이 리뷰는 오직 학습과 참고 목적으로 작성되었으며, 해당 논문을 통해 얻은 통찰력과 지식을 공유하고자 하는 의도에서 작성된 것입니다. 본 리뷰를 통해 수익을 창출하는 것이 아니라, 제 학습과 연구를 위한 공부의 일환으로 작성되었음을 미리 알려드립니다.
이 논문은 로봇 파운데이션 모델, 즉 GPT 같은 거대 모델을 로봇에 접목시키기 위해 지금 산업계 그리고 학계에서는 어떤 연구들이 진행되고 있는지, LLM(대형 언어 모델)과 VLM(비전-언어 모델)이 로봇의 의사결정, 강화학습, 태스크 플래닝에 어떻게 적용되는지를 다룬다.
R. Firoozi, J. Tucker, S. Tian, A. Majumdar, J. Sun, W. Liu, Y. Zhu, S. Song, A. Kapoor, K. Hausman, B. Ichter, D. Driess, J. Wu, C. Lu, and M. Schwager, "Foundation Models in Robotics: Applications, Challenges, and the Future," arXiv preprint arXiv:2312.07843, Dec. 2023. [Online]. Available: https://arxiv.org/abs/2312.07843.
Abstract
이 논문은 로봇 공학에서 사전 훈련된 기초 모델의 응용에 대해 다룹니다. 전통적인 딥러닝 모델은 특정 작업에 맞춘 작은 데이터셋으로 훈련되어 적응성이 제한되지만, 기초 모델은 인터넷 규모의 데이터로 훈련되어 뛰어난 일반화 능력을 보이고, 때로는 훈련 데이터에 없는 문제에 대해서도 제로샷 솔루션을 제시할 수 있습니다. 기초 모델은 로봇의 인식, 의사결정, 제어 등 다양한 영역에서 자율성 향상에 기여할 수 있으며, 예를 들어, 대형 언어 모델은 코드 생성과 상식적인 추론을, 비전-언어 모델은 개방형 어휘 시각 인식을 가능하게 합니다. 그러나 로봇 관련 훈련 데이터 부족, 안전성, 불확실성 정량화, 실시간 실행 등의 도전 과제가 존재합니다. 이 논문에서는 기초 모델이 로봇의 능력을 향상시키는 방법을 논의하고, 향후 발전을 위한 기회와 경로를 제시합니다.
I. INTRODUCTION
기초 모델(Foundation models)은 광범위한 인터넷 데이터를 바탕으로 사전 훈련되어 다양한 로봇 작업에 적응할 수 있습니다. 기초 모델은 자율 주행, 산업 로봇, 의료 로봇 등 다양한 로봇 분야에서 새로운 가능성을 열 수 있는 잠재력을 가지고 있습니다. 기존의 딥러닝 모델들이 제한된 데이터셋에 의존했지만, 기초 모델은 다양한 데이터로 훈련되어 높은 적응성과 성능을 자랑합니다. 특히 Multimodal foundation models 은 로봇이 환경을 인식하고 추론하는 데 유용한 표현을 생성하며, 제로샷 학습을 통해 로봇이 새로운 상황에 잘 적응할 수 있게 합니다.
기초 모델은 로봇의 인식, 의사결정, 제어 등 여러 분야에서 유용하게 활용될 수 있습니다. 예를 들어, 대형 비전-언어 모델(VLM)은 제로샷 이미지 분류와 객체 탐지 등의 작업을 지원하고, 언어 모델은 로봇의 정책 학습과 계획 수립에 기여할 수 있습니다. 또한, 기초 모델은 로봇이 새로운 환경에서 자율적으로 작업을 수행하도록 돕는 잠재력을 가지고 있습니다.
하지만 기초 모델을 실제 로봇 작업에 적용하는 데는 여러 도전 과제가 존재합니다. 주요 도전 과제에는 데이터 부족, 높은 변동성, 불확실성 정량화, 안전성 평가, 실시간 성능 문제가 포함됩니다.
이 설문에서는 기초 모델이 로봇 공학에서 어떻게 응용되는지, 현재의 도전 과제, 향후 연구 방향과 기회, 그리고 잠재적 위험 요소에 대해 논의합니다. 또한, 본 논문은 기초 모델을 로봇 시스템에 적용한 연구들을 분석하고, 이들 간의 비교 및 다양한 연구 주제를 연결하는 더 넓은 관점을 제공합니다.
구조:
- 섹션 II: 기초 모델에 대한 소개 (LLM, 비전 트랜스포머, VLM 등)와 훈련 방법
- 섹션 III: 로봇 공학에서 기초 모델의 의사결정 작업에 대한 통합 방법
- 섹션 IV: 기초 모델이 향상시킬 수 있는 다양한 로봇 인식 작업
- 섹션 V: 구현된 AI 에이전트 및 시뮬레이터/벤치마크
- 섹션 VI: 기초 모델을 로봇 시스템에 적용하는 데 있어 도전 과제와 연구 방향
- 섹션 VII: 결론
II. FOUNDATION MODELS BACKGROUND
A. Foundation Models
이 섹션은 대규모 기초 모델의 배경과 기초에 대해 심층적으로 다루고 있으며, 이러한 모델들이 AI 및 기계 학습 시스템에서 어떻게 사용되는지, 훈련 과정에서의 도전 과제와 자원 소모를 설명한다.

파운데이션 모델?
https://blogs.nvidia.co.kr/blog/what-are-foundation-models/
파운데이션 모델이란 무엇인가? | NVIDIA Blog
1956년에 마일즈 데이비스 퀸텟(Miles Davis Quintet)은 프레스티지 레코드 사의 스튜디오에서 라이브 연주를 녹음하고 있었습니다.
blogs.nvidia.co.kr
- 기초 모델(Foundation Models):
- 이는 수십억 개의 파라미터를 가진 대규모 기계 학습 모델로, 인터넷에서 수집된 방대한 데이터셋을 바탕으로 사전 훈련됩니다.
- 이러한 모델은 매우 복잡하여 훈련에 많은 계산 자원(GPU나 TPU 등)을 요구하고, 이에 따른 상당한 재정적 투자가 필요합니다.
- 이러한 모델은 대개 "플러그 앤 플레이" 방식으로 사용됩니다. 즉, 광범위한 맞춤화 없이 다양한 애플리케이션에 통합할 수 있습니다.
- 훈련 과정:
- 비용: 기초 모델을 훈련하는 데는 하드웨어 외에도 데이터 획득, 처리 및 관리에 드는 비용이 큽니다.
- 시간: 훈련 과정은 시간이 많이 소요되어 전체 비용이 더욱 증가합니다.
- 토큰화(Tokenization):
- 토큰화는 텍스트와 같은 시퀀스를 작은 단위인 토큰으로 나누는 과정입니다. 이 토큰은 문자, 단어 또는 다른 하위 구조일 수 있습니다.
