1. Pandas 라이브러리란?

Pandas는 2009년에 오픈소스로 공개된 이후, 데이터 분석 및 가공을 위한 표준 라이브러리로 자리잡았음. 특히 데이터프레임을 활용하면 구조화된 데이터의 처리 및 변형이 용이해지며, 내부적으로 Cython(C++ 기반 최적화 코드)을 사용하여 빠른 속도를 제공함.
주요 활용 라이브러리:
- 산술 계산: NumPy, SciPy 등
- 데이터 분석: statsmodels, scikit-learn 등
- 시각화: Matplotlib, Seaborn 등
Pandas는 Anaconda, Google Colab 등의 환경에서 기본적으로 설치되어 있으며, 필요 시 pip install pandas를 통해 추가 설치할 수 있음.
import pandas as pd
# Pandas 현재 버전 확인
print(pd.__version__)2. Pandas 파일 입출력(I/O)
Pandas는 다양한 형식의 외부 데이터를 데이터프레임으로 쉽게 변환할 수 있는 강력한 I/O 기능을 제공함. 특히, JSON 파일을 다룰 때 유용함.
JSON 파일
Pandas의 read_json() 함수는 JSON 파일을 읽어와서 데이터프레임으로 변환하는 기능을 제공함. JSON 형식은 딕셔너리와 유사한 키-값 구조로 데이터를 저장하며, 계층적(중첩) 구조를 가질 수 있음.
주요 옵션:
- orient: JSON 데이터의 형식을 지정함. 기본값은 records로 각 JSON 객체가 데이터프레임의 행(row)으로 변환됨.
- lines=True: JSON Lines (NDJSON) 형식의 데이터를 처리할 때 사용함.
- index_col: 특정 열을 데이터프레임의 인덱스로 지정할 수 있음.
# JSON 파일을 읽어와서 데이터프레임으로 변환
df_json = pd.read_json('Magazine_Subscriptions.json', lines=True)
2.1. 데이터프레임 복사
Pandas에서는 copy() 함수를 사용하여 데이터프레임의 복사본을 만들 수 있음.
# 데이터프레임 복사본 생성
df = df_json.copy()
df
3. 데이터 탐색
3.1. 데이터의 일부만 확인: head(), tail()
- head(): 데이터프레임의 처음 n개의 행을 반환함. 기본적으로 5개의 행을 반환하지만, n 값을 입력하면 반환 개수를 조정할 수 있음.
- tail(): 데이터프레임의 마지막 n개의 행을 반환함.
# 처음 5개 행 출력
df.head()
# 마지막 10개 행 출력
df.tail(10)

3.2. 무작위 행 추출: sample()
- frac: 전체 데이터 중 몇 퍼센트를 추출할지 지정함.
# 무작위로 10개 행을 추출
df.sample(n=10)
# 무작위로 전체 데이터의 20%를 추출
df.sample(frac=0.2)
3.3. 차원 확인: shape()
데이터프레임의 차원을 나타내는 튜플을 반환함. 튜플의 첫 번째 요소는 행의 개수, 두 번째 요소는 열의 개수를 나타냄.
# 데이터프레임의 차원 확인
df.shape
3.4. 요약 정보: info()
데이터프레임의 상세 정보를 출력함. 데이터의 열 이름, 데이터 타입, 결측값 등을 확인할 수 있음.
# 데이터프레임의 상세 정보 출력
df.info()
3.5. 기초통계: describe()
데이터프레임의 숫자형 열에 대해 주요 기술 통계 정보를 요약하여 제공함. 기본적으로 평균(mean), 표준편차(std), 최솟값(min), 최댓값(max), 사분위수(25%, 50%, 75%) 등의 통계를 출력함. include='all' 옵션을 사용하면 숫자형이 아닌 열에 대한 정보도 포함하여 출력할 수 있음.
# 데이터프레임의 기초 통계 정보 출력
df.describe()
# 숫자형이 아닌 데이터도 포함하여 통계 정보 출력
df.describe(include='all')
3.6 비결측값 개수 계산: count()
count() 함수는 데이터프레임의 각 열에 대해 비결측값(non-NA/null)의 개수를 계산하여 시리즈 객체로 반환합니다.
# 각 열의 유효한 데이터 개수 출력
df.count()

