이 리뷰는 오직 학습과 참고 목적으로 작성되었으며, 해당 논문을 통해 얻은 통찰력과 지식을 공유하고자 하는 의도에서 작성된 것입니다. 본 리뷰를 통해 수익을 창출하는 것이 아니라, 제 학습과 연구를 위한 공부의 일환으로 작성되었음을 미리 알려드립니다.
이 논문 "Were RNNs All We Needed?"는 시퀀스 모델링에서 Transformer 모델과 Recurrent Neural Networks (RNNs)의 효과를 비교하는 내용을 다룬다. LSTM과 GRU 모델을 단순화하여, 효율적이고 경쟁력 있는 성능을 달성할 수 있다는 점을 보여주고. Transformer 모델이 항상 최선의 선택이 아닐 수 있음을 보여주는데 주제가 흥미로워서 리뷰하게 되었다. 자연어처리(NLP) 모델에 대한 내용이지만 꽤나 참고할만한 논문이였다.
L. Feng, F. Tung, M. O. Ahmed, Y. Bengio, and H. Hajimirsadeghi, "Were RNNs All We Needed?," arXiv, 2024. [Online]. Available: https://arxiv.org/abs/2410.01201.
Abstract
2017년 Transformer의 도입은 딥러닝 분야의 판도를 바꾸었습니다. 원래 시퀀스 모델링을 위해 제안된 Transformer는 이후 여러 분야에서 광범위한 성공을 거두었습니다. 그러나 Transformer의 시퀀스 길이에 대한 확장성 한계는 훈련 중 병렬 처리가 가능하고, 비교 가능한 성능을 제공하며, 더 효과적으로 확장할 수 있는 새로운 순환 모델에 대한 관심을 불러일으켰습니다. 본 연구에서는 시퀀스 모델링을 역사적인 관점에서 재조명하며, Transformer의 등장 이전 20년간 해당 분야를 지배했던 순환 신경망(RNNs)을 집중적으로 살펴봅니다. 특히 LSTM(1997)과 GRU(2014)를 중심으로 연구합니다. 우리는 이 모델들을 단순화하여 최소화된 버전(minLSTM, minGRU)을 도출할 수 있음을 보입니다. 이러한 최소화된 모델은 (1) 기존 모델보다 적은 파라미터를 사용하고, (2) 훈련 중 완전 병렬 처리가 가능하며, (3) 여러 과제에서 놀라운 성과를 내며 최근 모델인 Transformer와도 경쟁할 수 있음을 증명합니다.
Introduction
본 연구에서는 1990년대부터 시퀀스 모델링 작업에서 중요한 역할을 했던 순환 신경망(RNNs), 특히 LSTM과 GRU를 재조명합니다. RNN들은 순차적 특성으로 인해 병렬화가 어려워 긴 시퀀스를 다룰 때 비효율적이었습니다. 그러나 2017년 Transformer의 도입으로 자기-주의 메커니즘을 통해 병렬 훈련이 가능해졌고, 이는 다양한 분야에서 성공을 거두었습니다. 하지만 Transformer는 긴 시퀀스를 처리할 때 계산 복잡도가 커지는 단점이 있어, 효율성을 높이기 위한 여러 방법이 연구되었습니다.
이에 대응하여 본 연구에서는 LSTM과 GRU의 단순화를 통해 병렬 훈련이 가능하고, 적은 파라미터로도 뛰어난 성능을 발휘하는 최소화된 버전(minLSTM, minGRU)을 제시합니다. 이 모델들은 기존의 복잡한 아키텍처 대신 간단하고 효율적인 방식으로 여러 과제에서 경쟁력 있는 성과를 보이며, Transformer의 확장성 한계를 극복하려는 새로운 접근 방식을 제시합니다.
Background
이 섹션에서는 전통적인 순환 신경망(RNNs)을 리뷰합니다. RNN은 시간 단계에 걸쳐 숨겨진 상태를 유지하며, 이를 통해 시간적 의존성을 캡처하는 시퀀스 모델입니다. 이로 인해 RNN은 시계열 예측, 자연어 처리와 같은 순차적 데이터 처리 작업에 특히 적합합니다. 이러한 작업에서는 이전 단계의 정보가 현재 예측에 중요한 역할을 합니다. 그러나 기본적인 RNN(Elman, 1990)은 기울기 소실과 폭주 문제를 겪어 장기적인 의존성을 학습하는 데 한계가 있습니다.