- 이러한 토큰은 벡터로 표현되며 LLM(대형 언어 모델) 같은 모델의 입력으로 사용됩니다.
- 토큰화는 자연어뿐만 아니라 이미지나 로봇의 행동과 같은 다른 모달리티에도 적용되어 이들 또한 시퀀셜 데이터로 처리하여 모델을 훈련할 수 있습니다.
- 생성 모델(Generative Models) vs 판별 모델(Discriminative Models):
- 생성 모델: 훈련 데이터에서 발생할 수 있는 데이터를 샘플링하여 데이터를 생성하는 모델입니다. 예를 들어, 얼굴 생성 모델은 훈련 데이터와 유사한 얼굴 이미지를 생성할 수 있습니다.
- 판별 모델: 분류나 회귀와 같은 작업을 위해 사용되며, 다른 클래스나 범주를 구별하는 데 초점을 맞춥니다.
- 트랜스포머 아키텍처(Transformer Architecture):
- 트랜스포머(Transformer) 아키텍처는 대형 기초 모델, 특히 LLM의 주요 혁신 중 하나입니다. 이 아키텍처의 핵심 특징은 멀티헤드 셀프 어텐션(Multi-Head Self-Attention) 메커니즘입니다.
- 멀티헤드 셀프 어텐션: 각 토큰이 다른 토큰들과 얼마나 강하게 연관되는지 평가하는 기법입니다. 여러 개의 어텐션 헤드를 사용해 각각 다른 유사성을 학습합니다.
- 병렬 처리: 트랜스포머는 토큰을 동시에 처리할 수 있어 이전의 RNN이나 LSTM 모델보다 빠른 훈련과 추론을 가능하게 합니다.
- 트랜스포머(Transformer) 아키텍처는 대형 기초 모델, 특히 LLM의 주요 혁신 중 하나입니다. 이 아키텍처의 핵심 특징은 멀티헤드 셀프 어텐션(Multi-Head Self-Attention) 메커니즘입니다.
- 자기회귀 모델(Autoregressive Models):
- 자기회귀 모델은 시퀀스의 다음 데이터를 예측하는 데 과거 데이터를 사용하는 모델입니다. 예를 들어, GPT 모델은 이전 토큰들을 바탕으로 다음 토큰을 예측합니다.
- GPT는 텍스트 예측 작업을 위해 자기회귀 방식을 사용하며, 텍스트의 각 단어를 순차적으로 예측합니다.
- 마스크드 자동 인코딩(Masked Auto-Encoding):
- BERT와 같은 모델은 마스크드 자동 인코딩을 사용하여 자기회귀 모델의 한계를 극복합니다. 이 방식은 입력 시퀀스의 일부 토큰을 마스킹하고, 모델이 이를 예측하게 하여 문맥을 양방향으로 학습할 수 있게 합니다.
- 대조 학습(Contrastive Learning):
- CLIP와 같은 시각-언어 모델(VLM)은 대조 학습을 사용하여 학습합니다. 대조 학습은 서로 다른 모달리티(예: 이미지와 텍스트) 사이의 유사성을 학습하여 비슷한 샘플 쌍을 더 가까운 임베딩 공간에 배치합니다.
- 확산 모델(Diffusion Models):
- DALL-E2와 같은 이미지 생성에 사용되는 또 다른 유형의 생성 모델입니다. 확산 모델은 이미지에 노이즈를 추가한 후 이를 제거하여 현실적인 이미지를 생성하는 과정입니다.
- 모델은 노이즈를 추가하는 순방향 과정과 이를 되돌리는 역방향 과정을 학습합니다.
기초 모델 훈련 이론과 방법에 대한 포괄적인 개요를 제공하며, 트랜스포머 아키텍처, 학습 방식(자기회귀, 마스크드 자동 인코딩, 대조 학습) 및 생성 작업(텍스트, 이미지 생성)에서의 응용을 강조합니다.
B. 대형 언어 모델(LLM) 예시 및 역사적 배경
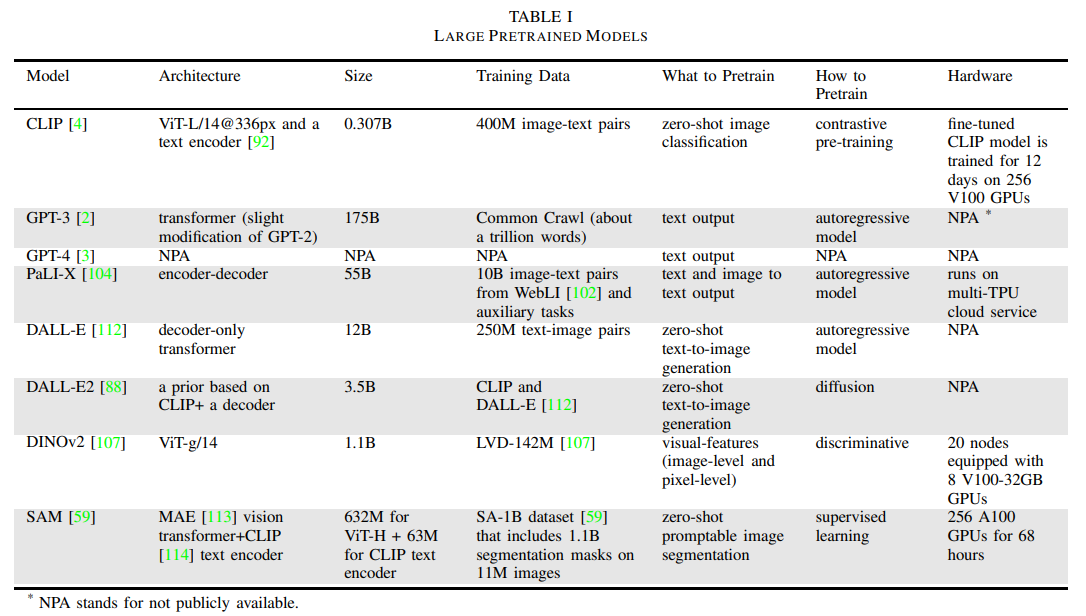
대형 언어 모델(LLM)은 수십억 개의 파라미터를 가지고 있으며, 수조 개의 토큰으로 훈련됩니다. 이러한 대규모 덕분에 GPT-2와 BERT는 각각 Winograd Schema 챌린지와 일반 언어 이해 평가(GLUE) 벤치마크에서 최첨단 성과를 달성할 수 있었습니다. 이들의 후속 모델인 GPT-3, LLaMA, PaLM은 파라미터 수가 크게 증가했으며(현재는 1000억 개 이상), 컨텍스트 윈도우의 크기(현재는 1000개 이상의 토큰)와 훈련 데이터셋의 크기(현재는 수십 테라바이트의 텍스트)에 있어서도 크게 확장되었습니다. GPT-3는 Common Crawl 데이터셋으로 훈련됩니다. Common Crawl은 12년간의 웹 크롤링을 통해 얻은 페타바이트 규모의 공개 데이터로, 원본 웹 페이지 데이터, 메타데이터, 텍스트 추출물이 포함되어 있습니다. LLM은 다국어 모델로도 사용할 수 있습니다. 예를 들어, ChatGLM-6B와 GLM-130B는 1300억 개의 파라미터를 가진 영어-중국어 이중 언어 모델입니다. 또한, LLM은 미세 조정(fine-tuning)이 가능하여, 특정 도메인 데이터를 사용해 모델의 성능을 특정 용도에 맞게 조정할 수 있습니다. 예를 들어, GPT-3와 GPT-4는 인간 피드백을 통한 강화 학습(RLHF)으로 미세 조정되었습니다.