3.7 고유값 계산: nunique()
nunique()는 데이터프레임이나 시리즈에서 고유값의 개수를 반환합니다.
# 'overall' 열의 고유값 개수
df['overall'].nunique()
3.8 고유값 빈도 계산: value_counts()
value_counts()는 각 고유값이 데이터 내에서 몇 번 나타나는지 계산합니다. 기본적으로 내림차순으로 정렬되어 반환됩니다.
# 'overall' 열의 고유값 빈도 계산
df["overall"].value_counts()
4. 행 서브셋 선택
4.1 조건에 맞는 행 선택: 조건식
조건식을 사용해 특정 조건을 만족하는 행을 선택할 수 있습니다.
# 평점이 3보다 큰 행 선택
df[df['overall'] > 3]
# 'vote' 열을 정수형으로 변환
df['vote'] = pd.to_numeric(df['vote'], errors='coerce')
# 평점이 3보다 크고 'vote' 열이 10개 이상인 행 선택
df[(df['overall'] > 3) & (df['vote'] > 10)]
여기서 df[(df['overall'] > 3) & (df['vote'] > 10)] 먼저 실행하면 'vote'열이 문자열로 되어있어 오류가 나기 때문에

'vote' 열을 정수형으로 변환해주고 실행하면 정상적으로 실행된다. df['vote'] = pd.to_numeric(df['vote'], errors='coerce')

4.2 조건에 맞는 행 선택: query()
query() 함수는 문자열 조건식을 사용해 데이터를 필터링할 수 있습니다.
# 평점이 3보다 큰 행 선택
df.query('overall > 3')
# 평점이 3보다 크고 vote 컬럼이 10개 이상인 행 선택
df.query('overall > 3 and vote > 10')
