이 리뷰는 오직 학습과 참고 목적으로 작성되었으며, 해당 논문을 통해 얻은 통찰력과 지식을 공유하고자 하는 의도에서 작성된 것입니다. 본 리뷰를 통해 수익을 창출하는 것이 아니라, 제 학습과 연구를 위한 공부의 일환으로 작성되었음을 미리 알려드립니다.
다른 연구에서 인간의 언어 지시를 이해하고 수행하는 AI 시스템을 다루던 중, 자연어 처리와 로봇 제어가 결합된 ‘PaLM-SayCan’ 모델을 알아보기 위해 Do As I Can, Not As I Say: Grounding Language in Robotic Affordances 논문을 알게 되어 읽게 되었습니다.
M. Ahn et al., "Do As I Can, Not As I Say: Grounding Language in Robotic Affordances," arXiv preprint arXiv:2204.01691, 2022. [Online]. Available: https://doi.org/10.48550/arXiv.2204.01691
Abstract
대규모 언어 모델(LLM)은 세상에 대한 풍부한 의미적 지식을 인코딩할 수 있습니다. 이러한 지식은 자연어로 표현된 고수준의, 시간적으로 확장된 명령을 수행하고자 하는 로봇에게 매우 유용할 수 있습니다.
하지만 언어 모델의 주요한 한계는 현실 세계의 경험이 부족하다는 점입니다. 이로 인해 특정한 구현 환경에서 의사 결정을 내리는 데 있어 그 활용이 어렵습니다. 예를 들어, 언어 모델에게 유출된 액체를 청소하는 방법을 설명하라고 하면 타당한 설명을 내놓을 수는 있지만, 이를 실제 환경에서 수행해야 하는 로봇에게는 적용되지 않을 수 있습니다.
우리는 이를 해결하기 위해, 사전에 학습된 스킬(skill)을 이용해 현실 기반을 제공하고자 합니다. 이 스킬들은 모델이 실행 가능하며 맥락상 적절한 자연어 동작만을 제안하도록 제한하는 데 사용됩니다.
로봇은 언어 모델의 "손과 눈" 역할을 하며, 언어 모델은 과제에 대한 고수준의 의미적 지식을 제공합니다. 이 연구는 저수준 스킬과 대규모 언어 모델을 결합하는 방식을 제시합니다. 언어 모델은 복잡하고 시간적으로 확장된 지시 사항에 대한 고수준 절차를 제공하고, 스킬과 연결된 가치 함수(value function)는 이 지식을 실제 물리적 환경에 연결하는 데 필요한 근거를 제공합니다.
우리는 이 방법을 다양한 실제 로봇 작업에 적용하여, 현실 기반 지식의 중요성을 입증하고, 이 접근 방식이 모바일 매니퓰레이터를 통해 장거리 추상 자연어 명령을 수행할 수 있음을 보여줍니다.
Introduction
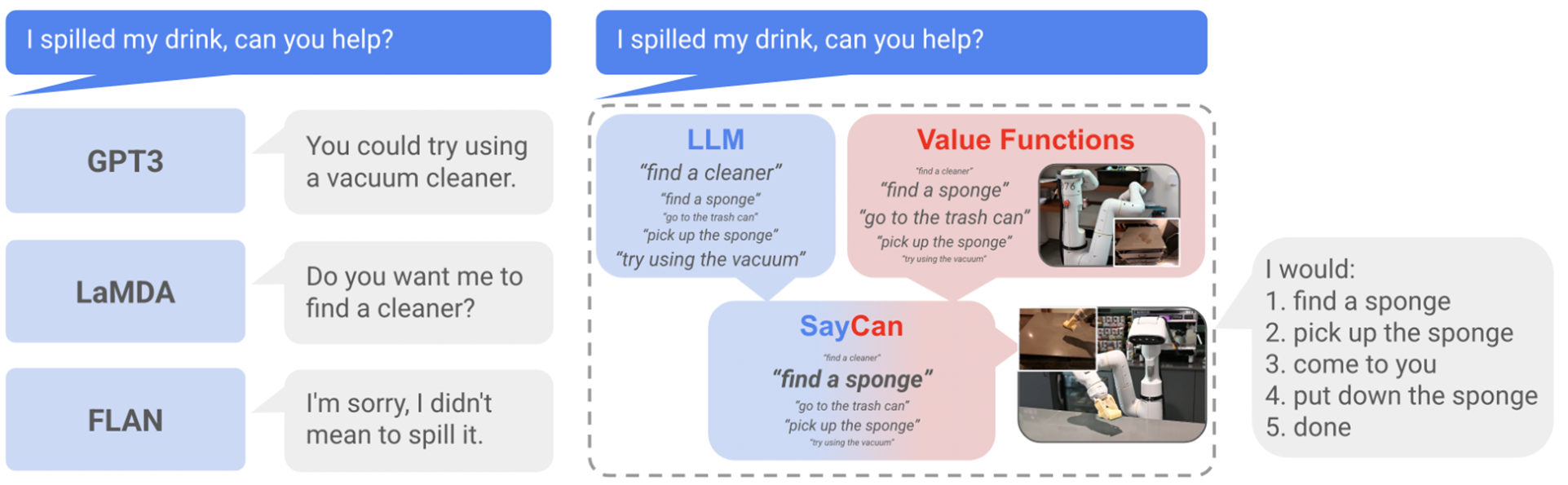