C. 비전 트랜스포머(Vision Transformers)
비전 트랜스포머(ViT)는 이미지 분류, 분할(segmentation), 객체 탐지 등의 컴퓨터 비전 작업을 위한 트랜스포머 아키텍처입니다. ViT는 이미지를 일련의 이미지 패치로 처리하며, 이를 토큰이라고 부릅니다. 이미지 토큰화 과정에서 이미지는 고정 크기의 패치로 나누어지며, 각 패치는 1차원 벡터로 펼쳐져 선형 임베딩(linear embedding)이 됩니다. 각 토큰에 위치 정보를 추가하여 공간적 관계를 캡처하는데, 이를 위치 임베딩(position embedding)이라고 합니다. 위치 인코딩이 포함된 이미지 토큰은 트랜스포머 인코더에 입력되고, 셀프 어텐션(self-attention) 메커니즘을 통해 모델은 입력 데이터의 장기 의존성과 전역 패턴을 캡처할 수 있습니다. 이 논문에서는 파라미터 수가 많은 ViT 모델들에 대해 다룹니다. 예를 들어, ViT-G는 20억 개의 파라미터를 가지고 있으며, ViT-e는 40억 개의 파라미터를 가집니다. ViT-22B는 220억 개의 파라미터를 가진 비전 트랜스포머 모델로, PaLM-E와 PaLI-X에 사용되어 로보틱스 작업을 지원합니다.
DINO는 ViT 훈련을 위한 자기 지도 학습(self-supervised learning) 방법으로, 레이블 없이 지식 증류(knowledge distillation)를 수행합니다. 지식 증류는 작은 모델(학생 네트워크)이 더 크고 복잡한 모델(교사 네트워크)의 동작을 모방하도록 훈련되는 학습 프레임워크입니다. 두 네트워크는 같은 아키텍처를 가지지만 파라미터 집합이 다릅니다. DINOv2는 다양한 훈련된 비전 모델을 제공하며, LVD-142M 데이터셋을 사용하여 훈련됩니다.
D. 다중 모달 비전-언어 모델(VLMs)
다중 모달 모델은 이미지, 텍스트, 오디오 신호 등 다양한 "모달리티"의 입력을 처리할 수 있는 모델입니다. 비전-언어 모델(VLM)은 이미지와 텍스트를 모두 입력으로 받아들이는 다중 모달 모델의 일종입니다. 로보틱스 애플리케이션에서 널리 사용되는 VLM은 대조적 언어-이미지 사전 훈련(CLIP)입니다.
CLIP은 텍스트 설명과 이미지 간의 유사성을 비교하는 방법을 제공합니다. CLIP은 인터넷에서 수집된 이미지-텍스트 쌍 데이터를 사용하여 이미지와 텍스트 간의 의미적 정보를 캡처합니다. CLIP 모델 아키텍처는 텍스트 인코더와 이미지 인코더(비전 트랜스포머 ViT의 수정된 버전)로 구성되어 있으며, 두 인코더는 이미지를 텍스트 임베딩과의 코사인 유사도를 최대화하도록 함께 훈련됩니다. CLIP은 대조 학습을 사용하여 언어 모델과 시각적 특징 인코더를 결합해 제로샷 이미지 분류를 수행합니다.
BLIP는 이미지-텍스트 대조 손실, 이미지-텍스트 매칭 손실, 언어 모델링 손실을 포함하는 세 가지 목표를 공동 최적화하는 방식으로 다중 모달 학습을 진행합니다. CLIP2는 텍스트-이미지-포인트 간 정렬된 표현을 학습합니다. FILIP은 비주얼-텍스트 토큰 간의 토큰별 최대 유사도를 사용해 대조 학습을 통해 더 정밀한 정렬을 달성합니다.
E. 구체화된 다중 모달 언어 모델
구체화된 에이전트(embodied agent)는 가상 또는 물리적 세계와 상호작용하는 AI 시스템입니다. 예를 들어, 가상 비서나 로봇이 이에 해당합니다. 구체화된 언어 모델은 사전 훈련된 대형 언어 모델에 실제 세계의 센서 및 액추에이터 모달리티를 통합하는 모델입니다. 일반적인 비전-언어 모델은 이미지 캡션 생성이나 시각적 질문 응답과 같은 일반적인 비전-언어 작업에 훈련됩니다. PaLME는 인터넷 규모의 일반 비전-언어 데이터와 구체화된 로보틱스 데이터를 동시에 훈련한 다중 모달 언어 모델입니다. PaLME는 이미지, 저수준 상태, 3D 신경 장면 표현과 같은 연속적인 입력을 언어 임베딩 공간에 주입하여 모델이 텍스트와 다른 모달리티를 공동으로 추론할 수 있게 합니다. PaLME는 PaLM LLM과 ViT로 구성됩니다.
F. 시각적 생성 모델
웹 규모의 확산 모델(예: OpenAI의 DALL-E 및 DALL-E2)은 제로샷 텍스트-이미지 생성을 제공합니다. 이러한 모델은 인터넷에서 수집된 수억 개의 이미지-캡션 쌍을 학습하여 주어진 프롬프트에 따라 이미지를 생성할 수 있습니다. DALL-E2 아키텍처는 텍스트 캡션으로부터 CLIP 이미지 임베딩을 생성하는 프라이어와, 이 임베딩을 기반으로 이미지를 생성하는 디코더로 구성됩니다.
III. ROBOTICS
이 부분은 로봇의 의사결정, 계획, 제어에서 대형 언어 모델(LLM)과 시각 언어 모델(VLM)의 통합을 다루고 있습니다. 주요 내용은 조작과 강화 학습 작업을 중심으로 설명됩니다.