# reviewText 컬럼에 'good' 텍스트가 포함된 행만 선택
df.query('reviewText.str.contains("good", case=False, na=False)', engine='python')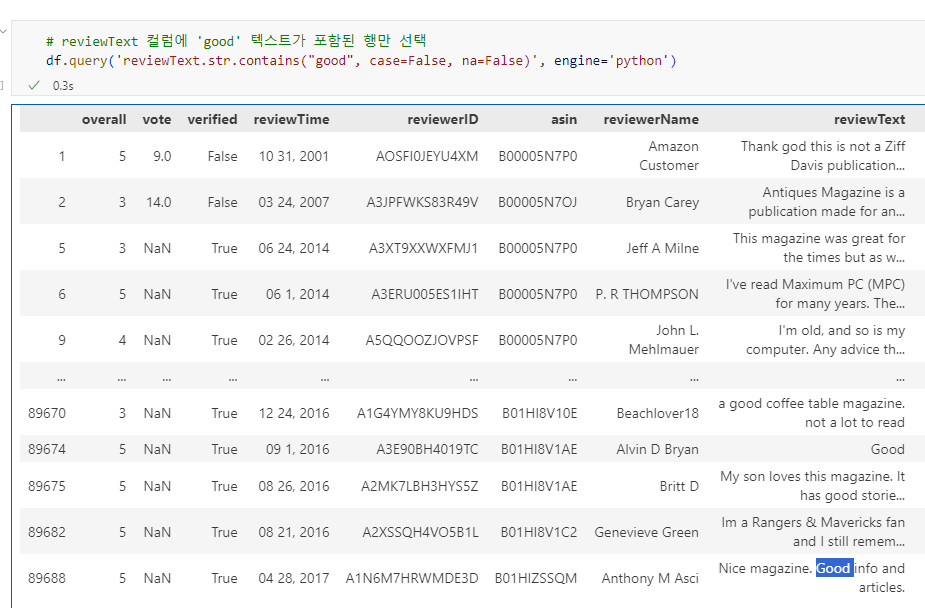
4.3 조건에 맞는 행 선택: isin()
isin() 함수는 특정 열에서 주어진 값이 포함된 행을 선택합니다.
# 'overall' 열 값이 5 또는 4인 행 출력
df[df['overall'].isin([4, 5])]
4.4 중복 행 제거: drop_duplicates()
중복된 데이터를 제거할 때 drop_duplicates()를 사용합니다.
# 'reviewText' 컬럼 기준으로 중복 행 제거
df.drop_duplicates(subset='reviewText')5. 특정 열 선택
5.1 단일 열 선택
단일 열을 선택할 때는 아래와 같이 두 가지 방법을 사용할 수 있습니다.
# 'reviewText' 열 선택
df['reviewText']
# 'reviewText' 열 선택 (점 표기법 사용)
df.reviewText
5.2 여러 컬럼 선택
여러 개의 열을 선택하려면 열 이름을 리스트로 전달합니다.
# 'reviewText', 'overall', 'vote' 열 선택
df[['reviewText', 'overall', 'vote']]
5.3 filter() 함수와 정규 표현식
filter() 함수를 사용하여 특정 패턴과 일치하는 열을 선택할 수 있습니다.
# 'Time'가 포함된 열을 선택
df.filter(like='Time')
# 'review'가 포함된 모든 열을 선택
df.filter(regex='review', axis=1)
# 'r'로 시작하는 열 선택
df.filter(regex='^r')
# 'e'로 끝나는 열 선택
df.filter(regex='e$')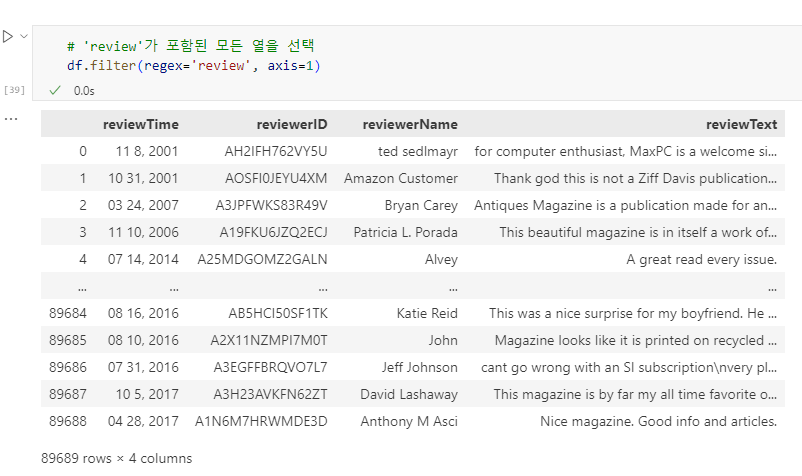

