여러 자세 추정 모델을 경험 해보기 위해 우선 접근성이 쉬웠던 Ultralytics에 YOLO11 Pose모델을 사용해보았다.
Ultralytics YOLO11 포즈 추정 튜토리얼 | 실시간 오브젝트 추적 및 사람 포즈 감지
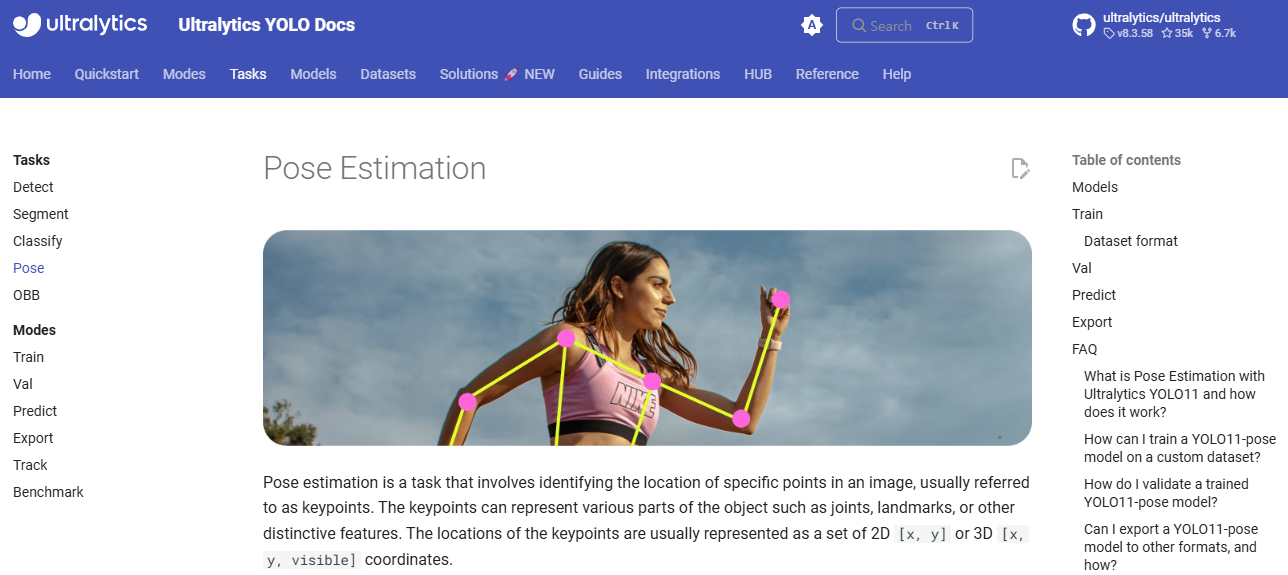
자세 추정 (Pose Estimation)이란?
- 자세 추정은 이미지에서 특정 지점을 식별하는 작업을 말하며, 이러한 지점은 일반적으로 키포인트라고 불립니다.
- 키포인트의 위치는 보통 2D [x, y] 또는 3D [x, y, visible] 좌표 세트로 표현.
- 자세 추정 모델의 출력은 이미지에서 객체의 키포인트를 나타내는 일련의 점이며, 보통 각 점에 대한 신뢰도 점수도 함께 제공됩니다.
- 자세 추정은 장면에서 객체의 특정 부분과 그 위치를 서로 관련 지어 식별해야 할 때 적합한 선택
YOLO11 Pose
YOLO11 포즈 모델은 -pose 접미사, 즉 yolo11n-pose.pt. 이 모델은 COCO 키포인트 데이터 세트를 사용하며 다양한 포즈 추정 작업에 적합합니다.
기본 YOLO11 포즈 모델에는 17개의 키포인트가 있으며, 각 키포인트는 인체의 다른 부분을 나타냅니다. 다음은 각 인덱스와 해당 신체 관절의 매핑입니다:
0: 코 1: 왼쪽 눈 2: 오른쪽 눈 3: 왼쪽 귀 4: 오른쪽 귀 5: 왼쪽 어깨 6: 오른쪽 어깨 7: 왼쪽 팔꿈치 8: 오른쪽 팔꿈치 9: 왼쪽 손목 10: 오른쪽 손목 11: 왼쪽 엉덩이 12: 오른쪽 엉덩이 13: 왼쪽 무릎 14: 오른쪽 무릎 15: 왼쪽 발목 16: 오른쪽 발목
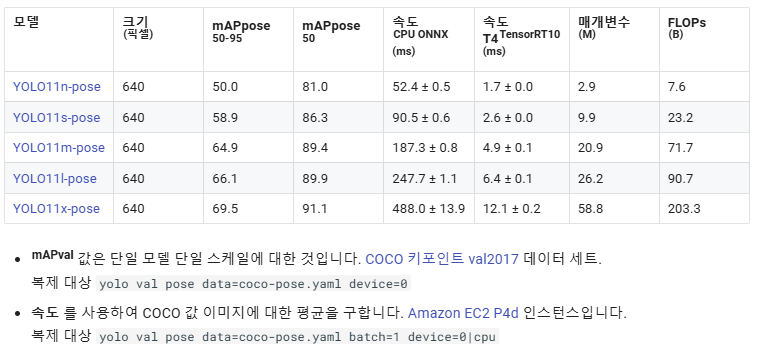
모델
YOLO11 사전 학습된 포즈 모델이 여기에 나와 있습니다. 감지, 세그먼트 및 포즈 모델은 COCO 데이터 세트에 대해 사전 학습된 반면, 분류 모델은 ImageNet 데이터 세트에 대해 사전 학습되었습니다.