예를 들어, 대형 언어 모델(LLM)은 로봇이 인간의 고차원적인 지시를 받아들여 해석할 수 있게 하여, 작업 명세화 과정에 도움을 줄 수 있습니다. 비전-언어 모델(VLM)도 이 분야에 기여할 가능성을 지니고 있습니다. VLM은 시각적 데이터를 분석하는 데 특화되어 있으며, 이 시각적 이해는 로봇의 정보에 기반한 의사결정 및 복잡한 작업 수행에 중요한 요소입니다. 로봇은 이제 자연어 힌트를 활용하여 조작, 내비게이션 및 상호작용 작업에서 성능을 향상시킬 수 있습니다.
비전-언어 목표 조건 정책 학습(Vision-Language Goal-Conditioned Policy Learning)은 모방 학습 또는 강화 학습을 통해 기초 모델을 활용한 성능 향상을 기대할 수 있습니다. 또한 언어 모델은 정책 학습 기술에 대한 피드백을 제공하는 역할을 합니다. 이 피드백 루프는 로봇이 LLM으로부터 받은 피드백을 바탕으로 행동을 개선할 수 있게 하여 로봇의 의사결정 능력을 지속적으로 향상시킵니다. 이 섹션은 로봇 의사결정에서 LLM과 VLM의 기여 가능성을 강조합니다.
대부분의 논문들이 하드웨어 실험에 의존하거나, 저수준 제어 및 계획 스택에 맞춰 커스텀 요소를 사용하는 실험을 기반으로 하고 있어 다른 하드웨어나 실험 설정으로 쉽게 전이할 수 없거나, 비물리적 시뮬레이터를 사용하여 이러한 저수준 부분을 무시하면서도, 서로 다른 하드웨어 구현 간의 비전이 문제를 남기기 때문입니다.
A. 로봇 정책 학습을 통한 의사결정 및 제어 (Robot Policy Learning for Decision Making and Control)
언어 조건 모방 학습(language-conditioned imitation learning)과 언어 보조 강화 학습(language-assisted reinforcement learning)을 포함한 로봇 정책 학습을 다룹니다. 그리고 로봇이 사람의 지시를 이해하고 그에 맞는 행동을 할 수 있도록 학습하는 방법에 대해 설명합니다. 주로 두 가지 방법을 다룹니다: 언어 조건 모방 학습과 언어 보조 강화 학습.
언어 조건 모방 학습을 통한 조작
- 언어 조건 모방 학습은 로봇이 사람의 언어 지시에 맞춰서 행동을 배우는 방식입니다.
- 예를 들어, "책을 오른쪽으로 밀어라"라는 지시를 받은 로봇이 실제로 책을 오른쪽으로 밀 수 있도록 학습하는 것입니다.
- 이 과정에서 로봇은 언어 지시와 실제 시연 데이터를 바탕으로 학습을 합니다. 이때, 로봇은 특정한 목표(예: 책을 밀기)와 상황에 맞는 행동을 하는 법을 배웁니다.
- 주요 도전 과제는 충분한 학습 데이터와 다양한 상황에서의 학습을 확보하는 것입니다. 또한, 로봇이 예상하지 못한 상황에 직면했을 때 잘못된 행동을 할 위험이 있습니다.
https://jhrobotics.tistory.com/37
[RL] Imitation Learning(모방 학습)에 대한 설명 및 정리
Author: Joonhee Lim Date: 2022/08/23 참고한 블로그: https://cding.tistory.com/71 https://reinforcement-learning-kr.github.io/2019/01/22/0_lets-do-irl-guide/ 0. Motivation 필자는 강화학습에 대해 지속적으로 공부도 하고 실제로 학
jhrobotics.tistory.com
이러한 문제를 해결하기 위해 Play-LMP라는 방법이 제안되었습니다. 이 방법은 텔레조작(사람이 직접 조작)을 통해 데이터를 얻고, 로봇이 실제 환경에서 계획을 세워서 목표를 달성할 수 있도록 도와줍니다.
추가적으로, MCIL이라는 방법도 소개됩니다. 이는 여러 가지 다른 상황을 고려해서 로봇이 다양한 목표를 학습할 수 있도록 돕는 방법입니다.
언어 보조 강화 학습
- 강화 학습(RL)은 로봇이 환경과 상호작용하면서 점점 더 좋은 행동을 배우는 방법입니다.
- 예를 들어, 로봇이 장애물을 피하는 방법을 배우기 위해 환경에서 계속 실험을 하며 점차적으로 더 나은 행동을 찾습니다.
- 최근에는 LLM(대형 언어 모델)과 VLM(비전-언어 모델)을 결합하여, 로봇이 복잡한 작업을 쉽게 분해하고 잘 수행할 수 있도록 돕는 방법이 연구되고 있습니다.
B. 언어-이미지 목표 조건 가치 학습 (Language-Image Goal-Conditioned Value Learning)
이 부분에서는 로봇이 목표를 더 잘 이해하고 그에 맞는 행동을 선택할 수 있도록 도와주는 방법을 설명합니다.
R3M
- R3M은 사람의 비디오 데이터를 통해 로봇이 어떻게 특정 작업을 해야 하는지 배우는 방법입니다. 이를 통해 로봇은 시간에 따른 변화를 학습하고, 비디오와 언어를 함께 분석하면서 더 정확한 목표를 설정할 수 있습니다.
LIV ( Language-Image Value Learning )
- LIV는 로봇이 언어나 이미지 목표를 기반으로 작업을 학습하는 방법입니다.
- 예를 들어, 로봇이 특정 이미지를 보고 그 이미지를 기반으로 목표를 설정하거나, 특정 언어 지시를 통해 작업을 수행하는 방식입니다.
- CLIP과 VIP라는 모델을 결합하여, 로봇이 다양한 형태의 목표(이미지, 언어 등)를 이해하고 여러 상황에서 작업을 수행할 수 있도록 돕습니다.
C. 대형 언어 모델(LLM)을 이용한 로봇 작업 계획 (Robot Task Planning using Large Language Models)
이 섹션에서는 대형 언어 모델(LLM)을 사용해 로봇이 복잡한 작업을 계획하고 실행하는 방법에 대해 다룹니다. LLM은 주로 긴 시간 동안의 작업을 계획하는 데 사용됩니다.
1) 언어 지시를 통한 작업 지정 (Language Instructions for Task Specification)
- SayCan이라는 시스템은 LLM을 사용하여 로봇에게 높은 수준의 작업 계획을 지시합니다. 이 시스템은 환경에 맞는 가치 함수를 학습하여 언어 지시가 실제 환경에서 어떻게 실행될지 이해할 수 있게 합니다.
- 시간 논리(Temporal Logic)를 사용하면 로봇이 작업을 수행하는 데 필요한 시간적 제약을 정의할 수 있습니다. 예를 들어, 자연어에서 시간 논리로 번역하는 방법을 제시한 연구도 있습니다. 이 연구에서는 T5 모델을 사용해 자연어와 시간 논리를 연결하는 방법을 학습합니다.
