
pandas 데이터 프레임 길이 제한
pd.set_option('display.max_rows', 10)
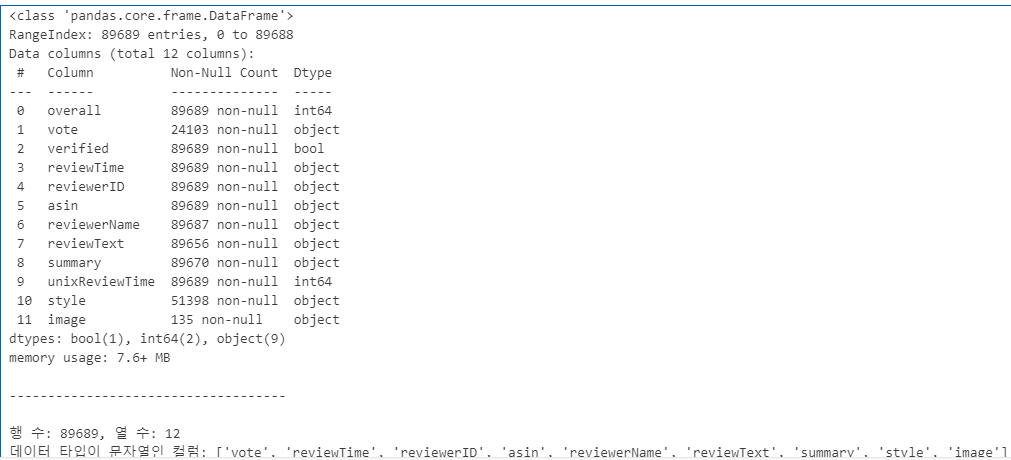
1. 데이터 세트에 저장된 인덱스와 컬럼의 총 개수를 확인하고 데이터 타입이 문자열인 컬럼 조회하기
import pandas as pd
df_json = pd.read_json('Magazine_Subscriptions.json', lines=True)
info = df_json.info()
print("\n------------------------------------\n")
shape = df_json.shape
print(f"행 수: {shape[0]}, 열 수: {shape[1]}")
string_columns = df_json.select_dtypes(include=['object']).columns
print(f"데이터 타입이 문자열인 컬럼: {list(string_columns)}")
df = df_json.copy()
2. 데이터 세트에서 열 이름 변경하기
df = df.rename(columns={'asin': 'item_id', 'reviewerName': 'user_id'})
print(list(df.columns))df_filtered = df.groupby('user_id').filter(lambda x: len(x) >= 5)
print(df_filtered)
4. ('verified'가 True인 경우)된 경우만을 필터링하고 인덱스를 초기화\
df_verified = df[df['verified'] == True]
df_verified_reset = df_verified.reset_index(drop=True)
print(df_verified_reset)
df_verified.reset_index(drop=True):
- reset_index()는 데이터프레임의 인덱스를 초기화하는 역할을 합니다. 기본적으로, reset_index()는 새로운 인덱스를 생성하고 기존의 인덱스를 index라는 이름의 새로운 컬럼으로 추가
- drop=True를 지정하면 기존 인덱스를 새로운 컬럼으로 추가하지 않고 그냥 버림. 즉, 기존 인덱스는 삭제되고 새롭게 0부터 시작하는 기본 정수 인덱스가 할당됨
5. (item_id) 칼럼에 대한 평균 평점(‘overall’)을 계산하여 새로운 열을 생성하고 개별 평점과 평균 평점 간의 차이의 절댓값을 계산하여 새로운 열에 저장하시오.
df['overall_mean'] = df.groupby('item_id')['overall'].transform('mean')
df['overall_deviation_abs'] = abs(df['overall'] - df['overall_mean'])
print(df[['item_id', 'overall', 'overall_mean', 'overall_deviation_abs']])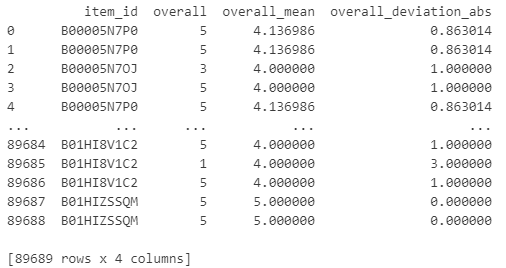
6. 'vote' 컬럼에서 누락된 데이터(Null 값)를 평균값으로 대체하시오. 데이터를 4개 구간으로 나누고 각 구간에 'Low', 'Medium', 'High', 'Very High'의 라벨을 적용하여 저장하시오.
