은 LLM을 더 사실적인 출력을 생성하도록 유도하고자 했지만, LLM의 확률적 특성으로 인해 완전한 정확성을 보장하는 것은 여전히 어렵다고 할 수 있음. "Inference Tasks에서 LLM의 환각 원인(Sources of Hallucination by Large Language Models on Inference Tasks)"과 같은 연구는 '진실성 우선'(veracity prior) 및 '상대적 빈도 휴리스틱'(relative frequency heuristic)과 같은 근본적인 원인들을 밝혀냄.
B. 외부 지식을 통한 LLM 증강 – RAG (Retrieval-Augmented Generation)
환각을 완화하고 LLM의 능력을 향상시키기 위한 증강 방법으로 검색 기반 생성(RAG) 기법이 개발됨. RAG는 LLM의 생성 과정 중에 외부 지식 소스(예: databases(데이터베이스), search engines(검색 엔진), knowledge graphs(지식 그래프))를 통합하여 사용함. 외부 소스에서 관련 정보를 검색하여 이를 생성된 출력에 반영함으로써, LLM은 정확성, 관련성 및 신뢰성을 향상시킬 수 있음.
RAG 시스템의 주요 구성 요소는 다음과 같음:
- 검색 (Retrieval): 외부 소스에서 관련 데이터를 검색하는 단계임.
- 생성 (Generation): 관련 정보를 검색한 후, LLM은 프롬프트와 외부 데이터를 바탕으로 응답을 생성함.
- 증강 (Augmentation): 생성된 출력은 외부 소스에서 얻은 추가 정보나 세부사항을 통해 더욱 풍부하고 정확한 답변을 제공함.
RAG 도구에는 LangChain, HayStack, LlamaIndex와 같은 프레임워크가 있으며, 이들 도구는 LLM이 외부 데이터 소스와 원활하게 연결될 수 있도록 해줌. 이를 통해 LLM의 지식을 증강하고 환각 위험을 줄일 수 있음.
C. 외부 도구 사용 (Using External Tools)
LLM은 외부 도구로 증강될 수 있으며, 이는 그들의 기능적 능력을 확장하는 데 도움이 됨. 이러한 도구에는 다음이 포함될 수 있음:
- APIs(API): 외부 시스템이나 데이터 소스에 접근할 수 있는 방법임.
- Databases(데이터베이스): 구조화된 또는 비구조화된 데이터를 검색하는 데 사용됨.
- Knowledge Graphs(지식 그래프): 상호 연결된 사실과 관계를 활용하는 방법임.
이 도구들의 접근은 LLM이 실시간 정보에 접근할 수 있게 하여 최신 데이터를 반영한 답변을 생성할 수 있도록 함.
D. LLM 에이전트 (LLM Agents)
LLM을 증강하는 고급 접근 방식 중 하나는 LLM 기반 에이전트를 만드는 것임. 이러한 에이전트는 외부 환경과 상호작용하여 작업을 자율적으로 수행할 수 있는 AI systems(AI 시스템)임. 이들은 외부 시스템과 인터페이스하고, 의사 결정을 내리며, 외부 도구, API 및 데이터베이스를 활용하여 복잡한 작업 흐름을 완료할 수 있음.
LLM 기반 에이전트의 기능은 일반적으로 다음을 포함함:
- 도구 접근 및 활용 (Tool Access and Utilization): 에이전트는 외부 도구를 사용하여 정보를 수집하거나 작업을 수행할 수 있음(예: 데이터베이스 쿼리, 이메일 전송).
- 의사 결정 (Decision Making): 에이전트는 수집된 정보, 이전 경험 및 미리 정의된 목표를 바탕으로 의사 결정을 내릴 수 있음.
- 프롬프트 엔지니어링 (Prompt Engineering): 특수한 프롬프트가 에이전트의 의사 결정 과정을 안내하여 작업을 정확하게 수행하도록 함.
에이전트를 위한 프롬프트 기법 (Prompting Techniques for Agents)
고급 프롬프트 엔지니어링은 LLM 기반 에이전트를 안내하는 데 중요함. 주요 기법은 다음과 같음:
- RAG 인식 프롬프트 (RAG-aware Prompting): 에이전트가 먼저 관련 정보를 검색한 후 응답을 생성하도록 유도하는 프롬프트임.
- 도구 인식 프롬프트 (Tool-aware Prompting): 에이전트가 작업을 수행할 때 특정 도구나 API를 사용하도록 유도하는 프롬프트임.
이러한 기법을 통해 LLM은 더 구조적이고 목적 있는 방식으로 행동하며, 외부 리소스를 활용하고 작업을 자율적으로 수행할 수 있음.
환각 정량화 (Hallucination Quantification)
환각을 정량화하고 LLM 성능을 향상시키기 위해 다양한 metrics(측정 지표)가 사용됨. 여기에는 다음이 포함됨:
- 통계적 지표 (Statistical Metrics): ROUGE와 BLEU와 같은 지표는 생성된 콘텐츠가 실제와 얼마나 유사한지를 측정함.
- 모델 기반 지표 (Model-Based Metrics): QA-Based Metrics(QA 기반 지표)와 NLI-Based Metrics(NLI 기반 지표)는 생성된 출력이 기대되는 결과와 얼마나 일치하는지 평가함.
- 인간 평가 (Human Judgment): scoring(평점) 또는 comparative analysis(비교 분석)을 통해 환각을 평가하는 것이 여전히 중요함, 특히 복잡하거나 주관적인 작업에서 그렇다고 할 수 있음.
