이 글은 cnn(합성곱 신경망)의 기본 원리와 핵심 구성 요소를 정리하여 보기 위해 쓴 포스팅이다..
CNN(합성곱 신경망) 아키텍처 개요
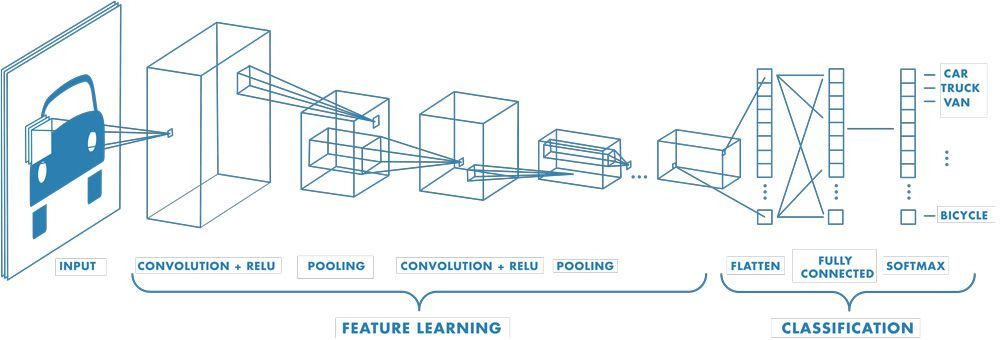
- CNN의 정의: 컨볼루션( Convolution) 연산을 활용하여 뉴럴 네트워크를 효율적으로 만든 모델 구조이다.
- 컴퓨터 비전에서의 역할: 이미지에서 특징을 추출하는 Feature Extractor로 주로 이용된다.
Feature Extractor 예시

- 입력 영상 (INPUT)
- 일반적인 영상은 RGB 3 채널로 구성된 텐서형태이다.
- 예시: 3 ( 채널) x 256 (세로) x 256 (가로) 크기의 텐서이다.
- 의료 영상처럼 그레이 스케일은 1 채널, 볼륨 매트릭 영상은 더 많은 채널을 가질 수 있다.
- CNN의 처리 과정 (Feature Derection):
- 컨볼루션 연산: 입력 영상에 컨볼루션 필터(예: 16개)를 적용하여 채널수를 늘린다.
- 예시: 3x256x256 텐서가 16x128x128 텐서로 변환된다.
- 이때 세로/가로 길이가 절반으로 줄어드는 것은 풀링(Pooling) 또는 컨볼루션 필터의 스트라이드(Stride) 적용 때문이다.
- 활성화 함수 (Activation Function): 비선형성(Non-linearity)을 부여하기 위해 렐루(ReLU)와 같은 활성화 함수를 사용한다.
- 반복 처리: 컨볼루션, 풀링, 활성화 함수 과정을 반복하여 채널수를 늘리고 크기를 줄인다.
- 예시: 16x128x128 텐서가 64x64x64 텐서로 변환된다.
- 컨볼루션 연산: 입력 영상에 컨볼루션 필터(예: 16개)를 적용하여 채널수를 늘린다.
3. 특징 맵의 벡터화 및 분류 (Classifier):
- 플래튼(Flatten) 과정:
- 어느 정도 특징이 가공되면, 3개의 축을 가진 텐서(예: 64x64x64)를 하나의 1열 벡터로 펼친다.
- 이 과정은 영상의 지역적 특성 추출이 아닌 전반적인 특성을 살피기 위함이다.
- 예시: 64x64x64 텐서는 262,144개의 값을 가진 벡터로 변환된다.
- 완전 연결 계층 (Fully Connected Layer):
- 플래튼된 벡터는 일반적인 뉴럴 네트워크(Linear Layer, Fully Connected Layer, Dense Layer)에 연결된다.
- 이 계층은 입력 노드 수(예: 262,144개)와 분류하려는 클래스 수(예: 3개)에 따라 가중치(weight)를 가진다.
- 예시: 262,144 x 3개의 가중치가 존재하여 행렬 연산을 통해 각 클래스에 대한 값을 도출한다.
- 소프트맥스(Softmax) 함수:
- 로짓값을 확률 값으로 변환하기 위해 소프트맥스 함수를 사용한다.
- 가장 높은 확률을 가진 클래스로 최종 분류를 결정한다.
- 예시: 클래스 0번(앨런 머스크) 97%, 클래스 1번(제프 베조스) 2%, 클래스 2번(존 스노우) 1%의 확률이 나왔을 때, 클래스 0번으로 분류한다.
Feature Extractor로서 컨볼루셔널 뉴럴 네트워크가 동작하는 일반적인 과정이였다.