2.1 LSTM
LSTM(Long Short-Term Memory)은 1997년에 도입된 순환 신경망(RNN)의 한 종류로, 기울기 소실 문제를 해결하고 장기적인 의존성을 잘 처리할 수 있도록 설계되었습니다. LSTM은 입력 데이터와 이전 상태 정보를 바탕으로 여러 개의 "게이트"라는 구조를 사용해 중요한 정보를 선택적으로 기억하거나 잊습니다. 이를 통해 모델이 긴 시퀀스에서도 중요한 정보를 잃지 않고 효과적으로 학습할 수 있습니다. LSTM은 두 개의 상태를 관리하는데, 하나는 정보를 저장하는 '셀 상태'이고, 다른 하나는 출력을 생성하는 '숨겨진 상태'입니다. 이 구조는 많은 파라미터를 필요로 하지만, 장기적인 의존성을 잘 처리할 수 있다는 장점이 있습니다.

2.2 GRU
GRU(Gated Recurrent Unit)는 LSTM을 단순화한 모델로, LSTM보다 적은 수의 게이트와 상태를 사용합니다. GRU는 LSTM의 '망각 게이트'와 '입력 게이트'를 하나로 합친 '업데이트 게이트'만 사용하고, '출력 게이트'를 없앴습니다. 대신 '리셋 게이트'라는 또 다른 게이트를 추가하여 이전 숨겨진 상태를 얼마나 반영할지 결정합니다. 이렇게 단순한 구조 덕분에 GRU는 LSTM보다 훈련이 더 빠르고, 메모리와 계산 자원을 덜 소모합니다.
2.3 Parallel Scan
기존의 RNN 모델들은 훈련 과정에서 데이터를 순차적으로 처리해야 해서 병렬화가 어렵고, 긴 시퀀스를 처리할 때 느리고 비효율적입니다. 반면, Transformer는 데이터를 병렬로 처리할 수 있어 이 문제를 해결했지만, 여전히 긴 시퀀스를 처리할 때 계산 비용이 매우 높습니다. 이를 해결하기 위해 최근에는 병렬화가 가능한 새로운 순환 모델들이 등장하고 있으며, 그 중 일부는 '병렬 접두사 스캔(parallel prefix scan)' 알고리즘을 사용합니다. 이 알고리즘은 시퀀스 데이터를 효율적으로 처리할 수 있게 도와주며, 병렬 훈련을 가능하게 만들어 기존 모델들이 가지던 시퀀스 처리의 한계를 극복하려고 합니다.
3. 방법론
이 섹션에서는 GRU와 LSTM의 모델을 병렬 훈련이 가능하도록 단순화하는 방법을 설명합니다. 우리가 제시하는 방식은 GRU와 LSTM의 기존 모델에서 "이전 상태"에 의존하는 부분을 제거하고, 병렬 스캔 방식을 사용하여 훈련할 수 있도록 만드는 것입니다. 또한, 이를 바탕으로 최소화된 버전(minGRU, minLSTM)을 제시하여 더 효율적이고 간단하게 훈련할 수 있도록 합니다.
3.1 최소화된 GRU: minGRU
3.1.1 단계 1: 이전 상태 의존성 제거
기존의 GRU는 숨겨진 상태를 업데이트할 때, 이전 상태를 고려하여 계산을 진행합니다. 그러나 이전 상태에 의존하는 방식은 병렬로 처리하기 어렵습니다. 그래서 우리는 GRU에서 이전 상태와의 의존성을 없애기로 했습니다. 즉, 각 계산을 할 때 이제 이전 상태를 고려하지 않고, 현재 입력만을 사용하여 계산을 하도록 바꿨습니다. 이렇게 하면 병렬로 계산할 수 있게 되어 훨씬 빠르고 효율적인 훈련이 가능합니다.