6. 데이터 변형 (Reshaping)
6.1 데이터프레임 병합: concat()
concat() 함수는 데이터프레임을 병합할 때 사용합니다.
# 기존 데이터프레임 생성
data1 = {'Name': ['Chulsoo', 'Younghee', 'Minsu', 'Jiyoung'], 'Age': [25, 30, 22, 28]}
df1 = pd.DataFrame(data1)
# 추가할 데이터프레임 생성
data2 = {'Name': ['Hyunwoo', 'Suji', 'Donghyun', 'Jisoo'], 'Age': [24, 27, 26, 29]}
df2 = pd.DataFrame(data2)
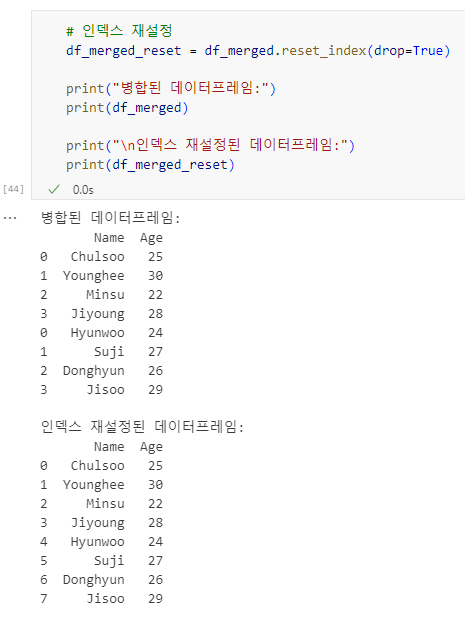
# 데이터프레임 병합 (row-wise 결합)
df_merged = pd.concat([df1, df2])
# 인덱스 재설정
df_merged_reset = df_merged.reset_index(drop=True)
print(df_merged)
print(df_merged_reset)
# df1 데이터프레임 생성
data1 = {
'Name': ['Chulsoo', 'Younghee', 'Minsu', 'Jiyoung'],
'Age': [25, 30, 22, 28]
}
df1 = pd.DataFrame(data1)
# df2 데이터프레임 생성
data2 = {
'City': ['Seoul', 'Busan', 'Incheon', 'Daegu'],
'Country': ['Korea', 'Korea', 'Korea', 'Korea']
}
df2 = pd.DataFrame(data2)
# 데이터프레임 병합 (column-wise 결합)
df_merged_columns = pd.concat([df1, df2], axis=1) # df1과 df2를 컬럼 기준으로 병합 가능
print("병합된 데이터프레임:")
print(df_merged_columns)
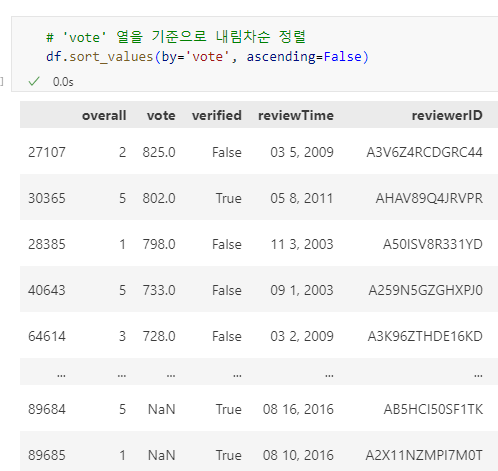
6.2 특정 열 기준 행 정렬: sort_values()
sort_values()는 특정 열을 기준으로 데이터프레임의 행을 정렬합니다.
6.3 열 이름 수정: rename()
열 이름을 변경할 때 rename()을 사용합니다.
# 'reviewText' 열을 'review'로, 'reviewerName' 열을 'name'으로 변경
df.rename(columns={'reviewText': 'review', 'reviewerName': 'name'})
6.4 인덱스 정렬: sort_index()
sort_index()는 데이터프레임의 인덱스를 기준으로 정렬합니다.
# 인덱스를 기준으로 오름차순 정렬
df.sort_index()
# 인덱스를 기준으로 내림차순 정렬
df.sort_index(ascending=False)
6.5 열 삭제: drop()
특정 열을 삭제할 때 drop()을 사용합니다.
# 'reviewText'와 'summary' 열을 삭제
df.drop(columns=['reviewText', 'summary'])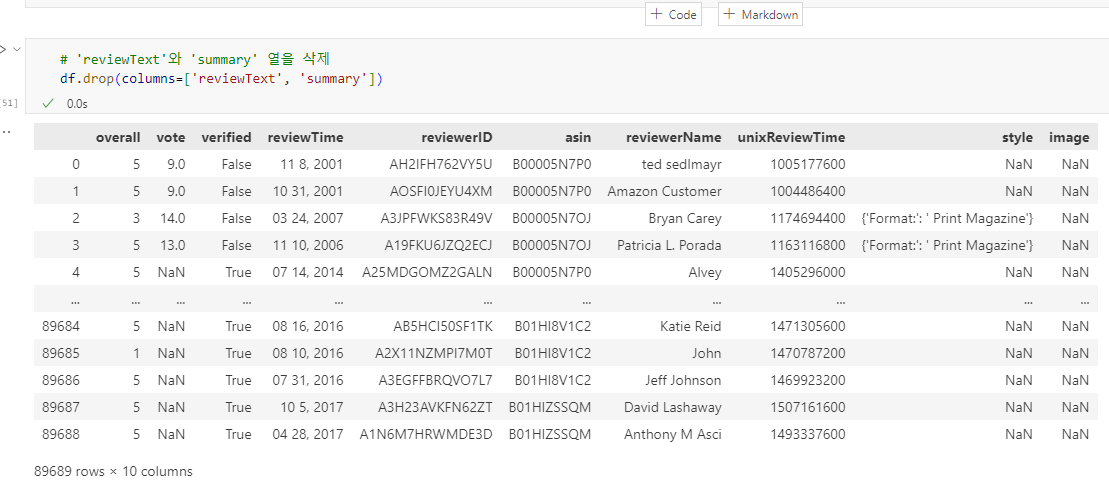
7. 파생변수
apply()와 lambda를 사용하여 각 값에 조건에 따라 다른 값을 부여하는 파생변수를 생성할 수 있습니다.
# 'overall' 열의 각 값에 대해 3 이상이면 'Pos' 아니면 'Neg'를 저장
df['overall'].apply(lambda x: 'Pos' if x >= 3 else 'Neg')