최근 대규모 언어 모델(LLM)의 발전으로 인해, 다양한 주제에 대한 복잡한 문장을 생성하거나 질문에 대답하고, 대화까지 수행할 수 있는 시스템이 등장했습니다. 이처럼 LLM은 웹에서 수집된 방대한 양의 텍스트에서 지식을 학습하지만, 이 지식을 실제 로봇이 물리적으로 활용하기는 어렵습니다. 그 이유는 LLM이 현실 세계에서 직접 경험하거나 결과를 관찰한 적이 없기 때문입니다. 예를 들어, 로봇이 "음료를 쏟았어요, 도와줄래요?"라는 요청을 받았을 때, LLM은 "진공청소기를 사용하는 게 좋겠어요"라고 말할 수 있지만, 실제로 그 로봇이 진공청소기를 쓸 수 있는지는 고려하지 않습니다. 이 연구에서는 로봇이 현실 세계에서 수행 가능한 동작만을 선택하도록 하기 위해, 사전에 학습된 스킬과 가치 함수(affordance functions)를 활용해 LLM을 보완합니다.
SayCan이라는 시스템은 다음 두 가지를 결합합니다:
- Say: 언어 모델이 제공하는 고수준 지식 (어떤 작업이 필요한지)
- Can: 로봇이 실제 환경에서 무엇을 할 수 있는지에 대한 정보 (가치 함수 기반 스킬 선택)
이 조합을 통해, 로봇은 명령을 현실 가능한 단계들로 나누어 실행할 수 있으며, 그 결과는 해석 가능하고 명확한 행동 계획으로 이어집니다.
사전 지식 (Preliminaries)
대규모 언어 모델 (Large Language Models)
언어 모델은 주어진 텍스트 W = {w0, w1, w2, ..., wn}의 확률 p(W)를 모델링하는 것을 목표로 합니다. 이 확률은 체인 룰을 이용해 다음과 같이 분해할 수 있습니다:
p(W) = Π p(wj | w<j)
즉, 각 단어는 그 이전 단어들로부터 예측됩니다.
최근에는 어텐션 기반 신경망(Transformer) 구조의 등장으로, 이른바 대규모 언어 모델(LLM)들이 빠르게 확장되었습니다. 대표적인 모델로는 Transformers, BERT, T5, GPT-3, Gopher, LAMDA, FLAN, PaLM 등이 있으며, 이들은 수십억 개의 파라미터와 수 테라바이트의 텍스트를 기반으로 학습되어 다양한 작업에 대한 일반화 능력을 보여주고 있습니다.
본 논문에서는 이러한 LLM에 담긴 풍부한 의미 지식을 활용해 고수준 자연어 명령을 수행하는 데 적합한 작업을 추론하는 데 사용합니다.
가치 함수(Value Function)와 강화학습(RL)
이 연구의 목적은 주어진 스킬이 현재 상태에서 실행 가능한지를 정확하게 예측하는 것입니다. 우리는 이를 위해 TD(Temporal-Difference) 기반의 강화학습 기법을 사용합니다.
