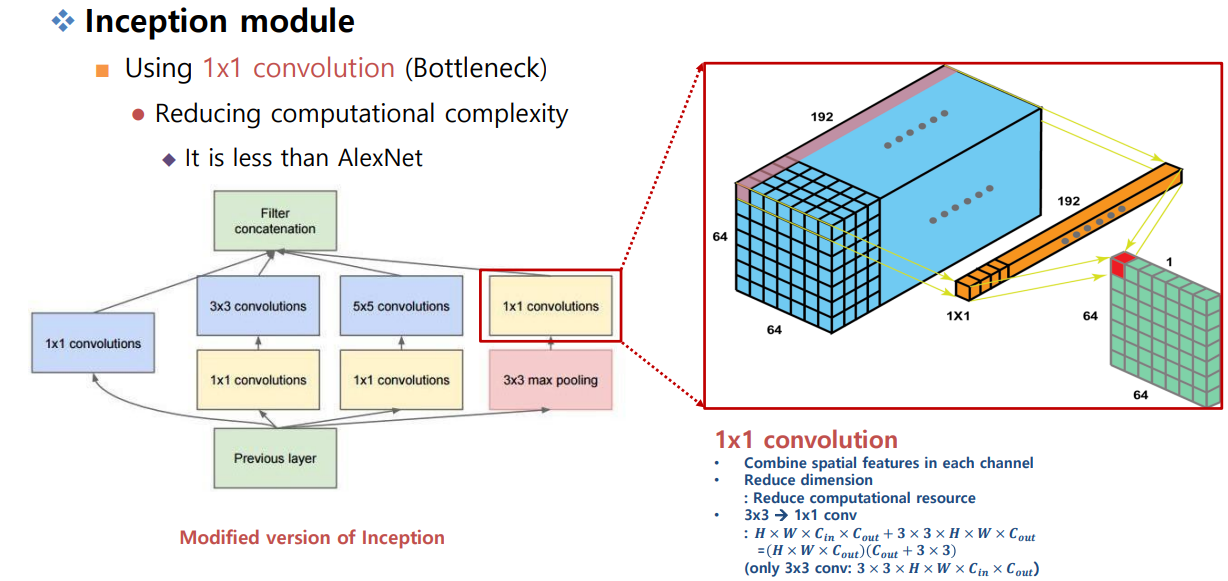
Pre-trained Model 개념
- Pre-trained Model (사전 학습 모델)은 대규모 데이터셋으로 이미 학습이 끝난 모델.
이 모델은 특정 문제를 풀기 위해서 처음부터 학습한 것이 아니라, 충분히 크고 일반적인 데이터셋에서 학습된 지식을 내포하고있음
- 입력에 가까운 레이어: Low-level feature (엣지, 색상, 질감 등).
- 출력에 가까운 레이어: High-level feature (객체의 의미론적 특징).
- 이런 계층적 구조 덕분에, 한 번 학습된 CNN은 단순히 원래 문제에서만 쓰이는 것이 아니라, 다른 문제에서도 충분히 활용 가능한 표현을 제공
이러한 특징은 다른 태스크에도 활용 가능. feature를 학습하는 파트에서 활용 + 당연히 Task가 다르다면 head는 달라야됨
Transfer Learning (전이학습)
Transfer Learning은 이렇게 사전에 학습된 지식을 새로운 태스크에 가져와 활용하는 방법을 의미한다.
왜 사용하는가?
예를 들어 MRI 의료 영상을 입력으로 받아 질병의 유무를 판별하고자 합다면. 처음부터 새로운 CNN을 학습시키려면 방대한 의료 데이터와 레이블이 필요하다.
