Part 1. 데이터 수집과 전처리, 그리고 시각화
프로젝트 개요
마포구의 가로 쓰레기통을 더 효율적으로 배치할 수 없을까?
그런 생각에서 출발해 서울시와 마포구에서 제공하는 공공데이터들을 수집하고,
이 데이터를 활용해 공간적 수요 기반 분석을 해봤다.
단순히 위치만 보는 게 아니라,
- 유동 인구
- 상권 밀집도
- 공원 인근 취식 가능성
- 무단투기 발생 지점
까지 고려해서 데이터 기반 의사결정을 할 수 있도록 격자 단위로 가중치를 계산해봤다.
이 글에서는 데이터 수집과 전처리, 시각화에 초점을 맞춘다. 분석 및 최적화 파트는 2부에서 다룰 예정.
1. 데이터셋 소개
1-1. 서울시 가로 쓰레기통 설치 현황
- 📄 seoul_street_bin_count_by_year_2013_2024.xlsx
- 출처: 서울 열린데이터 광장
- 2013~2024년 연도별 개수, 자치구 기준
→ 마포구의 쓰레기통 개수가 정책이나 민원에 따라 어떻게 변화했는지 추이를 확인해봤다.
https://data.seoul.go.kr/dataList/OA-15069/F/1/datasetView.do
열린데이터광장 메인
데이터분류,데이터검색,데이터활용
data.seoul.go.kr
1-2. 마포구 쓰레기통 위치 데이터
- 📄 mapo_street_bins_with_coords.csv
- 출처: 마포구청 오픈데이터 ( https://www.mapo.go.kr/site/main/openData/view?dataId=150 )
- 주소 + 세부 위치 → 카카오 API를 활용해 위경도 좌표로 변환
→ 공공데이터에 위치 좌표가 없어서 API 호출로 직접 변환해봤다.
→ 단, 초당 호출 제한이 있어 0.3초 간격으로 요청, 시간이 꽤 걸렸지만 전체 데이터 변환 완료
https://www.mapo.go.kr/site/main/openData/view?dataId=150
민원실 종합안내 | 종합민원안내 | 전자민원창구 | 대표사이트
마포구청 | 대표사이트에 오신 것을 환영합니다.마포구청소개, 전자민원 안내 ,행정정보 안내, 참여마당, 생활복지 안내
www.mapo.go.kr

카카오 API를 활용해 도로명주소와 세부 위치를 가지고 위도경도 값으로 변환하여주었다.
#df = df[df["자치구명"] == "마포구"].copy()
#df["검색어"] = "서울 " + df["도로명주소"] + df["세부위치치"]
#df["위도"] = None
#df["경도"] = None
KAKAO_API_KEY = "KakaoAK ---" # 카카오 API 키
# 주소 → 좌표 (카카오 API)
def get_lat_lon_kakao(address):
url = "https://dapi.kakao.com/v2/local/search/address.json"
headers = {"Authorization": KAKAO_API_KEY}
params = {"query": address}
try:
response = requests.get(url, headers=headers, params=params)
if response.status_code != 200:
print(f"API 요청 실패: {response.status_code}")
return pd.Series([None, None])
result = response.json()
documents = result.get("documents", [])
if documents:
lon = float(documents[0]["x"])
lat = float(documents[0]["y"])
return pd.Series([lat, lon])
else:
return pd.Series([None, None])
except Exception as e:
return pd.Series([None, None])
#for i, row in df.iterrows():
#lat, lon = get_lat_lon_kakao_keyword(row["검색어"])
#df.at[i, "위도"] = lat
#df.at[i, "경도"] = lon
#time.sleep(0.3)
1-3. 마포구 상권 기반 매출 + 업종 가중치
- 📄 mapo_sales_trash_score_2020_2024.csv
- 2020~2024년 서울시 상권 데이터 병합 후 가공
- 업종별 쓰레기 유발 가중치 부여 (커피전문점, 분식, 호프 등은 높은 점수)
→ 매출이 크고 쓰레기 유발 점수가 높은 업종일수록 길거리 쓰레기 배출 가능성이 높다고 판단했다.
2020 ~ 2024년 데이터 셋을 종합
- 연도별 파일: 서울시_상권분석서비스(추정매출-상권)_2020~2024.csv 총 5개
seoul_excel_v4.xlsx (상권코드 정보) 파일과 병합 ( https://golmok.seoul.go.kr/introduce.do )
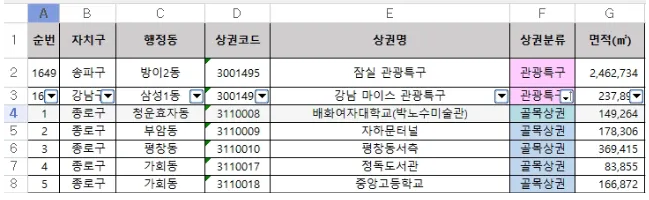
- 병합 기준: 상권_코드 (→ seoul_excel_v4.xlsx에는 상권코드)
def preview_seoul_sales_merge(area_excel_path, sales_years):
area_df = pd.read_excel(area_excel_path, engine='openpyxl')
for year in sales_years:
try:
sales_file = f"서울시_상권분석서비스(추정매출-상권)_{year}년.csv"
output_file = f"merged_seoul_data_{year}.csv"
try:
sales_df = pd.read_csv(sales_file, encoding='utf-8')
except UnicodeDecodeError:
sales_df = pd.read_csv(sales_file, encoding='cp949')
merged_df = pd.merge(sales_df, area_df, left_on="상권_코드", right_on="상권코드", how="left")
merged_df.to_csv(output_file, index=False, encoding='utf-8-sig')
except Exception as e:
print(f"{year}년 데이터 처리 중 오류 발생:", e)
# preview_seoul_sales_merge("seoul_excel_v4.xls", [2020, 2021, 2022, 2023, 2024])마포구 데이터 필터링
- 모든 연도 중 2024년 데이터(merged_seoul_data_2024.csv)에서
- "자치구" == "마포구" 조건으로 필터링