3.1.2 단계 2: 후보 상태의 범위 제한 제거
GRU는 계산 중에 숨겨진 상태의 값을 일정 범위로 제한하는데, 이 제한은 훈련의 안정성을 위해 사용됩니다. 하지만 이전 단계에서 이미 상태 의존성을 제거했으므로, 후보 상태의 범위 제한도 더 이상 필요하지 않게 되었습니다. 그래서 이 제한을 없애고, 후보 상태를 더 자유롭게 계산할 수 있도록 단순화했습니다. 이 변화로 GRU는 더 간단하고 효율적인 방식으로 작동하게 됩니다.
결과적으로, 이렇게 수정된 GRU는 이전 상태와의 의존성을 없애고, 후보 상태의 범위 제한을 제거함으로써 병렬 훈련이 가능하고, 더 빠르고 효율적인 모델로 거듭날 수 있습니다.
3.1.3 minGRU
위에서 설명한 두 단순화 단계를 결합하여 minGRU라는 최소화된 GRU 버전을 만들었습니다. 이를 통해 모델이 훨씬 더 효율적이 되었으며, 필요로 하는 파라미터 수가 크게 줄어들었습니다. 기존 GRU는 O(3dh(dx + dh))의 파라미터를 요구했으나, minGRU는 O(2dh dx)로 파라미터 수가 줄어듭니다. 예를 들어, 입력 크기(dx)에 비례해 모델의 파라미터 수가 약 33%, 22%, 17%, 13%로 줄어듭니다. 또한, minGRU는 병렬 학습이 가능해져, 시간 역전파(backpropagation through time, BPTT) 없이 훈련할 수 있습니다.
3.2 A Minimal LSTM: minLSTM
3.2.1 단계 1: 이전 상태 의존성 제거
기존 LSTM에서는 셀 상태를 업데이트할 때, 이전 상태의 의존성으로 인해 병렬 처리가 불가능했습니다. 이 문제를 해결하기 위해 이전 상태 의존성을 제거하고, 현재 입력만을 사용하여 셀 상태를 업데이트하도록 했습니다. 이를 통해 병렬 학습이 가능하게 되었습니다.
3.2.2 단계 2: 후보 상태의 범위 제한 제거
LSTM은 원래 후보 상태와 숨겨진 상태의 값을 -1과 1 사이로 제한하는 "tanh" 함수를 사용합니다. 이를 통해 훈련 안정성을 높였지만, 이제 이러한 제한을 제거하여 모델을 단순화했습니다.
3.2.3 단계 3: 출력 스케일 단순화
LSTM에서 "출력 게이트"는 숨겨진 상태를 스케일링하는 데 사용되었으나, 이를 제거함으로써 숨겨진 상태가 셀 상태와 동일하게 되도록 했습니다. 이렇게 해서 셀 상태와 숨겨진 상태를 동시에 유지할 필요가 없게 되었고, 모델이 더 간단해졌습니다.
3.2.4 minLSTM
이 세 가지 단계를 결합하여 minLSTM을 만들었습니다. 이 모델은 기존 LSTM보다 훨씬 적은 파라미터(O(3dh dx))를 사용하고, 병렬 학습이 가능하며, 시간에 독립적인 출력 값을 제공합니다. 또한, minLSTM은 BPTT 없이 훈련할 수 있습니다.
결과적으로 minGRU와 minLSTM은 전통적인 GRU와 LSTM보다 훨씬 더 효율적이고, 훈련이 빠르며, 메모리 사용량도 적습니다. 이를 통해 기존의 복잡한 모델을 대체할 수 있는 경쟁력 있는 대안을 제시합니다.

정리하자면
이 연구에서는 LSTM과 GRU 모델을 간소화하여 minLSTM과 minGRU를 제안했습니다. 두 모델 모두 기존의 복잡한 구조에서 파라미터 수를 크게 줄이고, 병렬 학습을 가능하게 하여 훈련 속도를 개선했습니다. 주요 개선점은 다음과 같습니다:
- 이전 상태 의존성 제거: 기존의 GRU와 LSTM은 이전 상태에 의존해 병렬 학습이 불가능했으나, 이를 제거해 병렬화가 가능하게 했습니다.
- 범위 제한 제거: 후보 상태와 숨겨진 상태의 값에 대한 범위 제한을 없애 더 간단한 모델을 만들었습니다.