하지만 의료 데이터는 부족하고, 수작업으로 레이블링을 하려면 비용도 많이 든다. 따라서 기존 CNN의 Feature Extractor 부분은 그대로 활용하고, 마지막 분류기(Classifier) 부분만 질병 유무를 판별하도록 새로 달아 학습시키는 방식이 필요하고 이것이 Transfer Learning이다. + 데이터가 충분히 많아도, Pre-trained Model의 지식을 끌어오면 성능을 더 끌어올릴 수 있음
- Transfer Learning의 시나리오
(1) Fine Tuning
이미 학습이 완료된 Pre-trained Model 전체를 새로운 데이터셋으로 다시 학습
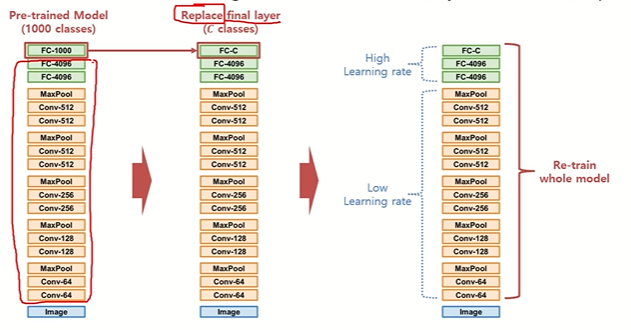
예를 들어, ImageNet 데이터셋으로 학습된 모델이 있다고 한다. 이 모델은 입력부터 CNN을 거쳐 Fully Connected Layer(천 개 클래스 분류기)로 이어지는 구조를 가지고 있다. 그런데 우리가 풀고자 하는 문제는 “정상, 음성, 양성”의 세 가지 분류 문제이다.
따라서 우리는 기존의 마지막 Fully Connected Layer(1000개 클래스용)는 떼어내고, 3개 클래스를 위한 새로운 레이어로 교체하고 이 모델 전체를 의료 데이터셋으로 다시 학습시키는 것이다.
여기서 중요한 점은:
- CNN의 Feature Extractor는 이미 충분히 학습되어 있으므로 Learning Rate을 작게 설정하여 조금만 수정
- 새롭게 교체한 Classifier는 처음부터 학습해야 하므로 Learning Rate을 크게 설정하여 적극적으로 업데이트
Fine Tuning의 의미는 랜덤 초기화에서 시작하지 않고, 이미 최적화된 지점 근처에서 시작, 즉 학습 속도가 빠르고, 적은 데이터로도 성능을 낼 수 있다.
(2) Feature Freezing
두 번째 시나리오는 Feature Extractor를 고정(Freeze) 해두고, 마지막 분류기만 학습하는 방식이다.
CNN이 이미 학습해둔 일반적인 Feature는 재사용하고, 새 태스크에 맞는 분류기 부분만 새로 학습. 보통 Convolutional Layer는 일반적인 특징(엣지, 텍스처, 색상 등)을 잘 학습하기 때문에 다른 태스크에도 유용하다.
반면 Fully Connected Layer는 원래 학습된 특정 태스크(예: 1000개 클래스 구분)에 특화되어 있기 때문에 그대로 쓰기 어렵다. 그래서 주로 Convolutional Layer는 고정하고, Classifier 부분만 새로 학습하는 방식을 많이 사용한다.
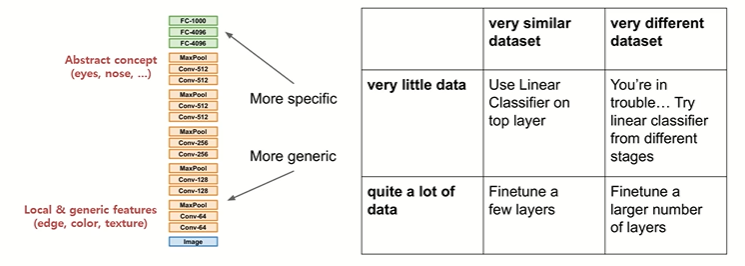
Freeze와 Fine Tuning의 선택 기준을 정해보자면
- 데이터가 적을 경우: 최대한 많은 부분을 Freeze하고, Classifier만 학습.
- 데이터가 많을 경우: Fine Tuning 범위를 넓혀서 CNN 일부 레이어까지 다시 학습.
- 기존 태스크와 비슷한 경우: Freeze 전략도 잘 작동.
- 기존 태스크와 다른 경우: Fine Tuning 필요.
+ 참고 Transfer Learning의 대표적 예가 GPT를 기반으로 한 ChatGPT
- GPT (Pre-trained Model): 원래는 단순히 다음 단어를 예측하는 모델. 질문에 대답하는 능력은 없음.
- 단계별 Transfer Learning:
- Supervised Fine Tuning: 질문–답변 데이터셋으로 학습시켜 “질문에 답변”할 수 있는 능력을 부여.
- Reward Model 학습: 사람이 답변 품질에 점수를 매기고, 이를 학습해 채점 모델(Reward Model) 생성.
- Reinforcement Learning with Human Feedback (RLHF): Reward Model을 활용해 GPT가 더 나은 답변을 하도록 최적화.
Knowledge distillation
지식 증류라고 불리며 큰 규모의 Teacher 모델이 가진 지식을 작은 규모의 Student 모델에게 전수하여, 작은 모델이 Teacher의 행동 양식을 모방하면서 학습하는 방법.