먼저, 마르코프 결정 과정(MDP)을 다음과 같이 정의합니다:
- S: 상태 공간
- A: 행동 공간
- P: 상태 전이 확률 함수
- R: 보상 함수
- γ: 할인율
목표는 로봇이 주어진 언어 명령(예: "바닥을 청소해줘")에 대해, 현재 상태에서 그 명령을 수행할 수 있는지 예측하는 것입니다. 예를 들어, 특정 상태에서 로봇이 "스폰지를 집어라"라는 명령을 실행할 수 있는지 여부를 판단하는 것입니다.
이를 위해, 시간 차이 기반의 강화학습 (Temporal-Difference Reinforcement Learning)을 사용하여 이 문제를 해결하려고 합니다. TD 방법은 에이전트가 환경과 상호작용하면서 상태(state)와 행동(action)의 값을 학습하는 방식입니다.
마르코프 결정 과정 (MDP)
이 문제를 해결하기 위해 마르코프 결정 과정 (Markov Decision Process, MDP) 을 정의합니다. MDP는 강화학습에서 에이전트가 어떻게 학습하고 결정을 내리는지에 대한 수학적 모델입니다. MDP는 5개의 요소로 구성됩니다:
2.1. S (상태 공간, State Space):
- S는 가능한 모든 상태들의 집합입니다.
- 상태는 에이전트가 처한 환경의 특정 순간을 나타내며, 예를 들어 로봇의 위치나 상태 (예: "스폰지가 테이블 위에 있다" 등)일 수 있습니다.
2.2. A (행동 공간, Action Space):
- A는 에이전트가 취할 수 있는 행동들의 집합입니다.
- 예를 들어, 로봇이 할 수 있는 행동은 "스폰지 집기", "청소기 켜기", "테이블로 이동하기" 등이 될 수 있습니다.
2.3. P (상태 전이 확률 함수, State Transition Function):
- **P : S × A × S → R+**는 상태 전이 확률 함수입니다. 즉, 상태 s에서 행동 a를 취했을 때, **새로운 상태 s'**로 전이될 확률을 나타냅니다.
- 예를 들어, "로봇이 스폰지를 집으려 할 때, 스폰지가 테이블 위에서 떨어지지 않을 확률" 같은 것을 모델링할 수 있습니다.
2.4. R (보상 함수, Reward Function):
- R : S × A → R는 보상 함수입니다. 이는 주어진 상태 ss에서 특정 행동 aa를 취했을 때 얻는 보상을 나타냅니다.
- 보상은 에이전트가 행동을 통해 환경과 상호작용하면서 얻는 피드백입니다. 예를 들어, "스폰지를 집으면 +10 포인트", "실수하면 -5 포인트"처럼 설정될 수 있습니다.
2.5. γ (할인 인자, Discount Factor):
- **γ (감마)**는 할인 인자로, 미래의 보상에 대한 중요도를 설정합니다.
- 0 ≤ γ < 1 범위 내에서 값을 가질 수 있으며, γ가 0이면 에이전트는 현재 보상만을 중요시하고, γ가 1이면 미래 보상을 현재 보상과 똑같이 중요하게 다룹니다.
- 예를 들어, γ가 0.9이면, 미래에 받을 보상은 현재 보상보다 90%만큼 중요하게 고려됩니다.
마르코프 결정 과정 (MDP)의 역할
MDP는 강화학습에서 에이전트가 상태를 관찰하고, 행동을 취하고, 보상을 받고, 새로운 상태로 전이되는 과정을 모델링합니다. 이 과정에서 정책 (Policy)은 에이전트가 각 상태에서 어떤 행동을 취할지 결정하는 규칙입니다.
TD(Temporal Difference) 학습
- TD 학습은 강화학습에서 사용하는 기법으로, 에이전트가 미래의 보상을 예측하면서 학습을 진행하는 방법입니다. 에이전트는 현재 상태에서 미래 보상을 예측하고, 그 예측이 정확하지 않으면 이를 수정하면서 학습합니다.
- TD 방법에서는 Q-함수나 V-함수를 사용해 상태나 상태-행동 쌍의 가치를 예측하고, 이를 기반으로 정책을 개선해 나갑니다.
따라서 이 수식은 MDP를 기반으로 한 강화학습에서 에이전트가 상태와 행동을 고려하여 보상을 최적화하려고 하는 과정을 설명합니다. 목표는 주어진 언어 명령에 대한 작업이 실제로 가능한지를 예측하는 것이며, 이를 위해 강화학습에서 정의된 MDP와 TD 방법을 활용하여 상태 전이, 보상, 미래 보상을 고려하면서 학습하게 됩니다.