CNN의 핵심 구성 요소 및 작동 원리

CNN의 일반적인 구조로는 하나의 컨볼루셔널 레이어 블록이 여러 번 반복되는 형태이다.
컨볼루셔널 레이어 블록의 단계로는 보통
1) 컨볼루션 연산: 필터 응답(filter response)을 계산하여 특징을 추출한다.
2) 비선형성 (Non-linearity): 활성화 함수( Activation)를 통해 비선형성을 부여한다.
3) 서브 샘플링 (Sub-sampling): 풀링( Pooling) 또는 스트라이디드 컨볼루션(Strided Convolution)을 통해 특징 맵의 크기를 줄인다.
4) 정규화 (Normalization): 정규성을 부여하여 모델의 안정성을 높인다.
이 4단계 모듈이 N번 반복되면서 최종 특징이 추출된다, 컨볼루셔널 뉴럴 네트워크에서 학습되는 것은 결국 이 필터(커널)의 값이다. 참고하자면 컨볼루셔널 레이어는 입력에 지역적인 의존성(local dependency)이 있다는 가정을 기반으로 한다. 없다면 의미가 없는 연산
활성화 함수 (Non-linearity)

컨볼루션 연산 후 비선형성(Non-linearity)을 부여하기 위해 활성화 함수( ActivationFunction)를 통과시킨다.
함수 종류: 시그모이드(Sigmoid), 하이퍼볼릭 탄젠트(TanH), 렐루(ReLU), 스위시(Swish) 등이 있다.
작동 방식: 활성화 함수는 특정 성분을 활성화시키고 불필요한 성분을 억제함으로써 비선형성을 부여한다.
예시: ReLu 활성화 함수를 적용하면 필요한 성분만 살리고 불필요한 성분은 죽여서 비선형성을 부여하고 필요한 정보를 추출한다
서브 샘플링 (Sub-sampling)
- 목적: 특징 맵의 크기를 줄이는 과정이다.
- 주요 방법:
- 풀링 (Pooling):
- 특정 윈도우 영역(예: 2x2) 내에서 최대값(Max Pooling), 평균값(Average Pooling), 최소값(Min Pooling) 등을 취하여 크기를 줄인다.
- 스트라이드(Stride)를 설정하여 윈도우 이동 간격을 조절한다 (예: 스트라이드2는 두 칸 이동).
- 필터 스트라이드 (Filter Stride):
- 컨볼루션 연산 시 필터의 이동 간격( 스트라이드)을 1보다 크게 설정하여 특징 맵의 크기를 줄인다.
- 예시: 스트라이드를 2로 설정하면 필터가 두 칸씩 이동하며 연산하여 크기가 절반으로 줄어든다.
- 풀링 (Pooling):
- 공간 크기(Spatial Size)의 의미: 특징 맵의 세로 길이(h)와 가로 길이(w)를 고려하는 영역이다.

- 서브 샘플링의 중요성 ( Receptive Field ):
- 리셉티브 필드(Receptive Field) 확장: 서브 샘플링을 통해 리셉티브 필드를 키우는 것이 주된 목적이다.
- 리셉티브 필드의 의미: 하나의 정보로부터 다음 정보를 뽑아내기 위해 살펴봐야 하는 영역이다.
- 저수준에서 고수준 특징 추출:
- CNN의 앞단에서는 엣지, 그래디언트와 같은 저수준(Low Level) 특징이 추출된다.
- 뒷단으로 갈수록 사람의 생각과 유사한 의미론적인 고수준(Higher Level) 특징(Semantic Feature)이 추출된다.
- 이는 서브 샘플링을 통해 공간 크기를 줄여가면서 필터가 더 넓은 영역을 보게 되기 때문이다.
- CNN이 고수준 특징을 잘 뽑을 수 있도록 의도적으로 서브 샘플링을 설계하는 것이다.
- 다음 레이어의 넓은 공간 영역 탐색 허용: 서브 샘플링은 다음 레이어에서 더 넓은 공간 영역을 살펴볼 수 있도록 허용하는 개념이다.
- CNN에서 한 뉴런의 Receptive field는 커널(필터)의 크기와 stride에 의해서 결정이 된다. 커널의 크기가 크거나 또는 Stride가 크게 되면 해당 커널이 처리할 수 있는 이미지의 부분이 커지므로, 이는 곧 Receptive field가 커지는 것이다.
- Receptive field를 키우면 CNN은 더 큰 영역의 이미지를 본다는 것이고, 더 복잡한 특징을 추출할 수 있게 되는 것이다.
[개념 정리] CNN에서 수용영역이란? Receptive field란?