- 또한, 자연어를 중간 작업 표현으로 변환하여 로봇이 작업을 계획하고 실행할 수 있도록 돕는 연구도 있습니다. 이 방법은 특히 로봇 내비게이션에 유용하며, Task and Motion Planning (TAMP) 알고리즘을 사용하여 작업과 동작을 최적화합니다.
2) 작업 계획을 위한 코드 생성 (Code Generation using Language Models for Task Planning)
- 전통적인 작업 계획은 많은 도메인 지식과 큰 검색 공간을 필요로 합니다. 하지만 LLM을 사용하면, 도메인 지식 없이도 고수준의 작업을 달성하는 데 필요한 작업의 순서를 생성할 수 있습니다.
- ProgPrompt라는 방법에서는 LLM을 사용하여 작업 순서를 생성합니다. 예를 들어, 사용자가 지시한 작업을 수행하기 위해 필요한 행동들을 LLM이 자동으로 생성합니다. 이때, 환경에 있는 객체나 가능한 행동들을 설명하는 프롬프트를 제공하여 LLM이 작업을 계획하도록 합니다.
- Code-as-Policies는 LLM을 사용하여 로봇 정책 코드를 생성하는 방법을 제시합니다. 이 방식은 로봇이 물체를 조작하거나 내비게이션할 때 필요한 동작을 수행하는 코드들을 자연어로부터 자동으로 생성할 수 있습니다. 이 과정에서는 프롬프트를 통해 LLM이 주어진 명령에 맞는 정책 코드를 작성하도록 유도합니다. 이 방법은 다양한 로봇 환경에서 실제로 적용 가능합니다.
D. In-context Learning (ICL)을 통한 의사결정 (In-context Learning for Decision-Making)
- In-context Learning (ICL)은 파라미터 최적화 없이 프롬프트 안에 포함된 예시들만을 기반으로 학습하는 방식입니다. 주로 프롬프트 엔지니어링과 연결되며, 복잡한 문제를 해결할 때 체인 오브 쏘트(Chain-of-Thought) 기법을 사용하여 단계적으로 문제를 해결합니다.
- ICL을 통해 LLM은 오프라인 경로 최적화나 온라인 강화 학습과 같은 작업을 효과적으로 처리할 수 있습니다. 예를 들어, 로봇이 특정 작업을 수행할 때 하위 목표를 달성하는 순서를 학습하는 방식입니다.
- 체인 오브 쏘트 예측 제어(Chain-of-Thought Predictive Control) 기법에서는 로봇이 데모 시연에서 특정 단계적 사고를 통해 작업을 학습할 수 있도록 돕습니다.
E. 로봇 트랜스포머 (Robot Transformers)
- 트랜스포머 모델은 로봇의 제어, 인식, 의사결정, 행동 생성을 결합하는 통합 프레임워크로 사용될 수 있습니다.
- 자기 지도 시각적 학습(self-supervised visual pretraining)은 실시간 이미지 데이터를 사용해 로봇이 다양한 동작을 학습하는 데 유용합니다. 예를 들어,로봇이 픽셀 입력을 통해 제어 작업을 배우는 방법을 제시합니다. 이는 로봇이 다양한 작업을 수행하는 데 필요한 시각적 표현을 학습하는 과정입니다.
- RT-1 모델은 130,000개 이상의 실제 로봇 경험 데이터를 바탕으로 훈련되며, 이미지와 자연어 지시를 입력받아 디스크리트화된 동작을 생성합니다. 이 모델은 새로운 작업에 잘 일반화되며, 환경 변화에도 적응할 수 있습니다.
- RT-2는 Vision-Language-Action (VLA) 모델로, 웹과 로봇 데이터를 함께 학습하여 로봇의 제어 동작을 생성합니다. 이를 통해 로봇은 복잡한 작업을 멀티스테이지로 처리할 수 있습니다.
- RT-X는 다양한 로봇 데이터를 통합하여 로봇 간 경험 전이를 촉진하고, 여러 로봇이 서로의 경험을 통해 성능을 향상시킬 수 있도록 돕습니다.
- PACT는 자기 지도 학습을 통해 로봇이 안전한 동작을 학습하고, 자율적으로 로봇의 상태와 동작을 예측하는 능력을 키울 수 있도록 합니다.
- SMART는 다중 작업을 수행하는 제어 트랜스포머로, 로봇이 다양한 제어 작업을 효율적으로 학습하고 적응할 수 있도록 돕습니다.
이 연구들은 트랜스포머 모델을 사용하여 로봇이 복잡한 작업을 학습하고 다양한 환경에서 잘 작동하도록 하는 방법을 제시합니다. 시각적 인식, 언어 모델링, 정책 학습 등을 결합하여 로봇이 실시간으로 효율적이고 정확한 동작을 수행할 수 있도록 돕습니다.
F. Open-Vocabulary Robot Navigation and Manipulation
1) Open-Vocabulary Navigation
오픈 어휘 내비게이션은 로봇이 고정된 데이터셋에 의존하지 않고 언어를 사용하여 보지 못한 환경을 탐색하는 데 중점을 둡니다. 이 분야의 주요 발전은 대형 언어 모델(LLM)과 비전-언어 모델(VLM)을 통합하여 로봇이 자연어 지시를 이해하고 반응할 수 있게 하는 것입니다.
- VLN-BERT와 LM-Nav: 이 시스템들은 시각적 내비게이션을 위해 시각과 언어 모델을 활용합니다. VLN-BERT는 지시문(예: “갈색 소파에서 멈추세요”)을 파노라마 이미지를 사용하여 매칭시키고, LM-Nav는 사전 훈련된 모델(GPT-3와 같은 LLM, CLIP과 같은 VLM, 그리고 Visual Navigation Model)을 결합하여 텍스트 지시를 기반으로 로봇을 환경 속에서 안내합니다.
- ViNT: 다양한 데이터셋과 플랫폼을 기반으로 훈련된 이미지 목표 내비게이션을 위한 기초 모델로, 제로 샷 내비게이션을 수행할 수 있으며 다양한 로봇 시스템에 적응할 수 있습니다.
- AVLMaps: 오디오, 비주얼, 언어 신호를 사용하는 제로 샷 내비게이션 시스템으로, 로봇 내비게이션을 위한 3D 공간 맵을 생성합니다.
- 비교 연구: 모듈형 학습 방법과 엔드 투 엔드 학습 방법을 비교하는 연구는, 엔드 투 엔드 시스템이 시뮬레이션과 실제 간의 차이 때문에 어려움을 겪는 반면, 모듈형 시스템이 실제 환경에서 더 잘 작동한다고 밝혔습니다.
- 객체 내비게이션: 이 작업에서는 로봇이 언어를 사용하여 객체를 찾아 목표로 삼고 탐색합니다. 오픈 어휘 분류기(CLIP 등)는 이미지와 설명 간의 유사성을 계산하여 로봇이 보지 못한 환경에서 객체를 탐색하고 찾을 수 있게 합니다.