- Teacher 모델: 이미 학습된, 파라미터와 레이어 수가 많고 복잡한 모델.
- Student 모델: Teacher 모델을 모방하도록 학습되는 작은 모델
앙상블 모델 압축, 개별 기기의 데이터를 직접 서버에 전달하지 않고, 모델 지식(Knowledge)을 전달하는 Federated Learning, Self-Supervised Learning / Foundation Model 학습 이런곳에서 이용된다.
Knowledge Distillation 학습 방식
(1) Distillation Loss
Teacher와 Student의 출력 분포를 가깝게 맞추는 것.
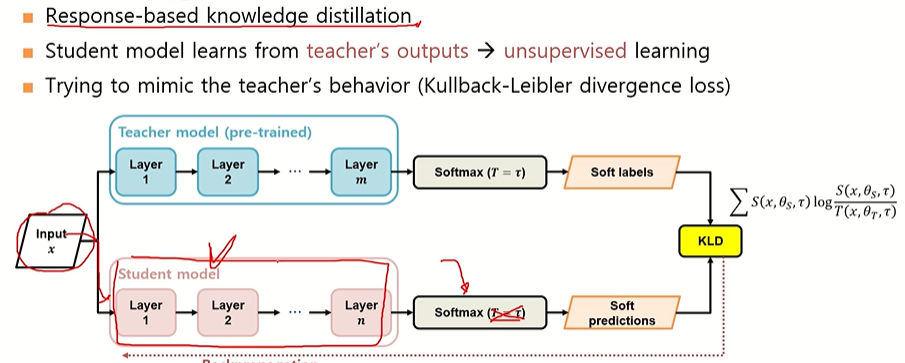
- Teacher와 Student의 softmax 확률 분포를 비교 → Kullback–Leibler Divergence (KLD) 사용.
- KL Divergence:
- 두 확률 분포(P, Q)가 동일하면 값 = 0.
- 다를수록 값 증가.
- Student의 출력이 Teacher의 확률 분포와 가까워지도록 학습.
(2) Temperature (T)
- Softmax에 T를 도입해 출력 확률의 차이를 조절.
- T=1 → 일반적인 softmax.
- T>1 → 확률 분포가 평탄해짐(차이 완화). → Label Smoothing 효과.

- 이를 통해 Teacher가 예측한 Dark Knowledge까지 Student가 학습할 수 있음.
- 예: Teacher가 "개" 확률 0.7, "고양이" 0.2, "소" 0.1로 출력한다면,
- Hard Label에서는 단순히 "개"가 정답.
- Soft Label에서는 "고양이"와 "소"에 대한 약간의 정보도 포함 → Student가 더 풍부한 지식 습득.
- 예: Teacher가 "개" 확률 0.7, "고양이" 0.2, "소" 0.1로 출력한다면,
+ 그럼 이건 지도학습인가 비지도학습인가?
- Student 모델은 Teacher의 soft label을 보고 학습.
- Teacher의 soft label은 사람이 달아준 Ground Truth(정답 레이블)가 아님.
- 따라서 KD는 엄밀히 말하면 Unsupervised Learning 성격을 가짐.
- 그러나 실제 학습에서는 Supervised Loss(정답 기반 Cross-Entropy Loss)와 함께 병행하여 사용하기도 함.
Distillation Loss + Student Loss

Distillation Loss (KL Divergence)
- Teacher의 Soft Label과 Student의 Soft Prediction을 유사하게 만들기.
- Teacher의 행동을 따라하도록 유도.
Student Loss (Cross Entropy Loss)
- 실제 Ground Truth Hard Label과 Student의 Prediction을 비교.
- 정답 분류 성능을 보장.
최종적으로 두 가지 Loss를 가중합(weighted sum)으로 사용한다
- Loss = α * Distillation Loss + β * Cross Entropy Loss ( 예: α=0.5, β=0.5 )
- 이렇게 하면 Student는 Teacher 지식도 계승하고, 정답도 맞히는 학습을 하게 되어 성능 향상.
https://light-tree.tistory.com/196
딥러닝 용어 정리, Knowledge distillation 설명과 이해
이 글은 제가 공부한 내용을 정리하는 글입니다. 따라서 잘못된 내용이 있을 수도 있습니다. 잘못된 내용을 발견하신다면 리플로 알려주시길 부탁드립니다. 감사합니다. Knowledge distillation 이란?
light-tree.tistory.com
https://baeseongsu.github.io/posts/knowledge-distillation/
딥러닝 모델 지식의 증류기법, Knowledge Distillation
A minimal, portfolio, sidebar, bootstrap Jekyll theme with responsive web design and focuses on text presentation.
baeseongsu.github.io
+ Semi-Supervised Learning 과 Self Training을 알아보자
기존 배경
- Supervised Learning: 모든 데이터에 라벨(정답)이 있는 경우 지도 학습.