8. 누락 데이터 처리
8.1 누락 데이터 확인
# 데이터프레임 요약 정보 출력
df.info()
# 특정 열의 데이터 개수 확인 (누락 데이터 포함)
print(df['vote'].value_counts(dropna=False))
# 열별 누락 데이터 개수 확인
print(df.isnull().sum())


8.2 누락 데이터 제거
누락 데이터를 제거하는 방법입니다.
# NaN이 포함된 행 삭제
df.dropna()
# NaN이 포함된 열 삭제
df.dropna(axis=1)
# 'image' 열에서 NaN이 포함된 행 제거
df.dropna(subset=['image'])
8.3 누락 데이터 대체법(imputation)
# 'vote' 열의 평균으로 결측값 대체
df['vote'].fillna(df['vote'].mean().round(0))
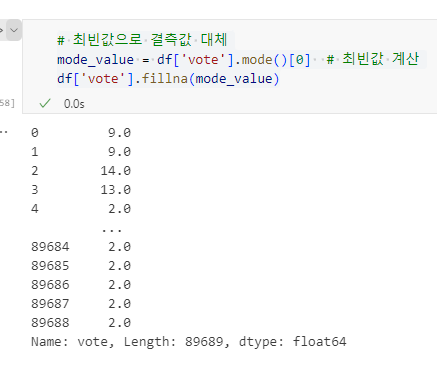
# 최빈값으로 결측값 대체
mode_value = df['vote'].mode()[0] # 최빈값 계산
df['vote'].fillna(mode_value)
9. merge() 함수
merge()는 데이터프레임을 기준 열을 기준으로 병합할 때 사용됩니다.

9.1 Inner Join

기준 열의 교집합에 해당하는 행만을 병합합니다.
# 데이터프레임 병합: on=None, how='inner'
pd.merge(df1, df2, on='id', how='inner')
9.2 Outer Join

기준 열을 기준으로 두 데이터프레임의 합집합을 생성합니다.
# 데이터프레임 병합: on='key', how='outer'
pd.merge(df1, df2, on='id', how='outer')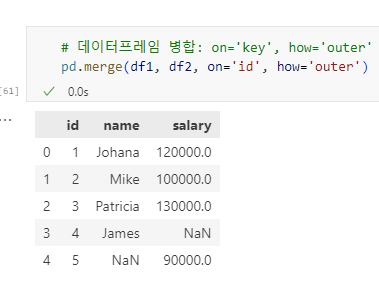
9.4 Left Join / Right Join
왼쪽 또는 오른쪽 데이터프레임을 기준으로 병합할 때 사용합니다.
# how='right' 옵션을 사용하여 오른쪽 데이터프레임을 기준으로 병합
pd.merge(df1, df2, left_on='id1', right_on='id2', how='right')
# how='left'을 사용하여 왼쪽 데이터프레임을 기준으로 병합
pd.merge(df1, df2, left_on='id1', right_on='id2', how='left')
10. 그룹 연산
# 예제 데이터프레임 생성
data = {
'State': ['CA', 'CA', 'TX', 'TX', 'NY', 'NY', 'CA', 'TX', 'NY'],
'Gender': ['F', 'M', 'F', 'M', 'F', 'M', 'F', 'M', 'F'],
'Year': [2020, 2020, 2020, 2020, 2021, 2021, 2019, 2021, 2019],
'Name': ['Emma', 'Liam', 'Olivia', 'Noah', 'Ava', 'Ethan', 'Sophia', 'Mason', 'Isabella'],
'Count': [300, 250, 400, 350, 200, 150, 320, 340, 230]
}
df = pd.DataFrame(data)
10.1 Split (분할)
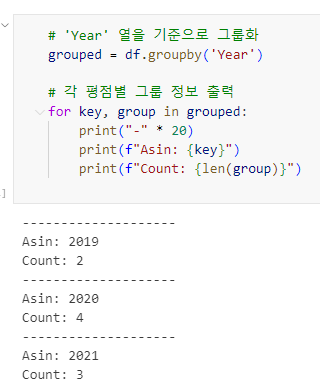
groupby()를 사용하여 데이터를 특정 열을 기준으로 그룹화