이번에 알아볼 내용은 Receptive field입니다. 우리 말로는 수용영역이라고 하는데요 1. Receptive Field란?(수용영역이란) - Receptive field, 수용 영역은컨볼루션 신경망(CNN)에서 출력 레이어의 뉴런 하나에
jaylala.tistory.com
- 기타 방법: 픽셀 셔플(Pixel Shuffle)과 같은 다양한 테크닉도 존재하지만, 풀링과 필터 스트라이드가 가장 기본적인 방법이다
정규화 (Normalization)

- 목적: 컨볼루션, 활성화 함수, 서브 샘플링 과정을 거친 후 특징 맵의 값을 정규화하는 작업이다.
- 필요성:
- 값 분포 변화: 각 계층을 지날수록 값의 분포가 변화한다.
- 최적화 가속: 정규화는 최적화 과정에서 목적 함수에 더 빠르게 도달하도록 돕는다.
- 학습 안정성: 정규화를 하지 않으면 학습 시 불안정한(Unstable) 특성을 띠게 된다.
- 오버피팅 방지: 모델의 일반화(Generalization) 능력을 높이고 오버피팅(Overfitting)을 방지하는 역할도 한다.
- 작동 방식: 특징 맵의 분포를 노말 분포(Normal Distribution) 또는 가우시안 분포(Gaussian Distribution)처럼 예쁘게 만들어준다.
- 주요 정규화 기법: 배치 노멀라이제이션(Batch Normalization), 레이어 노멀라이제이션(Layer Normalization), 인스턴스 노멀라이제이션(Instance Normalization), 그룹 노멀라이제이션(Group Normalization) 등이 있다.
- CNN의 계층적 특징 추출: 이러한 과정을 통해 CNN은 저수준 특징에서 고수준 특징으로 나아가는 계층적인 구조를 가지고 영상을 이해한다.
CNN 모듈 반복 => 특징 맵 벡터화 => FC => SoftMax
LeNet-5

- 개발: 1998년 야누크훈 교수가 개발한 최초의 CNN모델이다.
- 목적: 손글씨 숫자 분류( MNIST데이터셋)를 위해 CNN을 처음 도입한 모델이다.
- 기본 구조: 컨볼루션 레이어, 서브 샘플링, 활성화 함수(비선형성)를 통과시켜 특징 맵을 가공한 후, 벡터로 플래튼하여 최종적으로 10개의 클래스(숫자 0-9)로 분류한다.
- LeNet-5 아키텍처 상세:
- 입력: 32x32 크기의 1 채널 MNIST이미지이다.
- 첫 번째 컨볼루션: 6개의 필터를 사용하여 28x28 크기의 특징 맵 6개를 생성한다.
- 첫 번째 풀링: 풀링을 통해 크기를 절반으로 줄여 14x14 크기의 특징 맵 6개를 유지한다.
- 두 번째 컨볼루션: 16개의 필터를 사용하여 채널수를 16으로 늘리고, 크기는 10x10으로 줄어든다 (패딩 없음).
- 두 번째 서브 샘플링: 크기를 5x5로 줄인다.
- 벡터화: 5x5x16 특징 맵을 120차원의 벡터로 펼친다.
- 완전 연결 계층:
- 120차원 벡터를 84개의 뉴런으로 변환한다 (120x84개의 가중치).
- 84개의 뉴런을 최종 10개의 클래스(0-9)로 분류한다 (84x10개의 가중치).
- 소프트맥스: 10개의 클래스에 대한 확률을 예측하여 분류한다.
- LeNet-5의 특징 (Characteristics):
- 반복 구조: 컨볼루션, 비선형성(활성화), 풀링이 반복되는 구조이다.
- 풀링 방법: 2x2 크기의 Average Pooling을 사용했다.
- 활성화 함수: Sigmoid Function (하이퍼볼릭 탄젠트)을 사용했다.
- 컨볼루션 필터: 5x5 크기의 필터를 사용했다.
- 레이어 수: 총 7개의 레이어로 구성된다.
- 모델 크기: 전체 파라미터(미지수) 개수는 약 100만 개로, 현재 모델에 비해 크지 않다.
- LeNet-5의 주요 공헌:
- CNN 최초 도입: 뉴럴 네트워크에 컨볼루션 연산을 사용한 최초의 CNN모델이다.
- 서브 샘플링 기법: 리셉티브 필드를 키우기 위해 Average Pooling을 통한 서브 샘플링 기법을 사용했다.
- 스파스 연결 (Sparse Connection): 컨볼루션 연산 자체가 특징 맵 사이를 드문드문 연결하는 스파스 커넥션을 의미한다 (Fully Connected와 대비).
- 당시의 문제점:
- 느린 학습 속도: 1998년 당시 GPU가 없어 학습에 매우 오랜 시간이 걸렸다.
- 어려운 학습: 학습시키기 어려웠다.