TD 방법의 목표는 상태-행동 가치 함수 Q(s, a)를 학습하는 것입니다. 이는 상태 s에서 행동 a를 취한 뒤 정책 π를 따라갔을 때 받을 할인된 누적 보상을 의미합니다:
Qπ(s, a) = E [Σ R(st, at)]
Q함수는 아래의 손실 함수를 통해 학습됩니다:
LTD(θ) = E[R(s, a) + γ E[Q(s', a')] − Q(s, a)]
이때 θ는 Q 함수의 파라미터이며, D는 상태-행동 데이터셋입니다.

본 논문에서는 자연어 명령을 조건으로 하는 언어 조건 가치 함수를 TD 방식으로 학습하여, 주어진 명령이 현재 상태에서 가능한지를 판단합니다.
특히, 성공하면 1, 실패하면 0의 희소 보상(sparse reward)을 주는 경우, 이 가치 함수는 어포던스 함수(affordance function)와 동일하게 작동합니다. 즉, 어떤 스킬이 현재 상태에서 실행 가능한지를 예측할 수 있게 됩니다. SayCan은 이 직관을 활용합니다.
SayCan
문제 정의
SayCan 시스템은 사용자가 제공하는 자연어 명령어 i를 입력으로 받아, 로봇이 해당 작업을 수행하도록 합니다. 이 명령어는 추상적이고 길거나 애매할 수도 있습니다.
또한, 우리는 미리 정의된 스킬 집합 Π가 있다고 가정합니다. 각 스킬 π ∈ Π는 특정한 작업(예: 스펀지 찾기)을 수행하며, 이에 대응하는 간단한 텍스트 설명 π와 함께 어포던스 함수 p(cπ | s, π)를 가집니다.
이 확률은 "현재 상태 s에서 로봇에게 `π라는 명령을 내렸을 때 성공할 확률"을 의미합니다. 이는 강화학습 관점에서 보면, 해당 스킬에 대한 가치 함수로 볼 수 있습니다.
또한 LLM은 명령 i에 대해 다음 스킬 π이 적절할 확률 p(π | i)를 제공합니다.
우리가 궁극적으로 구하고 싶은 건, 특정 스킬이 현재 상태 s에서 주어진 명령 i를 성공적으로 수행할 가능성인:
p(ci | i, s, `π)
이 확률은 다음과 같이 분해할 수 있습니다:
p(ci | i, s, π) ∝ p(cπ | s, π) × p(`π | i)
- p(`π | i): 명령 i에 대해 해당 스킬이 적절한지를 의미 (task-grounding)
- p(cπ | s, `π): 현재 상태에서 해당 스킬이 가능한지를 의미 (world-grounding)
이 두 확률을 곱해, 각 스킬이 전체 작업을 성공적으로 이끌 확률을 계산할 수 있습니다.
로봇과 LLM의 연결
LLM은 광범위한 지식을 가지고 있지만, 이것이 반드시 실제 로봇이 실행 가능한 저수준 동작으로 변환되는 건 아닙니다.
예를 들어, “로봇이 사과를 가져다 줄 수 있을까?”라는 질문에 대해, LLM은 “근처 가게에 가서 사과를 사다 주세요”라고 말할 수 있습니다. 하지만 실제 로봇은 가게에 갈 수 없고, 단순한 스킬만 수행할 수 있습니다.
따라서 LLM에게 로봇이 가진 저수준 스킬 집합 내에서만 답변하도록 유도해야 합니다. 이를 위해 우리는 프롬프트 엔지니어링(prompt engineering)을 활용합니다. 프롬프트에 "이런 식으로 답하라"고 예시를 넣어 모델이 그 패턴을 따르게 하는 방식입니다.
그러나 이 방법만으로는 충분하지 않습니다. 여전히 모델이 로봇이 할 수 없는 동작을 제안할 수 있기 때문입니다.
SayCan: 핵심 아이디어
LLM의 추론을 '어포던스 기반 가치 함수'로 현실에 연결한다.
- 각 스킬 π는 텍스트 설명 π와 가치 함수 p(cπ | s, π)를 가짐
- 모든 스킬에 대해 이 값을 모아 어포던스 공간(affordance space)을 구성함
- LLM은 p(π | i)를 제공하고, 어포던스는 p(cπ | s, π)를 제공
- 두 값을 곱해 가장 높은 확률을 가진 스킬을 선택:
π = argmax p(cπ | s, π) × p(π | i)
이 과정을 반복하며 스킬을 순차적으로 선택하고 실행해, 전체 고수준 명령을 수행합니다. 예를 들어:
사용자: “콜라캔 하나 가져다 줄래?”