# 'Year' 열을 기준으로 그룹화
grouped = df.groupby('Year')
# 각 평점별 그룹 정보 출력
for key, group in grouped:
print("-" * 20)
print(f"Asin: {key}")
print(f"Count: {len(group)}")
# 'Year' 열을 기준으로 그룹화
grouped = df.groupby('Year')
# 'Year' 값이 2020인 데이터 그룹 선택
group_a1 = grouped.get_group(2020)
print(group_a1)

10.2 Apply (적용) / Combine (결합)
그룹별로 연산을 적용하고 결과를 결합합니다.
# 각 그룹별 표준편차 계산
std_dev = grouped['Count'].std()
print(std_dev)
# 각 그룹별 요약 통계량 출력
desc = grouped['Count'].describe()
print(desc)
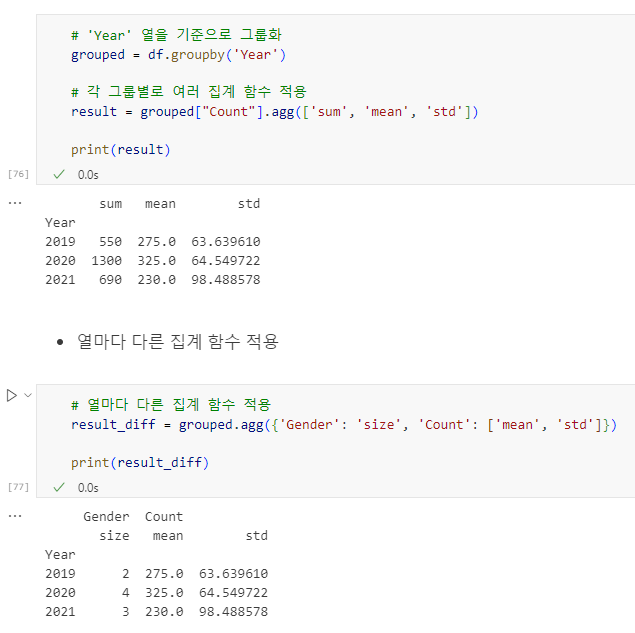
10.3 agg() 함수
agg()는 여러 개의 집계 함수 한 번에 적용할 때 유용합니다.