FactScore와 PARENT와 같은 노력들은 LLM 출력의 사실적 정확성을 평가하는 자동화된 방법을 개발하는 것을 목표로 하며, 생성된 콘텐츠를 "원자적 사실 (atomic facts)"로 분해하고 이를 신뢰할 수 있는 출처와 비교함.
프롬프트 설계 및 엔지니어링 (Prompt Design and Engineering)
효과적인 프롬프트 엔지니어링은 LLM이 원하는 출력을 생성하는 데 매우 중요함. 이 분야에서의 주요 접근법은 다음과 같음:
- 사고의 연쇄 (Chain of Thought, CoT): LLM이 답에 도달하기 위해 논리적 단계들을 따르도록 유도하여 응답의 구조를 개선함.
- 사고의 나무 (Tree of Thought, ToT): LLM이 여러 가지 가능한 사고 경로를 탐색한 후 가장 그럴듯한 결과에 도달하도록 유도함.
- 자기 일관성 (Self-Consistency): 여러 응답을 생성하고 일관성을 확인하여 신뢰성을 개선하는 방법임.
- 반영 (Reflection): 모델이 자신의 출력을 평가하고 정확성 및 일관성을 바탕으로 수정하는 방법임.
- 전문가 프롬프트 (Expert Prompting): 특정 분야의 전문 지식을 시뮬레이션하도록 유도하여 출력의 품질을 향상시킴.
- 체인 (Chains): 복잡한 작업을 해결하기 위한 일련의 상호 연결된 단계들로 나누어주는 방법임.
E. LLM 에이전트 (LLM Agents)
AI 에이전트의 개념은 AI 역사에서 잘 탐구되어 왔음. 에이전트는 일반적으로 환경을 센서를 통해 인식하고, 현재 상태를 바탕으로 판단을 내리며, 그에 따라 가능한 행동을 수행하는 자율적인 존재임.
LLM(대형 언어 모델) 맥락에서, 에이전트는 특정 작업을 자율적으로 수행할 수 있는 증강된 LLM의 특수한 구현을 기반으로 한 시스템을 의미함. 이러한 에이전트는 사용자 및 환경과 상호작용하여 입력과 상호작용의 목표에 따라 결정을 내릴 수 있도록 설계됨. 에이전트는 도구에 접근하고 이를 사용할 수 있는 능력을 갖춘 LLM을 기반으로 하며, 주어진 입력을 바탕으로 결정을 내리는 기능을 수행함. 이들은 단순한 응답 생성 이상의 자율성과 의사결정이 필요한 작업을 처리할 수 있도록 설계됨.
일반적인 LLM 기반 에이전트의 기능
- 도구 접근 및 활용 (Tool Access and Utilization): 에이전트는 외부 도구와 서비스에 접근할 수 있으며, 이를 효과적으로 활용하여 작업을 수행할 수 있음.
- 의사결정 (Decision Making): 입력, 문맥 및 사용할 수 있는 도구를 바탕으로 결정을 내릴 수 있으며, 종종 복잡한 추론 과정을 포함함.
예를 들어, 날씨 API와 같은 기능에 접근할 수 있는 LLM은 특정 장소의 날씨와 관련된 모든 질문에 답할 수 있음. 다시 말해, LLM은 API를 활용하여 문제를 해결할 수 있음. 또한, LLM이 구매 기능을 수행할 수 있는 API에 접근할 수 있다면, 구매 에이전트를 구축하여 외부 세계에서 정보를 읽고, 그 정보를 바탕으로 실제 행동을 할 수 있음.
그림 40은 대화형 정보 검색을 위한 LLM 기반 에이전트의 또 다른 예를 보여줌. 이 경우 LLM은 작동 기억 (working memory), 정책 (policy), 동작 실행자 (action executor), 유틸리티 (utility) 등 여러 플러그인 모듈이 추가되어 있음. 작동 기억은 대화 상태를 추적하며, 정책은 작업을 위한 실행 계획을 세우고, 동작 실행자는 정책이 선택한 동작을 수행하고, 유틸리티는 LLM의 응답이 사용자 기대나 특정 비즈니스 요구에 얼마나 부합하는지 확인하여 피드백을 제공하고 에이전트 성능을 개선함.
논문의 내용이 길어 나누어 정리하였다.
2025.03.16 - [분류 전체보기] - [논문 리뷰] Large Language Models: A Survey 2
[논문 리뷰] Large Language Models: A Survey 2
이 리뷰는 오직 학습과 참고 목적으로 작성되었으며, 해당 논문을 통해 얻은 통찰력과 지식을 공유하고자 하는 의도에서 작성된 것입니다. 본 리뷰를 통해 수익을 창출하는 것이 아니라, 제 학
c0mputermaster.tistory.com
논문 출처
S. Minaee, T. Mikolov, N. Nikzad, M. Chenaghlu, R. Socher, X. Amatriain, and J. Gao, "Large Language Models: A Survey," arXiv preprint arXiv:2402.06196, 2025. [Online]. Available:
https://arxiv.org/abs/2402.06196
Large Language Models: A Survey
Large Language Models (LLMs) have drawn a lot of attention due to their strong performance on a wide range of natural language tasks, since the release of ChatGPT in November 2022. LLMs' ability of general-purpose language understanding and generation is a
arxiv.org
'LLM > Paper reviews' 카테고리의 다른 글
| [논문 리뷰] Large Language Models: A Survey 2 (0) | 2025.03.16 |
|---|---|
| [논문 리뷰] Were RNNs All We Needed? (3) | 2025.01.19 |