로봇(LMM 응답):
1) 콜라캔을 찾는다
2) 콜라캔을 집는다
3) 그것을 사용자에게 가져간다
이 방식은 다음과 같은 장점이 있음:
- 계획이 언어로 표현되기 때문에 해석 가능함
- 상황에 맞는 동작만 선택함
로봇 시스템에서 SayCan 구현하기
언어 조건 제어 정책 (Language-Conditioned Policies)
SayCan을 구현하려면, 각 스킬마다 정책(policy), 가치 함수(value function), 짧은 언어 설명(예: “캔을 집어 들어”)이 필요합니다.
이러한 스킬과 설명은 여러 방식으로 만들 수 있지만, 본 논문에서는 두 가지 방법을 사용합니다:
- BC-Z (Behavior Cloning from Images): 이미지를 기반으로 한 행동 모방 학습
- MT-Opt: 멀티태스크 강화학습 기법
스킬의 정책을 어떤 방식으로 학습하든, 우리는 항상 TD 기반의 가치 함수를 어포던스 모델로 사용합니다.
현재까지는 행동 모방(BC)이 더 높은 성공률을 보였지만,
RL 기반의 가치 함수는 상황을 이해하고 해석하는 데 핵심적인 역할을 하며,
스킬의 실행 가능성에 대한 추상화된 판단을 제공합니다.
멀티태스크 학습 (Multi-task BC & RL)
스킬이 많기 때문에, 각각 따로 정책과 가치 함수를 학습하지 않고,
하나의 네트워크에서 여러 스킬을 언어 입력으로 조건화해서 처리합니다.
즉, “이 언어 설명을 받았을 때 어떤 행동을 해야 하는가”를 배우는 방식입니다.
(단, 이건 저수준 스킬만 해당. 고수준 명령은 여전히 LLM이 해석해서 쪼갭니다.)
언어 임베딩 사용
각 스킬 설명은 사전학습된 문장 인코더로 임베딩을 만듭니다.
이 임베딩은 정책과 가치 함수의 입력으로 사용되며, 학습 중에는 언어 모델은 고정(freeze)합니다.
SayCan은 계획(Planning)에 사용되는 LLM과 스킬 표현(Execution)에 사용되는 임베딩용 언어 모델을 서로 다르게 활용할 수 있습니다.
저수준 스킬 학습
행동 모방 (BC)
- BC-Z 프레임워크 사용
- 실세계 데이터를 활용해 학습
강화학습 (RL)
- MT-Opt 기반으로 Everyday Robots 시뮬레이터에서 학습
- RetinaGAN으로 sim-to-real 전이
- 시뮬레이션 데모로 초기 성능 부트스트랩
- 이후 실제 데이터로 지속적인 온라인 학습 수행
액션 공간(action space):
- 로봇 팔 위치/자세(6자유도)
- 그리퍼 열기/닫기
- 로봇 기반(base)의 x-y 이동과 회전
- 종료 명령
보상 설정
- 희소 보상(sparse reward): 성공 시 1.0, 실패 시 0.0
- 성공 여부는 3명의 인간 평가자가 비디오를 보고 판단 (2/3 이상 동의 시 성공)
로봇 시스템 및 스킬 구성
SayCan은 다양한 조작 및 내비게이션 스킬을 가진 모바일 매니퓰레이터 로봇에 적용됩니다.
총 551개 스킬, 7개 스킬 카테고리, 17개 객체를 포함하며:
- 물체 잡기/놓기/재배치
- 서랍 열고 닫기
- 위치로 이동
- 특정 위치에 객체 배치
이 중 성능이 좋거나 복합 행동에 유용한 스킬을 중심으로 실험합니다.