# 'Year' 열을 기준으로 그룹화
grouped = df.groupby('Year')
# 각 그룹별로 여러 집계 함수 적용
result = grouped["Count"].agg(['sum', 'mean', 'std'])
print(result)
# 열마다 다른 집계 함수 적용
result_diff = grouped.agg({'Gender': 'size', 'Count': ['mean', 'std']})
print(result_diff)
10.4 transform() 함수
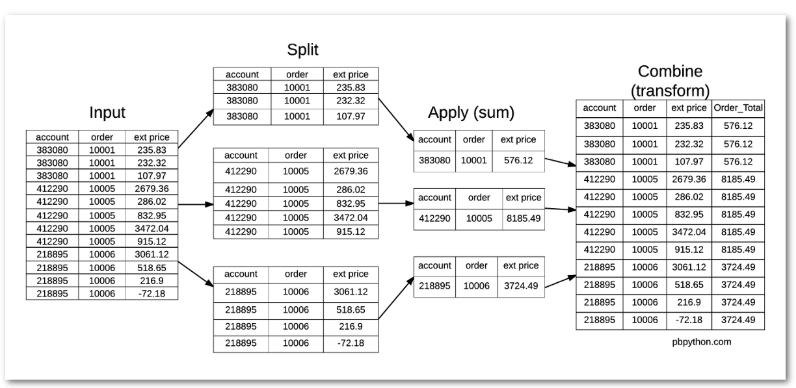
transform()은 각 원소에 대해 연산을 수행한 후 그 결과를 원래 데이터프레임의 구조에 맞추어 반환
transform() 함수의 주요 특징
- 그룹별로 함수를 적용: transform()은 데이터를 그룹화한 후, 각 그룹에 대해 주어진 함수를 적용합니다.
- 원본 데이터프레임과 동일한 형태 반환: 그룹별로 함수가 적용된 결과는 원본 데이터프레임과 동일한 길이와 형태를 유지하며 반환됩니다. 즉, 그룹별 결과를 원본 데이터에 맞게 확장하여 반환합니다.
- 각 행에 계산된 결과 반영: 반환된 결과는 각 행에 대한 계산된 값이 그대로 반영됩니다. 예를 들어, 그룹별 평균값을 계산한 후 이를 각 행에 적용할 수 있습니다.
- 주로 그룹별 계산값을 원본 데이터에 적용: 주로 그룹별로 계산된 값(예: 평균, 최대값)을 원본 데이터의 각 행에 적용해야 할 때 사용됩니다.
# 'Year' 열을 기준으로 평균 계산
df.groupby('Year')["Count"].transform('mean')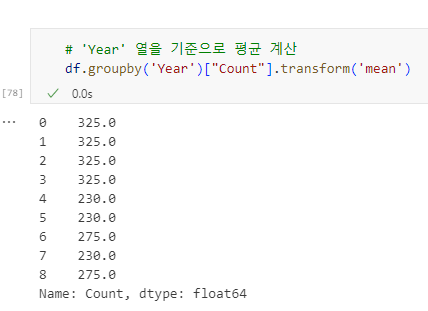
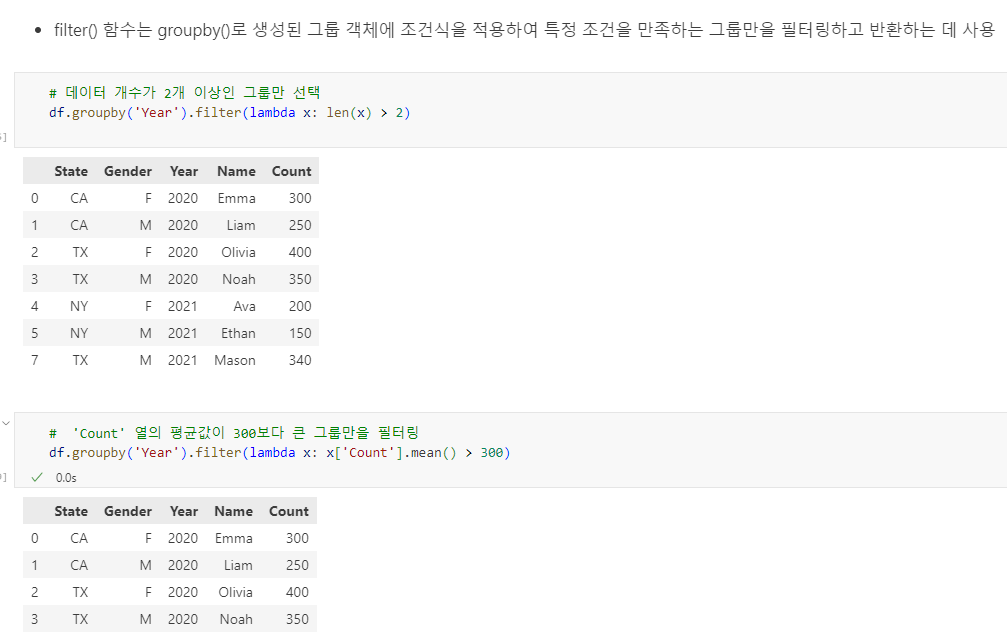
10.5 filter() 함수
filter() 함수는 특정 조건을 만족하는 그룹을 필터링합니다.
2025.03.20 - [Data Analysis/Basic] - [Data Analysis] Pandas 라이브러리 연습 2
[Data Analysis] Pandas 라이브러리 연습 2
pd.to_numeric(arg, errors='raise') Pandas에서 문자열이나 기타 형식의 데이터를 숫자로 변환할 때 사용하는 함수 * `arg`: 숫자로 변환할 대상 (Series, list-like 등)* `errors`: 변환 중 오류 발생 시 처리 방법
c0mputermaster.tistory.com
'Data Analysis > Basic' 카테고리의 다른 글
| [Data Analysis] 데이터 전처리 해보기 (0) | 2025.03.29 |
|---|---|
| [Data Analysis] 데이터 시각화 해보기 (0) | 2025.03.23 |
| [Data Analysis] 데이터 정제 및 분석 해보기 (0) | 2025.03.23 |
| [Data Analysis] Pandas 라이브러리 연습 2 (0) | 2025.03.20 |
| [Data Analysis] 데이터 분석 프로세스 알아보기 (0) | 2025.02.19 |