- 출력 스케일 단순화: LSTM에서 필요했던 출력 게이트를 제거하여 모델을 더욱 단순화했습니다.
결과적으로 minGRU와 minLSTM은 기존 모델보다 훨씬 적은 파라미터와 빠른 훈련 속도, 낮은 메모리 사용을 자랑하며, BPTT 없이 병렬 학습이 가능합니다.
4.1 Minimal LSTMs and GRUs are efficient
이 섹션에서는 minLSTM과 minGRU 모델이 전통적인 LSTM과 GRU 모델보다 훈련에서 더 효율적임을 비교합니다. 주로 훈련 시간과 메모리 사용량을 중심으로 비교가 이루어졌습니다.
- 훈련 시간:
- minLSTM과 minGRU는 전통적인 LSTM과 GRU보다 훨씬 빠릅니다. 예를 들어, 512 길이의 시퀀스에서 minLSTM은 기존 LSTM보다 235배 빠르고, 4096 길이에서는 1361배 더 빠릅니다. 이는 BPTT 없이 병렬 학습을 가능하게 하기 때문입니다.
- minGRU와 minLSTM은 훈련을 3년이 걸릴 작업을 하루 안에 끝낼 수 있습니다.
- 메모리 사용량:
- minLSTM과 minGRU는 병렬 계산을 위해 더 큰 계산 그래프를 생성하며, 그 결과 기존 모델보다 약 88% 더 많은 메모리를 사용합니다.
- Mamba는 minGRU보다 56% 더 많은 메모리를 사용합니다.
- 시간 의존성 제거:
- minLSTM과 minGRU는 이전 상태 ht−1의 의존성을 제거하여 모델을 단순화했습니다. 이로 인해 단일 레이어에서는 시간에 의존하지 않지만, 여러 레이어를 쌓으면 모델이 점차적으로 복잡해지고 시간 의존성을 다시 학습하게 됩니다.
- 모델 성능:
- Select Copying Task에서 minLSTM과 minGRU는 레이어 수를 증가시킬수록 성능이 크게 향상됩니다.
- minGRU는 minLSTM보다 더 안정적이고 일관성 있게 문제를 해결합니다.
결론적으로, minLSTM과 minGRU는 훈련 효율성과 메모리 사용량에서 큰 장점을 보이며, 특히 긴 시퀀스를 다룰 때 효과적입니다.
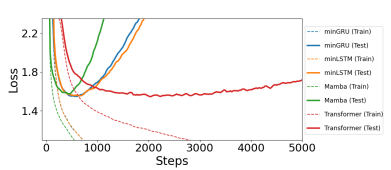
minLSTM과 minGRU가 다양한 작업에서 경쟁력 있는 성능을 보임을 보여줍니다. 주요 내용은 다음과 같습니다:
- Selective Copying Task:
- minLSTM과 minGRU는 최신 모델인 **Mamba (S6)**와 비교해도 뒤지지 않는 성능을 보입니다. 이들 모델은 Selective Copying Task를 완벽하게 해결하며, S4나 Hyena 등 다른 최신 모델들보다 성능이 우수합니다 (표 2).
- Reinforcement Learning:
- D4RL 벤치마크에서 minLSTM과 minGRU는 Decision Transformer나 Mamba와 비슷한 수준의 성능을 보입니다. 특히 minLSTM과 minGRU는 Decision S4보다 뛰어난 성능을 기록하며, 전체적으로 평균 점수에서 높은 성과를 보였습니다 (표 3).
- Language Modeling:
- Shakespeare 데이터셋을 이용한 언어 모델링에서 minLSTM과 minGRU는 Mamba와 Transformer 모델들과 비슷한 성능을 보입니다. 특히 minGRU는 Transformer보다 훈련 속도가 빠르며, Transformer는 minGRU보다 약 2.5배 더 많은 훈련 단계를 필요로 했습니다. minGRU와 minLSTM은 Transformer보다 더 적은 훈련 단계에서 비슷한 성능을 달성합니다 (그림 2).
결론적으로, minLSTM과 minGRU는 Mamba나 Transformer와 같은 최신 모델들과 비슷한 성능을 보이며, 더 적은 리소스를 사용하면서도 효율적이고 경쟁력 있는 성과를 냅니다.