훈련
COCO8-pose 데이터 세트에서 YOLO11-pose 모델을 훈련할 수있다는데 YOLO 모델을 통해 포즈 추적 모델을 훈련하고 COCO8-pose 데이터셋을 사용하고, 이를 YOLO 형식으로 변환할 수 있다는 이야기 같다.
- 모델 로드:
- YOLO("yolo11n-pose.yaml"): 새 모델을 YAML 파일을 통해 생성.
- YOLO("yolo11n-pose.pt"): 훈련된 모델을 가중치를 통해 로드.
- YOLO("yolo11n-pose.yaml").load("yolo11n-pose.pt"): 모델을 빌드하고 기존 훈련된 가중치를 적용.
- 모델 훈련:
- model.train(data="coco8-pose.yaml", epochs=100, imgsz=640):
- data="coco8-pose.yaml": 데이터셋 파일.
- epochs=100: 100번 에포크로 훈련.
- imgsz=640: 640x640 이미지 크기.
- model.train(data="coco8-pose.yaml", epochs=100, imgsz=640):
- 데이터셋 형식:
- YOLO 포즈 데이터셋 형식을 사용.
- COCO와 같은 다른 데이터셋을 YOLO 형식으로 변환하려면 JSON2YOLO 도구를 사용.
from ultralytics import YOLO
# 모델 로드
model = YOLO("yolo11n-pose.yaml") # YAML에서 새 모델 빌드
model = YOLO("yolo11n-pose.pt") # 사전 훈련된 모델 로드 (훈련 권장)
model = YOLO("yolo11n-pose.yaml").load("yolo11n-pose.pt") # YAML에서 빌드 후 가중치 전달
# 모델 훈련
results = model.train(data="coco8-pose.yaml", epochs=100, imgsz=640)
https://blog.roboflow.com/train-a-custom-yolov8-pose-estimation-model/
How to Train a Custom Ultralytics YOLOv8 Pose Estimation Model
In this guide, we walk through how to train a custom YOLOv8 pose estimation model with your own dataset.
blog.roboflow.com
키포인트 디텍션 커스텀 훈련하는 방법인데 참고하면 좋을 것 같다.
예측
https://docs.ultralytics.com/ko/modes/predict/
from ultralytics import YOLO
# 모델 로드
model = YOLO("yolo11n-pose.pt") # 공식 모델 로드
model = YOLO("path/to/best.pt") # 사용자 정의 모델 로드
# 모델로 예측 실행
results = model("https://ultralytics.com/images/bus.jpg") # 이미지에서 예측 실행
가상환경 세팅
전에 yolov11을 돌릴 때 사용하던 가상환경을 그대로 사용하였다
위 동영상 인도 형님이 친절하게 도와주심
boxes와 keypoints 타입 확인
1 boxes와 keypoints 타입 확인 YOLO 모델에서 추론한 첫 번째 사람의 결과를 확인해보았다. boxes는 ultralytics.engine.results.Boxes 타입이고, keypoints는 ultralytics.engine.results.Keypoints 타입인 걸 알 수 있었다. 이렇게 저장된 데이터는 사람의 위치와 신체 부위 위치를 포함하고 있었다.
result = results[0] # 첫 번째 사람의 이미지 추론 결과
boxes = result.boxes # bounding box 정보
keypoints = result.keypoints # keypoints 정보
print(type(boxes)) # <class 'ultralytics.engine.results.Boxes'>
print(type(keypoints)) # <class 'ultralytics.engine.results.Keypoints'>
2 keypoints.xy
keypoints.xy는 각 키포인트의 (x, y) 좌표를 픽셀 단위로 저장한 텐서인 걸 확인했다. 이 텐서의 크기는 [1, 17, 2]였고, 1명의 사람에 대해 17개의 신체 부위 좌표가 들어있었다. 각 좌표는 신체 부위의 위치를 정확히 나타내고 있었다.
xy = keypoints.xy
print(type(xy)) # <class 'torch.Tensor'>
print(xy.shape) # torch.Size([1, 17, 2])
3 keypoints.xyn
keypoints.xyn은 각 키포인트의 상대적인 위치를 비율로 저장하고 있었다. 예를 들어, 코의 상대적인 위치는 [0.4636, 0.1596]로, 이는 이미지 너비의 약 46.36%, 높이의 15.96% 위치임을 알 수 있었다.
xyn = keypoints.xyn
print(xyn) # 출력 예시: [[0.4636, 0.1596], [0.4800, 0.1313], ...]