- 데이터 부족: 충분한 데이터가 없었다.
- 뉴런 사망 문제 (Vanishing Gradient): 시그모이드 계열 활성화 함수(하이퍼볼릭 탄젠트, 로지스틱 함수) 사용으로 미분값이 계속 줄어들어 그래디언트가 소멸하는 현상(Vanishing Gradient)이 발생하여 뉴런이 쉽게 죽었다.
- 이 문제는 렐루( ReLU)와 같은 새로운 활성화 함수 개발로 해결되었다.
- GPU 활용의 한계: LeNet-5는 컨볼루션 레이어가 적어(2개) GPU를 사용해도 속도 이득이 크지 않았다.
CNN 모델의 Pros & Cons
모델을 깊게 만들어보자
- 깊은 신경망 (Deeper Network): 레이어를 더 많이 사용하는 것을 의미한다.
- 넓은 신경망 (Wider Network): 필터를 더 많이 사용하여 채널수를 늘리는 것을 의미한다.
모델이 깊어질수록?
- 높은 표현력: 더 많은 정보를 학습하고, 보다 높은 표현력을 가진 특징을 추출할 수 있다.
- 리셉티브 필드 확장: 모델이 깊어질수록 리셉티브 필드가 더 넓어진다.
- 모델 용량 증가: 모델의 용량 자체가 커진다.
- 비선형성 추가: 레이어가 많아질수록 비선형성(Non-linearity)이 많이 추가된다.
- 공간 왜곡을 통한 분류: 비선형성은 데이터를 잘 분류할 수 있는 형태로 공간을 왜곡(휘게)하여 분류 성능을 높인다.
- NN의 핵심: 뉴럴 네트워크는 레이어가 진행되면서 데이터가 잘 분류될 수 있는 공간을 구성하고, 이를 통해 특징을 추출한다.
- 모델이 깊고 넓어질수록 비선형성이 많아져 성능이 좋아질 수 있다.
모델을 깊고 넓게 만들 때의 단점
- 최적화의 어려움: 모델을 최적화(Optimize)하고 수렴시키기 어렵다.
- 그래디언트 문제:
- Vanishing Gradient: 역전파(Backpropagation) 시 미분값(Gradient)이 소멸되어 앞쪽 레이어가 업데이트되지 않아 성능 저하를 초래한다.
- Exploding Gradient: 그래디언트가 갑자기 폭발적으로 커지는 경우도 있다.
- 오버피팅 및 성능 저하:
- 모델의 가중치(미지수) 수가 증가할수록 오버피팅(Overfitting) 문제가 발생할 가능성이 높아진다.
- Degradation: 모델이 훈련 데이터에 너무 의존적이 되어 오히려 성능이 저하되는 현상(최적화가 제대로 안 됨)이 발생할 수 있다.
- 계산 복잡성 증가: 모델이 커질수록 하드웨어적인 계산 복잡성(Computational Complexity)이 증가하여 학습시키기 어려워진다.
이러한 장단점 때문에 무조건 깊고 넓게 모델을 만들 수는 없으며, 이를 극복하기 위한 다양한 테크닉들이 지속적으로 연구되고 있다. CNN의 구조 자체는 현재 인공지능 분야에서 그렇게 크게 중요하지 않다! Sort 알고리즘을 많이 알고 있다고 알고리즘을 잘 한다고 할 수 없는것 처럼, 어떤 목적에 적절하게 사용할 수 있는것이 더 중요.
CNN은 Convolution과 Pooling을 반복적으로 사용하면서 불변하는 특징을 찾고, 그 특징을 입력데이터로 Fully-connected 신경망에 보내 Classification을 수행하는 것이다.
https://rubber-tree.tistory.com/116
[딥러닝 모델] CNN (Convolutional Neural Network) 설명
저번 포스팅에서는 딥러닝의 모델별 특징에 대해 알아보았습니다. 2021.07.10 - [SW programming/Computer Vision] - AI, 머신러닝, 딥러닝 이란? 그리고 딥러닝 모델 종류 그리고 이번 포스팅에서는 그 중 Compu
rubber-tree.tistory.com
'Technology Notes' 카테고리의 다른 글
| [Deep Learning] Anomaly Detection(이상치 탐지)를 알아보자 (0) | 2025.04.09 |
|---|---|
| [Android] Android Emulator ControlService 오류 1062 (0) | 2025.04.08 |
| [Project] Qualcomm Ai Hub에서 YOLOv11-Detection-Quantized 모델 컴파일 해보기 (0) | 2025.03.23 |
| [Project] Qualcomm 루빅 파이(RUBIK Pi) 사용해보기 (3) | 2025.03.05 |
| [Project] Qualcomm Ai Hub 사용해보기 (3) | 2025.03.03 |