실험 평가 (Experimental Evaluation)

실험 환경
- 장소: 실제 사무실 키친 + 이를 모방한 가상 환경 2곳
- 로봇: Everyday Robots의 모바일 매니퓰레이터
7자유도 팔 + 양쪽 손가락 그리퍼 - 객체: 15종류의 일반적인 키친 아이템
- 위치: 의미 있는 5개 장소 (2개의 조리대, 테이블, 쓰레기통, 사용자 위치)
- 관찰: RGB 카메라 입력
- LLM: 기본적으로 540B 크기의 PaLM 모델 사용
테스트 명령어 구성
총 101개의 명령어를 7개의 카테고리로 나눔:
| NL Single Primitive | 15 | 단일 스킬 요청 | 콜라캔을 놔둬 |
| NL Nouns | 15 | 명사 중심 요청 | 과일 하나 가져와 |
| NL Verbs | 15 | 동사 중심 요청 | 쌀칩을 다시 채워 |
| Structured Language | 15 | 구조화된 문장 | 쌀칩을 저쪽 조리대로 옮겨 |
| Embodiment | 11 | 로봇/환경 상태에 따라 달라짐 | 콜라를 조리대에 놔줘 (현재 상태에 따라 해석 달라짐) |
| Crowd-Sourced | 15 | 자유형 사용자 요청 | 내가 좋아하는 음료는 레드불이야, 하나 가져와 |
| Long-Horizon | 15 | 여러 단계 포함 | 테이블에 콜라를 쏟았어, 치우고 뭔가 닦을 것 좀 가져와 |
성능 지표
SayCan 성능은 두 가지 지표로 평가됩니다:
- 계획 성공률 (Plan Success Rate)
- 선택된 스킬이 명령을 제대로 해석했는가?
- 3명의 평가자가 "계획이 타당한가?"를 판단 → 2명 이상 동의 시 성공
- 실행 성공률 (Execution Success Rate)
- 실제 로봇이 명령을 제대로 수행했는가?
- 역시 비디오로 평가자 3명이 판단
“콜라캔을 버리고 스펀지를 가져와” 같은 명령은 실행 순서가 다양해도 결과적으로 맞으면 성공으로 간주
결과

PaLM-SayCan은 101개의 작업을 통해 성능을 평가받았으며, 모의 주방 환경에서 계획 성공률은 84%, 실행 성공률은 74%를 기록했습니다. 실제 주방 환경에서 성능을 테스트한 결과, 계획 성능은 3% 감소하고 실행 성능은 14% 감소했지만, PaLM-SayCan은 실제 환경에서도 상당히 잘 일반화된 성능을 보여주었습니다. 자세한 결과와 실험 비디오들은 프로젝트 웹사이트에서 확인할 수 있습니다.
두 가지 긴 호라이즌 쿼리 예시를 통해 시스템이 복잡한 순서를 계획하고 맥락을 이해하는 능력을 보여줍니다. 첫 번째 쿼리에서는 사용자가 운동 후 회복을 위한 간식을 요청했을 때, PaLM-SayCan은 물과 사과를 가져오는 대신 덜 건강한 선택을 피합니다. 두 번째 쿼리에서는 시스템이 어떤 객체를 버리고, 스폰지를 어디에 가져가야 할지 정확하게 추적합니다.
PaLM-SayCan의 의사결정 과정을 시각화한 것입니다. 알고리즘은 제공된 정보에 따라 올바른 기술을 선택하며, 그 선택이 왜 이루어졌는지 사용자에게 설명할 수 있는 방식으로 결과를 제공합니다. 예를 들어, 쿡(coke)이라는 항목이 언급되었지만, PaLM-SayCan은 청소가 필요한 항목이 무엇인지 인식하고 스폰지를 가져옵니다.
작업 성능
PaLM-SayCan은 대부분의 경우 다른 명령어 패밀리들보다 뛰어난 성능을 보입니다. 자연어 쿼리에서 동사는 성능이 더 좋았고, 시스템은 구조화된 작업, 구현 작업, 군중소싱 작업을 성공적으로 처리했습니다. 그러나 부정적인 요청이나 모호한 참조에는 어려움을 겪으며, 이는 언어 모델의 일반적인 한계입니다.
표 2는 PaLM-SayCan의 다양한 작업 패밀리 성능을 비교한 것입니다. PaLM-SayCan은 다른 절단된 시스템들과 비교하여 가장 높은 계획 및 실행 성공률을 기록했습니다. "No VF"(가치 함수 없음) 및 "Generative" 방법은 어포던스 그라운딩이 없기 때문에 낮은 성공률을 보였습니다.