2) Open-Vocabulary Manipulation
이는 로봇이 이전에 만난 적이 없는 환경에서 객체를 조작하는 능력과 관련이 있습니다. 언어 및 다중 모달 신호를 사용하여 수행됩니다.
- VIMA (VisuoMotor Attention Agent): 작업 지시와 이전 상호 작용을 조건으로 모터 명령을 예측하는 변환기 기반의 에이전트로, 제로 샷 일반화를 통해 다양한 조작 작업을 수행할 수 있습니다.
- RoboCat: 자기 개선 AI 에이전트로, 1.18B 파라미터를 가진 디코더 전용 변환기를 사용하여 로봇 팔을 조작하고 100개 이하의 시연만으로 작업을 해결하며, 자기 생성 데이터를 통해 성능을 향상시킵니다.
- StructDiffusion: 자연어 지시와 부분적인 시점 구름을 사용하여 로봇이 객체의 목표 구성을 예측하고 조작할 수 있도록 돕습니다.
- MOO (Manipulation of Open-World Objects): Owl-ViT와 RT-1과 같은 사전 훈련된 비전-언어 모델을 활용하여, 로봇이 이미지와 지시에서 객체 중심 정보를 추출하고 이를 조건으로 조작 정책을 학습하여 오픈 월드 환경에서 객체를 조작할 수 있게 합니다.
- DALL-E-Bot: DALL-E2 이미지 확산 모델을 사용하여 객체를 자율적으로 재배치하는 시스템입니다. 이 시스템은 추가적인 훈련 없이 자연어 지시를 통해 인간처럼 객체를 재배치하는 작업을 수행할 수 있습니다.
IV. PERCEPTION
로봇은 주변 환경과 상호작용할 때 이미지, 비디오, 오디오, 언어와 같은 다양한 양식의 원시 감각 정보를 수신합니다. 이러한 고차원적인 데이터는 로봇이 환경을 이해하고, 추론하며, 상호작용하는 데 필수적입니다. 비전 및 자연어 처리(NLP) 분야에서 개발된 기초 모델들은 이러한 고차원적인 입력을 보다 쉽게 해석하고 조작할 수 있는 추상적이고 구조화된 표현으로 변환하는 유망한 도구입니다.
특히, 다중 모달 기초 모델들은 로봇이 서로 다른 감각 입력을 결합하여 의미적, 공간적, 시간적, 가능성 정보 등을 포괄하는 통합된 표현으로 만들 수 있도록 돕습니다. 이러한 다중 모달 모델들은 모달리티 간의 교차 모달 상호작용을 반영하며, 일관성과 대응성을 보장하기 위해 모달리티 간 요소들을 정렬하는 방식으로 동작합니다. 예를 들어, 이미지 캡셔닝 작업을 위해 텍스트와 이미지 데이터가 정렬됩니다. 이 섹션에서는 다중 모달 모델을 사용하여 로봇 인식 관련 작업을 향상시키는 다양한 작업들을 탐구하며, 특히 비전과 언어에 중점을 둡니다.
A. 개방형 어휘 객체 탐지 및 3D 분류
Object Detection:
제로샷 탐지는 로봇이 이전에 본 적이 없는 객체를 인식할 수 있게 합니다. GLIP (Grounded Language-Image Pre-training)은 객체 탐지와 언어 이해를 결합하여 제로샷 및 몇 샷 전이를 가능하게 하여 인식 작업에 활용됩니다.
- PartSLIP은 GLIP를 확장하여 3D 부분 분할을 다루며, 포인트 클라우드와 다중 뷰 2D 바운딩 박스를 사용합니다.
- OWL-ViT는 개방형 어휘 탐지기로, 여러 텍스트 또는 이미지 기반의 쿼리를 처리하며, 로봇 조작에서 "관심 있는 객체"를 식별하는 작업에 유용합니다.
- Grounding DINO는 비전과 언어 기능을 정렬하여 객체 탐지를 향상시켜, 개방형 탐지에서 GLIP를 능가합니다.
3D Classification:
- PointCLIP은 CLIP (Contrastive Language-Image Pretraining)의 2D 지식을 3D 포인트 클라우드 이해로 전이시키며, 다중 뷰 깊이 맵을 통해 레이블을 예측합니다.
- PointBERT와 ULIP는 트랜스포머 기반 모델을 3D 포인트 클라우드로 확장하며, ULIP는 언어, 이미지, 3D 포인트 클라우드 데이터를 정렬하여 3D 인식 작업에서 큰 향상을 제공합니다.
B. 개방형 어휘 의미론적 분할
- 의미론적 분할은 각 픽셀에 레이블을 할당하여 환경을 세밀하게 이해할 수 있게 합니다.
- LSeg는 CLIP을 활용하여 언어 기반의 분할을 가능하게 하며, 테스트 시 픽셀의 유연한 레이블링과 분류를 제공합니다.
- Segment Anything Model (SAM)은 CLIP을 사용하여 희소한 프롬프트와 효율적인 데이터 확장을 통한 프롬프트 가능한 분할을 도입했으나, 실시간 처리에는 어려움이 있습니다.
- FastSAM과 MobileSAM은 더 빠른 추론 속도를 목표로 합니다.
- 도전 과제에는 레이블이 누락된 경우의 오분류와 모호한 픽셀에 대해 여러 레이블을 정의하는 데 어려움이 있습니다. 미래의 발전은 실시간 성능과 개선된 세밀한 분할을 필요로 합니다.
C. 개방형 어휘 3D 장면 및 객체 표현
3D 장면의 언어 그라운딩:
- NeRF (Neural Radiance Fields)는 고품질의 3D 재구성을 가능하게 하지만 일반적으로 알려진 카메라 포즈가 필요합니다. LERF는 CLIP 임베딩을 NeRF와 결합하여 의미론적인 3D 표현을 제공하고, 쿼리와 의미적 관련성 맵핑을 허용합니다.
- CLIP-Fields와 VLMaps는 CLIP과 언어 모델을 결합하여 3D 장면 이해를 위한 방법으로, 공간 목표 내비게이션과 같은 작업을 가능하게 합니다.
- 3D-LLM은 2D 비전-언어 모델을 3D 작업에 확장하여 사전 훈련된 2D 모델을 사용하고, 3D-언어 데이터를 생성하여 3D 캡션 작성과 질문 응답 등의 작업을 지원합니다.
장면 편집:
- CLIP-NeRF는 텍스트 또는 이미지 프롬프트를 사용하여 NeRF 표현을 조작함으로써 3D 장면 편집을 가능하게 하지만, 특정 영역보다는 전체 장면에 영향을 미칠 수 있습니다.
- Nerflets는 더 작은 지역화된 신경 방사 필드로 장면을 표현하여 더 구체적이고 제어된 편집을 가능하게 합니다.