- Unsupervised Learning: 라벨이 전혀 없는 경우 비지도 학습.
- Semi-Supervised Learning: 일부 데이터만 라벨이 있고 나머지는 라벨이 없는 상태에서 학습.
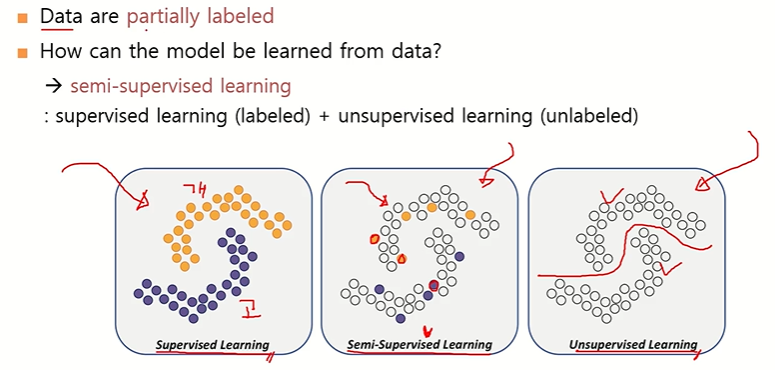
어떻게 Semi-Supervised Learning을 할까?

- Pseudo Labeling:
- 라벨이 있는 데이터로 먼저 모델(teacher)을 학습 → unlabeled 데이터에 대해 예측을 수행.
- 모델이 낸 예측값(불완전한 label)을 pseudo label로 사용하여 모든 데이터를 학습.
- 즉, "불완전한 라벨링을 이용해 데이터셋을 확장하는 방법".
- Consistency Loss 활용:
- unlabeled 데이터에 noise나 augmentation을 추가했을 때도 같은 prediction을 내도록 제약.
- 이를 통해 모델의 일관성을 유지하며 pseudo label의 불안정성을 보완
Self Training?

- Knowledge Distillation 결합:
- Teacher 모델(라벨 데이터로 학습된 모델)이 unlabeled 데이터에 대한 pseudo label 생성.
- Student 모델은 teacher의 출력과 유사해지도록 학습(Cross Entropy 또는 Distillation Loss 활용).
- 동시에 student 모델이 동일 데이터와 noise-added 데이터에 대해 같은 출력을 내도록 consistency loss를 적용.
- 라벨 데이터 활용:
- 라벨이 있는 데이터에 대해서는 당연히 hard label 기반 supervised loss를 적용하여 정확히 학습.
- Self Training 과정
- Teacher 모델을 라벨 데이터로 학습 (pre-training).
- Teacher가 unlabeled 데이터에 pseudo label 부여.
- Student 모델을 학습:
- Teacher의 예측과 일치하도록 (distillation loss).
- Noise 추가 버전과 일관성 유지(consistency loss).
- 라벨 데이터는 hard label로 supervised 학습.
- 학습된 student 모델이 teacher보다 성능이 좋아지면 → student를 새로운 teacher로 승격.
- 새로운 student를 초기화하여 다시 학습.
→ 이 과정을 반복하면 점점 더 성능이 향상.
결과
- 반복적인 teacher–student 교체를 통해 모델이 점점 정교해짐.
- 단순 supervised learning만 했을 때보다 성능이 더 높아질 수 있음.
- 실제 실험에서도 더 작은 모델임에도 정확도가 향상되는 결과가 보고됨.
'Technology Notes' 카테고리의 다른 글
| [OS] ARM 노트북에서 오류 0xc0e90001 해결 (USB 없이 초기화 ) (0) | 2025.06.04 |
|---|---|
| [Server] Window PuTTY로 원격 접속하기 (0) | 2025.05.07 |
| [Deep Learning] 딥러닝 모델 모바일 최적화 알아보기 (0) | 2025.04.13 |
| [Framework] Flask-RESTX와 Swagger UI 사용해보기 (0) | 2025.04.11 |
| [Deep Learning] Anomaly Detection(이상치 탐지)를 알아보자 (0) | 2025.04.09 |