4 keypoints.conf
keypoints.conf는 각 키포인트의 신뢰도를 나타내는 값으로, 값이 클수록 그 키포인트가 정확하다는 걸 알 수 있었다.
conf = keypoints.conf
print(conf) # 출력 예시: [0.9928, 0.9838, 0.9649, 0.9184, ...]
print(conf.shape) # torch.Size([1, 17])
사용해보기
from ultralytics import YOLO
import cv2
# YOLO 모델을 로드 (여기서는 자세 추정 모델을 로드한다고 가정)
model = YOLO("yolo11m-pose.pt") # pose 추정 모델을 로드
# 비디오 파일 경로 지정
video_path = "cam.mp4"
# 비디오 캡처 객체 생성
cap = cv2.VideoCapture(video_path)
# 비디오의 프레임 크기 및 FPS 정보 가져오기
frame_width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
frame_height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
fps = cap.get(cv2.CAP_PROP_FPS)
# 동영상 출력 객체 생성 (파일로 저장)
output_video_path = "output_video2.mp4"
fourcc = cv2.VideoWriter_fourcc(*'mp4v') # mp4 형식으로 저장
out = cv2.VideoWriter(output_video_path, fourcc, fps, (frame_width, frame_height))
# 키포인트 좌표를 저장할 텍스트 파일 열기
keypoints_file = open("keypoints.txt", "w")
keypoints2_file = open("keypoints2.txt", "w") # 새로운 파일 열기
# 비디오에서 프레임 하나씩 읽어오기
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
# 프레임을 모델에 넣어 예측 수행
results = model(frame) # 프레임을 모델에 넣어 예측
# 예측된 프레임을 출력
annotated_frame = results[0].plot() # 예측 결과가 그려진 프레임 얻기
# keypoints 추출
keypoints = results[0].keypoints # keypoints를 얻기
# keypoints.xy: (x, y) 좌표, keypoints.conf: 각 keypoint의 confidence
xy = keypoints.xy # 픽셀 좌표
conf = keypoints.conf # 신뢰도
# 각 키포인트의 좌표와 신뢰도를 텍스트 파일에 저장
keypoints_text = "Frame {} Keypoints:\n".format(int(cap.get(cv2.CAP_PROP_POS_FRAMES)))
for i in range(len(xy[0])): # 각 사람마다 반복
x, y = xy[0][i] # (x, y) 좌표
c = conf[0][i] # 각 키포인트의 신뢰도
# 텍스트 파일에 좌표와 신뢰도 저장
keypoints_text += "Keypoint {}: ({:.2f}, {:.2f}), Confidence: {:.2f}\n".format(i, x, y, c)
# 텍스트 파일에 키포인트 좌표 저장
keypoints_file.write(keypoints_text + "\n")
# Keypoints2.txt에 프레임 번호와 키포인트 좌표만 저장
frame_number = int(cap.get(cv2.CAP_PROP_POS_FRAMES)) # 현재 프레임 번호
keypoints2_text = f"{frame_number} " # 프레임 번호로 시작
# 17개의 키포인트 좌표를 한 줄로 저장
for i in range(len(xy[0])):
x, y = xy[0][i] # (x, y) 좌표
keypoints2_text += f"{x:.2f} {y:.2f} " # x, y 좌표를 추가
keypoints2_file.write(keypoints2_text.strip() + "\n") # 한 줄 끝에 공백을 없애고 저장
# 프레임을 동영상 파일로 저장
out.write(annotated_frame)
# 결과 화면에 표시 (선택 사항)
cv2.imshow('Annotated Frame', annotated_frame)
# 'q' 키를 누르면 종료
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# 자원 해제
cap.release()
out.release()
cv2.destroyAllWindows()
# 텍스트 파일 닫기
keypoints_file.close()
keypoints2_file.close()
캠을 이용해 모델을 구동하여보고 프레임별 keypoints를 텍스트 파일 형태로 저장해보았다.


참고
'Computer Vision > Project' 카테고리의 다른 글
| [Project] Spring Boot와 Flask를 이용해 모바일용 서버 구축 (0) | 2025.02.01 |
|---|---|
| [Raspberry Pi] 라즈베리파이에서 YOLO11 Pose 써보기 (7) | 2025.01.22 |
| [Raspberry Pi] 원격 접속 세팅과 실시간 USB CAM 사용 (7) | 2025.01.21 |
| [Pose Estimation] YOLO11 Pose를 이용한 간단한 애니매이션 만들기 (6) | 2025.01.06 |
| [Pose Estimation] OpenPose 써보기 (4) | 2025.01.03 |