- 로봇 응용 프로그램인 ROSIE와 GenAug는 이미지 편집을 통해 다양한 배경과 객체로 훈련 데이터를 증강하여 정책 훈련을 수행합니다.
객체 표현:
- 객체 대응 관계를 학습하면 로봇이 새로운 객체 인스턴스로 조작 기술을 전이할 수 있습니다. F3RM과 DINO와 같은 방법들은 이미지 특징을 정렬하여 객체 표현을 생성하고, 그에 따라 잡기 및 조작과 같은 작업을 지원합니다.
D. 학습된 가능성 (Learned Affordances)
가능성(affordances)은 객체나 환경이 에이전트에게 제공할 수 있는 특정 기능이나 상호작용의 잠재력을 의미합니다. 이를 통해 로봇은 물체를 밀거나 잡는 등의 행동을 예측하고 수행할 수 있습니다.
- Affordance Diffusion:
- 사람의 손과 객체 간의 상호작용을 합성하는 모델로, RGB 이미지를 기반으로 손의 자세와 객체를 잡는 방법을 예측합니다.
- Vision-Robotic Bridge (VRB):
- 인터넷 비디오에서 인간의 행동을 학습하여 로봇이 환경 내에서 상호작용하는 방식을 예측합니다. 이 모델은 오프라인 학습, 탐험, 목표 조건 학습, 강화 학습 등 다양한 로봇 학습 방식에 통합될 수 있습니다.
E. 예측 모델 (Predictive Models)
예측 동역학 모델(world models)은 특정 행동이 세계 상태를 어떻게 변화시킬지를 예측하는 모델입니다. 최근에는 비전 트랜스포머와 확산 모델을 활용한 예측 성능이 향상되었습니다.
- Phenaki 모델:
- 텍스트 프롬프트를 기반으로 몇 분 길이의 변형 가능한 비디오를 생성할 수 있습니다.
- GAIA-1 모델:
- 비디오, 행동, 텍스트를 기반으로 운전 비디오를 예측하는 모델로, 4700시간의 데이터를 훈련에 사용했습니다.
- COMPASS:
- 다양한 양식의 관계 정보를 캡처하는 다중 양식 그래프를 활용하여 로봇 내비게이션, 차량 경주 등 다양한 로봇 작업을 해결합니다.
V. Embodied AI
Embodied AI는 가상 환경에서 작동하는 AI 모델을 의미하며, 최근에는 Large Language Models (LLMs)를 활용하여 이러한 시스템의 능력을 확장하고 있습니다. 이를 통해 AI는 가상 환경에서 복잡한 방식으로 추론하고 상호작용할 수 있습니다.
- Statler:
- LLM에 "기억"을 통해 세계 상태를 추적하고 장기적인 추론을 가능하게 하는 프레임워크입니다. 두 가지 LLM(세계 모델 리더와 세계 모델 작가)을 사용하여 세계 상태를 유지합니다.
- EgoCOT과 EmbodiedGPT:
- EgoCOT: 고품질 비디오와 언어 명령이 포함된 데이터셋으로, AI 에이전트의 훈련에 사용됩니다.
- EmbodiedGPT: 7B LLM을 기반으로 하는 에이전트로, 다양한 임베디드 작업을 수행하는 데 필요한 계획, 제어, 시각적 캡션, 질문 응답 등을 개선합니다.
- Minecraft 기반의 Embodied Agents:
- MineDojo: Minecraft에서 다양한 작업을 수행할 수 있는 에이전트를 개발할 수 있는 프레임워크로, 광산 채굴, 도구 제작 및 구조물 구축 등이 포함됩니다.
- Voyager: GPT-4 기반의 에이전트로, 환경을 지속적으로 탐색하고 GPT-4를 통해 주어진 상황에 맞는 새로운 작업을 수행합니다.
- 목표 분해와 제어:
- Ghost in the Minecraft (GITM): 목표를 하위 목표로 나누고 이를 실행할 수 있도록 제어 신호를 생성하는 시스템입니다.
- 강화 학습(RL)과 LLM의 결합:
- 보상 설계: LLM을 사용하여 RL 에이전트의 보상 기능을 단순화하고 에이전트가 원하는 행동을 하도록 유도합니다.
- Exploring with LLMs (ELLM): 언어 모델이 제시하는 목표를 달성하는 에이전트에게 보상을 제공하는 방법입니다.
- VPT (비디오 사전 학습):
- 에이전트가 온라인 비디오를 통해 동작을 학습하는 방법으로, Minecraft 작업에서 제로샷 성능을 보입니다.
Generalist AI:
- 도전 과제: 다양한 환경과 작업을 수행할 수 있는 AI를 개발하는 것입니다.
- 생성적 시뮬레이터: 로봇 학습을 위한 다양한 환경과 작업을 생성할 수 있는 도구입니다.
- Generative Agents: 인간 행동을 실시간으로 시뮬레이션하는 에이전트를 생성하고, 이를 ChatGPT와 같은 LLM과 결합하여 상호작용 작업을 수행합니다.
- Gato: 다양한 작업을 처리할 수 있는 일반화된 에이전트로, Atari 게임을 하거나 이미지를 캡션하고, 로봇 팔을 제어하는 등의 작업을 동일한 신경망으로 수행합니다.
시뮬레이터:
시뮬레이터는 현실 세계에서 로봇을 테스트하고 훈련하는 데 중요한 역할을 합니다.
- iGibson & Habitat: 내비게이션 및 상호작용과 같은 작업을 위한 고급 시뮬레이션 플랫폼입니다.
- RoboTHOR: 임베디드 AI 개발을 위한 현실적인 물리적 시뮬레이션 환경을 제공합니다.
- VirtualHome: 일상적인 가정 활동을 모델링하여 로봇이 가정 환경에서 작업을 수행하는 테스트를 지원합니다.
VI. CHALLENGES AND FUTURE DIRECTIONS
이 섹션에서는 로봇 공학 환경에 기초 모델을 통합하는 데 따른 도전 과제와 이를 해결하기 위한 미래의 가능성에 대해 살펴봅니다.
A. 로봇을 위한 기초 모델 학습의 데이터 부족 극복
로봇 공학 분야의 데이터는 인터넷 규모의 텍스트와 이미지 데이터에 비해 부족합니다. 이를 극복하기 위한 여러 기술들이 제시되었습니다.