언어 모델 절단
이 시스템은 더 고급 언어 모델을 사용할 때 성능이 개선됩니다. PaLM 540B 모델은 작은 모델과 FLAN 모델을 능가하며, PaLM-SayCan은 실제 로봇 작업에서 PaLM을 사용할 때 84%의 계획 성공률과 74%의 실행 성공률을 기록했습니다. FLAN 모델은 70%의 계획 성공률과 61%의 실행 성공률을 보였으며, PaLM 모델이 더 나은 성능을 보여줍니다.
표 3은 PaLM-SayCan과 FLAN을 비교한 것으로, PaLM을 사용할 경우 실제 로봇 작업에서 성능이 크게 향상되는 것을 보여줍니다. 이는 언어 모델의 발전이 로봇 작업 성능에도 직접적인 영향을 미친다는 중요한 결과입니다.
결론
우리는 SayCan을 제안하여 대형 언어 모델(LLM)의 지식을 활용하고 이를 실제 환경에서 그라운딩하여 구현된 작업을 수행하는 방법을 제시했습니다. 이 방법은 사전 훈련된 기술을 활용해 모델이 실현 가능하고 상황에 맞는 자연어 행동을 선택하도록 조정하며, 강화 학습을 통해 개별 기술의 가치 함수를 학습하고 이를 통해 언어 모델이 제공하는 고수준의 의미적 지식을 활용해 작업을 완료합니다. 실제 주방에서 모바일 조작 로봇을 사용해 자연어 지시를 성공적으로 수행하는 실험을 통해 이 방법의 효과를 입증하였으며, 언어 모델을 향상시키기만 해도 로봇의 성능이 개선되는 흥미로운 특성을 보여주었습니다.
한계점
- LLM의 한계와 편향: SayCan은 LLM의 한계와 편향을 물려받을 수 있으며, 이 모델은 훈련 데이터에 의존합니다.
- 기술의 범위와 능력: 사용자가 자연어 명령어를 통해 에이전트와 상호작용할 수 있지만, 시스템의 주요 병목 현상은 기본 기술의 범위와 능력입니다. 이 문제를 해결하기 위해서는 기술의 범위를 확장하고, 기술의 강건성을 향상시키는 것이 필요합니다.
- 실패한 기술에 대한 반응: 현재 시스템은 기술이 실패했음에도 불구하고 높은 가치를 보고할 경우, 적절히 반응하는 데 어려움이 있습니다. 이는 언어 모델에 대한 적절한 프롬프트를 통해 개선할 수 있을 것입니다.
향후 연구 방향
- 언어 모델 개선: 실제 로봇 경험을 통해 얻은 정보를 활용하여 LLM을 개선하는 방법, 특히 사실성과 현실 환경에 대한 상식적 추론 능력을 개선하는 방법에 대한 연구가 필요합니다.
- 비로봇적 환경에서의 그라운딩: 우리의 방법이 로봇의 어포던스를 점수화하는 방식으로 일반적인 가치 함수를 사용하고 있기 때문에, 로봇과 관련 없는 다른 맥락에서의 그라운딩을 어떻게 통합할 수 있을지에 대한 연구도 흥미로운 주제가 될 것입니다.
- 자연어와 로봇 프로그래밍: 자연어가 로봇을 프로그램하기 위한 올바른 온톨로지인지에 대한 논의가 필요합니다. 자연어는 환경에서의 맥락과 의미적 신호를 자연스럽게 통합하지만, 일부 작업에 대해서는 가장 설명적인 매체가 아닐 수 있습니다.
- 로봇 계획과 언어의 결합: 로봇 계획과 언어를 결합하는 방법, 언어 모델을 정책의 사전 훈련 메커니즘으로 활용하는 방법, 언어와 상호작용을 결합하는 다양한 방법들이 향후 연구의 흥미로운 방향이 될 수 있습니다
출처
https://arxiv.org/abs/2204.01691
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances
Large language models can encode a wealth of semantic knowledge about the world. Such knowledge could be extremely useful to robots aiming to act upon high-level, temporally extended instructions expressed in natural language. However, a significant weakne
arxiv.org
'Robotics > Paper reviews' 카테고리의 다른 글
| [논문 리뷰] Enhancing the LLM-Based Robot ManipulationThrough Human-Robot Collaboration (1) | 2025.04.02 |
|---|---|
| [논문 리뷰] Foundation Models in Robotics: Applications, Challenges, and the Future (0) | 2025.03.28 |