df['vote'] = pd.to_numeric(df['vote'], errors='coerce')
df['vote'] = df['vote'].fillna(df['vote'].mean())
labels = ['Low', 'Medium', 'High', 'Very High']
df['label'] = pd.cut(df['vote'], bins=[0, 5, 10, 12, vote_max], labels=labels)
- df['vote'] = pd.to_numeric(df['vote'], errors='coerce'):
- pd.to_numeric()는 Pandas에서 데이터를 숫자형으로 변환하는 함수
- df['vote']는 vote라는 컬럼을 의미. 이 컬럼의 데이터가 숫자형이 아닐 수 있기 때문에, 이를 숫자형으로 변환
- errors='coerce'는 변환할 수 없는 값을 NaN (결측값)으로 처리하도록 지시. 예를 들어, vote 컬럼에 숫자가 아닌 값(문자열 등)이 있다면 그 값을 NaN으로

- df['vote'] = df['vote'].fillna(df['vote'].mean()):
- df['vote'].fillna(df['vote'].mean())는 vote 컬럼의 결측값(NaN)을 해당 컬럼의 평균값으로
- df['vote'].mean()는 vote 컬럼의 평균값을 계산합니다. 예를 들어, df['vote']가 [1, 2, NaN, 4, 5]일 경우, 평균값은 (1 + 2 + 4 + 5) / 4 = 3.0
- fillna()는 NaN 값을 특정 값으로 채우는 함수입니다. 여기서는 df['vote'].mean() 값(3.0)을 NaN 대신 넣음
7. (‘reviewTime’)가 2015년 이전인 경우 '0', 이후인 경우 '1'로 표시하는 새로운 파생변수를 만드시오.
df['reviewTime'] = pd.to_datetime(df['reviewTime'], errors='coerce')
df['reviewTime_label'] = df['reviewTime'].apply(lambda x: 0 if x.year < 2015 else 1)
count_zeros = (df['reviewTime_label'] == 0).sum()
count_ones = (df['reviewTime_label'] == 1).sum()
=> 47842 41847
지금부터 각 질문에 대한 답변은 이전 질문에서 저장한 데이터를 계속해서 사용
df_json = pd.read_json('Magazine_Subscriptions.json', lines=True)
df_json_meta = pd.read_json('meta_Magazine_Subscriptions.json', lines=True)
df = df_json.copy()
df_meta = df_json_meta.copy()
8. 메타데이터 세트에서 'asin' 열에 포함된 중복 값을 제거한 후, 새로운 데이터프레임을 생성
df_meta.drop_duplicates(subset='asin', inplace=True)
9. 메타데이터 세트에서 'brand' 열에 포함된 공백 값을 제거하고 데이터프레임을 새롭게 생성한 뒤 인덱스를 초기화
df_meta = df_meta[df_meta['brand'].apply(lambda x: len(x) > 0)]
df_meta_cleaned = df_meta.reset_index(drop=True)
10. 데이터 세트를 'asin' 열을 기준으로 결합하고, 다음 열을 포함하는 새로운 데이터프레임을 저장하시오. ['reviewerID', 'asin', 'overall', 'reviewText', 'brand', 'vote']
df_merged = pd.merge(df, df_meta_cleaned, on='asin', how='inner')
df_merged = df_merged[['reviewerID', 'asin', 'overall', 'reviewText', 'brand', 'vote']]
print(df_merged)
11. 'brand' 열에서 빈도가 가장 높은 상위 2개 브랜드를 찾고, 이 중 어떤 브랜드의 평균 평점이 더 높은지 확인하시오.
top_brands = df_merged['brand'].value_counts().head(2).index
print(top_brands)
brand_avg_ratings = df_merged.groupby('brand')['overall'].mean()
print(brand_avg_ratings)
top_brands_avg_ratings = brand_avg_ratings[top_brands]
print(top_brands_avg_ratings)
12. 'brand' 열에서 빈도가 가장 높은 브랜드 중에서 최소 5개 이상의 리뷰를 가진 아이템을 선택하시오. 이 중에서 평균 평점(소수점 둘째 자리까지)이 가장 높은 상위 5개 아이템(asin)을 출력
top_brand = df_merged['brand'].value_counts().idxmax()
print(top_brand)
df_brand_filtered = df_merged[df_merged['brand'] == top_brand]
item_review_counts = df_brand_filtered['asin'].value_counts()
df_filtered_items = df_brand_filtered[df_brand_filtered['asin'].isin(item_review_counts[item_review_counts >= 5].index)]
# 아이템의 평균 평점 계산
item_avg_ratings = df_filtered_items.groupby('asin')['overall'].mean()
top_5_items = item_avg_ratings.sort_values(ascending=False).head(5)
print("평균 평점이 가장 높은 상위 5개 아이템(asin):")
print(top_5_items)
12. 각 아이템(asin)에 대한 리뷰 투표수(vote)의 총합을 계산(누락 데이터 제외)하고, 해당 결과를 내림차순으로 정렬하시오.
df_filtered_items['vote'] = pd.to_numeric(df_filtered_items['vote'], errors='coerce')
item_vote_sum = df_filtered_items.groupby('asin')['vote'].sum()
item_vote_sum_sorted = item_vote_sum.sort_values(ascending=False)
- ascending=True (기본값): 오름차순 정렬. 작은 값에서 큰 값으로 정렬
- ascending=False: 내림차순 정렬. 큰 값에서 작은 값으로 정렬
'Data Analysis > Basic' 카테고리의 다른 글
| [Data Analysis] 데이터 전처리 해보기 (0) | 2025.03.29 |
|---|---|
| [Data Analysis] 데이터 시각화 해보기 (0) | 2025.03.23 |
| [Data Analysis] Pandas 라이브러리 연습 2 (0) | 2025.03.20 |
| [Data Analysis] Pandas 라이브러리 연습 (0) | 2025.02.25 |
| [Data Analysis] 데이터 분석 프로세스 알아보기 (0) | 2025.02.19 |