- 비구조적 놀이 데이터 및 레이블 없는 인간 비디오를 활용한 학습 확장
놀이 데이터는 레이블이 없고 수집이 저렴하며 풍부한 정보를 제공합니다. 예를 들어, Play-LMP에서는 사람의 놀이 데이터를 활용하여 로봇 학습을 확장하고, MimicPlay는 인간의 놀이 데이터를 기반으로 목표 조건에 맞는 경로 생성 모델을 학습시킵니다. - 인페인팅을 이용한 데이터 증강
로봇 데이터를 수집하는 과정에서 비용과 안전 문제가 발생할 수 있습니다. 이를 해결하기 위해 ROSIE는 텍스트-이미지 확산 모델을 사용하여 데이터 증강을 수행하며, 이는 보지 못한 객체, 배경, 방해물을 생성하는 데 사용됩니다. - 3D 기초 모델 학습을 위한 3D 데이터 부족 해결
현재 다중 모달 비전-언어 모델(VLM)은 2D 이미지를 분석할 수 있지만, 3D 공간 관계와 같은 3D 관련 작업에 한계가 있습니다. 이를 해결하려면 3D 데이터와 언어 설명이 결합된 새로운 데이터셋이 필요합니다. - 고품질 시뮬레이션을 통한 데이터 생성
게임 엔진을 활용한 고품질 시뮬레이션은 로봇 학습에 필요한 다양한 데이터를 효율적으로 수집할 수 있는 방법입니다. 예를 들어, TartanAir는 로봇 내비게이션 작업을 위한 데이터를 제공하며, 다양한 환경과 날씨 조건을 포함하여 현실적인 데이터를 생성합니다. - VLM을 활용한 데이터 증강
DIAL은 VLM을 사용하여 오프라인 데이터를 언어 조건에 맞게 재라벨링하는 방법을 제시합니다. - 로봇의 물리적 기술 제한
기존 로봇 트랜스포머는 로봇이 새로운 동작을 생성할 수 없다는 제약이 있습니다. 이를 해결하기 위해 인간의 동작 정보를 활용하여 로봇의 물리적 기술을 향상시키는 방법이 연구되고 있습니다.
B. 실시간 성능 (기초 모델의 높은 추론 시간)
기초 모델의 추론 시간은 로봇 시스템의 실시간 배치를 위해 중요한 문제입니다. 네트워크를 통한 모델 접근은 지연 시간이 발생할 수 있으며, 일부 로봇 시스템은 네트워크에 의존할 수 없는 시간 민감한 작업을 수행해야 합니다. 이를 해결하기 위한 방법으로는 로컬 계산만으로 작동할 수 있는 안전한 대체 모드나, 작은 크기의 특화된 모델을 로봇 하드웨어에서 실행하는 방법이 제시됩니다.
C. 다중 모달 표현의 한계
다중 모달 모델은 여러 종류의 데이터를 하나의 입력 시퀀스로 표준화하여 처리하려고 시도합니다. 그러나 다양한 모달리티 간의 차이를 단순한 임베딩으로 표현하는 데 한계가 있습니다. 예를 들어, 3D 포인트 클라우드 데이터를 텍스트로 변환하거나, 시각적, 청각적 정보를 언어로 변환하는 방법은 로봇 공학에서 중요한 도전 과제가 됩니다.
D. Uncertainty Quantification
1. 불확실성 정량화 (Uncertainty Quantification):
- 인스턴스 수준의 불확실성: 특정 입력에 대해 불확실성을 정량화하는 것(예: 자율주행 차량에서 이미지 분류를 통해 객체 레이블 예측 시 불확실성).
- 분포 수준의 불확실성: 다양한 미래 입력에 대한 불확실성을 평가하여 모델이 여러 시나리오에서 신뢰할 수 있는지 확인하는 것.
- 보정 (Calibration): 불확실성 추정이 실제 결과와 일치하도록 보정하는 것.
- 베이지안 vs. 빈도주의 해석: 특히 안전-critical한 로봇 애플리케이션에서는 빈도주의 해석이 더 중요하며, 이를 통해 실제 결과에 대한 신뢰할 수 있는 통계적 보장을 제공해야 한다.
- 분포 변화 (Distribution Shift): 모델이 훈련된 분포와 다른 환경에서 배포될 경우 불확실성 추정이 잘못될 수 있음. 로봇의 행동이 미래 상태를 변화시켜 입력 분포가 달라지는 문제.
- 사례 연구 – KNOWNO: 언어 지시를 받은 로봇을 위한 시스템으로, 불확실성을 정량화하고 필요시 인간에게 도움을 요청하는 방식. Conformal prediction을 사용하여 보정된 불확실성 추정치를 제공.
2. 안전 평가 (Safety Evaluation):
- 배포 전 안전 테스트: 모델이 배포되기 전에 다양한 시나리오에 대한 철저한 테스트가 필요하며, 이는 시뮬레이션을 통해 수행될 수 있음. 테스트가 충분히 다양한 시나리오를 다루어야 함.
- 실시간 모니터링 및 분포 외 탐지 (OOD Detection): 로봇이 동작 중에도 실패 예측, 안전 위험 예측, 새로운 분포의 입력을 처리하는 등의 모니터링을 통해 실시간으로 조치를 취해야 함.
3. 로봇에서의 기반 모델 사용:
- 플러그 앤 플레이 (Plug-and-Play) vs. 맞춤형 모델 구축: 기존의 큰 모델을 그대로 사용하는 플러그 앤 플레이 방식이나, 특정 로봇 애플리케이션에 맞춰 새로운 모델을 구축하거나 기존 모델을 세밀하게 조정하는 방식. 후자는 더 많은 제어를 제공하지만 자원 집약적임.
4. 로봇 설정의 높은 변동성:
- 로봇은 다양한 환경에서 다양한 구성으로 작동하므로, 다양한 로봇 데이터를 기반으로 훈련하여 다양한 설정에 일반화할 수 있는 모델을 만드는 것이 중요한 도전 과제입니다.
5. 벤치마킹 및 재현성:
- 실제 환경에서의 재현성: 실제 실험은 특정 하드웨어에 의존하기 때문에 재현성에 문제가 있을 수 있음. 시뮬레이터는 이러한 문제를 완화할 수 있지만, 시뮬레이션과 실제 환경 간에는 성능 차이가 발생할 수 있음. 시뮬레이션 환경의 표준화와 투명성 증진이 재현성을 향상시킬 수 있음.
출처
R. Firoozi, J. Tucker, S. Tian, A. Majumdar, J. Sun, W. Liu, Y. Zhu, S. Song, A. Kapoor, K. Hausman, B. Ichter, D. Driess, J. Wu, C. Lu, and M. Schwager, "Foundation Models in Robotics: Applications, Challenges, and the Future," arXiv preprint arXiv:2312.07843, Dec. 2023. [Online]. Available: https://arxiv.org/abs/2312.07843.
'Robotics > Paper reviews' 카테고리의 다른 글
| [논문 리뷰] Do As I Can, Not As I Say:Grounding Language in Robotic Affordances (saycan) (0) | 2025.04.04 |
|---|---|
| [논문 리뷰] Enhancing the LLM-Based Robot ManipulationThrough Human-Robot Collaboration (1) | 2025.04.02 |