Related Work
이 섹션에서는 최근의 효율적인 순차 모델들에 대해 설명하고 있습니다. 이 모델들은 Transformers와 경쟁할 수 있는 성능을 보이면서도 더 나은 확장성을 제공하는 모델들입니다. 특히, 이 모델들은 다음과 같은 세 가지 주요 방향으로 발전해 왔습니다:
- (Deep) State-Space Models (SSMs):
- S4와 같은 State-Space Model (SSM)은 연속 시간 선형 시스템을 기반으로 하며, Mamba는 이러한 모델에서 중요한 발전을 이룬 사례로, 이전 모델들과 달리 입력 의존적 전이 행렬을 사용하여 뛰어난 성과를 보였습니다. 이 모델들은 언어 처리와 오디오 분석 등 다양한 분야에서 활용되고 있습니다. Mamba의 S6 모델은 특히 큰 주목을 받으며, 이에 대한 여러 종합적인 논문들이 발표되었습니다.
- Recurrent Versions of Attention:
- 최근에는 선형 주의(linear attention)와 관련된 모델들이 주목받고 있습니다. 선형 주의 모델들은 입력 독립적인 게이팅 메커니즘을 사용하는 모델들로, 입력 의존적인 게이팅을 사용하는 모델들도 제안되었습니다. 최근 softmax attention을 RNN처럼 볼 수 있다는 연구도 나왔습니다. 이는 RNN의 기반 위에서 주의 메커니즘을 개선하려는 방향입니다.
- Parallelizable RNNs:
- RNN 병렬화와 관련된 여러 연구들이 있습니다. 예를 들어, Bradbury et al. (2017)은 전통적인 RNN을 합성곱(convolutional) 레이어와 결합하여 효율성을 높이는 방법을 제안했으며, Martin & Cundy (2018)는 선형 의존성을 가진 RNN을 병렬로 학습할 수 있는 방법을 보여주었습니다. minGRU는 GILR이라는 선형 gated RNN을 기반으로 하여 활성화 함수 없이 병렬 훈련을 가능하게 합니다. 최근 HGRN 모델과 HGRN2는 더 복잡한 값의 회귀와 상태 확장을 결합하여 성능을 개선했습니다. 또한 xLSTM은 병렬화 가능한 버전과 순차 전용 버전을 사용하여 성능을 향상시켰습니다.
이러한 연구들은 전통적인 RNN의 한계를 넘어 효율적이고 병렬화 가능한 모델을 제시하며, 기존의 RNN 기반 모델들이 다양한 분야에서 강력한 경쟁력을 가지게 만드는 데 기여하고 있습니다.
리뷰 후기
논문은 전통적인 모델들이 여전히 효과적일 수 있음을 보여주고, 최신 모델들과 비교했을 때 좋은 성능을 나타낼 수 있다는 점을 강조하고 있다. NLP 분야에 익숙하지 않지만, 연구의 흐름과 결과가 직관적으로 이해될 수 있어 유익한 논문이라고 생각했다. 아래 포스트는 우연히 발견하였는데 참고하면 좋을 것 같아서 메모해 놓았다.
https://velog.io/@tbvjvsladla/2.-NLP-Were-RNN-All-We-Needed
2. NLP - Were RNN All We Needed?
개요 본 블로그 포스팅은 수도권 ICT 이노베이션 스퀘어에서 진행하는 AI 핵심 기술 집중 클래스의 자연어처리(NLP) 강좌 내용을 필자가 다시 복기한 내용에 관한 것입니다. 0.논문 살짝요약 이 논
velog.io
출처
L. Feng, F. Tung, M. O. Ahmed, Y. Bengio, and H. Hajimirsadeghi, "Were RNNs All We Needed?," arXiv, 2024. [Online]. Available: https://arxiv.org/abs/2410.01201.
'LLM > Paper reviews' 카테고리의 다른 글
| [논문 리뷰] Large Language Models: A Survey 2 (0) | 2025.03.16 |
|---|---|
| [논문 리뷰] Large Language Models: A Survey 1 (0) | 2025.03.04 |