- 마포구 상권만 추출
#df = df[df["자치구"] == "마포구"].copy()
카카오 API keyword 기반 위경도 변환 및 실패 항목 확인
- REST API 키 사용
- 검색어를 이용해 위도(lat), 경도(lng) 값 요청
- 키워드 미매칭: 로그를 기준으로 주소 인식 실패 항목 추출
- 총 4개 항목에서 반복적으로 실패 확인됨:
- "서울 마포구 망원2동 KB국민은행 망원동지점"
- "서울 마포구 서교동 홍대부속여중고앞"
- "서울 마포구 상암동 상암동상점가"
- "서울 마포구 서교동 홍대소상공인상점가"
- 수동으로 경도 위도 매핑
서비스 업종별 가중치 부여
서비스 업종별 가중치를 임의로 정의, 64개의 업종 코드가 있음

각각 거리소비성과 포장재다양성, 야외취식성등을 고려하여 길거리 쓰래기 발생 확률이 높은 업종을 총점으로 정량

최종 상권 데이터와 업종 코드로 병합 ( df_merged = pd.merge(df_main, df_score[['업종', '총점']], how='left', left_on='서비스_업종_코드_명', right_on='업종') )
1-4. 마포구 도시공원 위치
- 📄 mapo_park_locations.csv
- 공원 이름, 면적, 위경도
→ 야외 취식 가능성과 포장재 소비가 높은 지역으로 판단하여 긍정적 영향 요인으로 설정했다.
https://www.mapo.go.kr/site/main/openData/view?dataId=79
민원실 종합안내 | 종합민원안내 | 전자민원창구 | 대표사이트
마포구청 | 대표사이트에 오신 것을 환영합니다.마포구청소개, 전자민원 안내 ,행정정보 안내, 참여마당, 생활복지 안내
www.mapo.go.kr
1-5. 무단투기 다발 구역
- 📄 mapo_illegal_dumping_hotspots.csv
- 민원 기반 수집 → 위경도 변환
→ 부정적 영향 요인으로 적용. 무단투기 지역 주변은 청결도 저해 요소로 간주했다.
https://www.mapo.go.kr/site/main/openData/view?dataId=169
민원실 종합안내 | 종합민원안내 | 전자민원창구 | 대표사이트
마포구청 | 대표사이트에 오신 것을 환영합니다.마포구청소개, 전자민원 안내 ,행정정보 안내, 참여마당, 생활복지 안내
www.mapo.go.kr
1-6. 마포구 유동 인구 데이터
- 📄 mapo_population_by_hour_2020_2024.csv
- 행정동, 시간대별 생활 인구 (서울 열린데이터 광장)
→ 24시간 평균 인구, 최대 인구를 추출하여 공간적 인구 밀도 분석에 활용했다.
https://data.seoul.go.kr/dataList/OA-14991/S/1/datasetView.do
열린데이터광장 메인
데이터분류,데이터검색,데이터활용
data.seoul.go.kr
- 주요 컬럼: 행정동, 시간대, 총생활인구수, 위도, 경도
- 특징:
- 시간대별 인구 이동 밀도 분석 가능
- 쓰레기 수요를 시간/공간적으로 예측하는 데 활용
2020 데이터~ 2024년 데이터까지 ( 48개 x 각 31만개 행 )
1. 행정동코드가 "11440"으로 시작하는 마포구 행정동의 데이터만 추출하고 연도별로 정리
2. 불필요한 컬럼 제거

2020년부터 2024년까지의 LOCAL_PEOPLE_DONG_20XX_MAPO_ALL.csv 파일들을 기반으로:
3. 연도별, 행정동코드별로
- 하루 24시간의 생활인구 데이터(총생활인구수)에 대해
- 시간별평균생활인구수 (24시간 평균)
- 시간별최대생활인구수 (24시간 중 최대값)
4. 각 행정동코드에 대해
- 행정동 이름(예: 아현동), 위도, 경도 정보를 병합함 (final_result = pd.merge(result, dong_df, on='행정동코드', how='left'))
1-7. 행정동 경계 및 SHP 데이터
- 📄 BND_ADM_DONG_PG.shp + Excel 코드 매핑
- 마포구 16개 동만 필터링 후 사용
→ 공간 기반 시각화와 분석을 위한 기본 지도 경계 정보로 사용했다. - 특징:
- 마포구 전체 행정동의 공간 경계 시각화 가능
- 생활 인구, 매출, 수거량 등의 데이터를 지도에 오버레이하기 위한 기본 베이스맵
- 행정동 이름(ADM_NM) 또는 코드(ADM_CD)를 기준으로 다른 데이터와 병합(merge) 가능
2. 데이터 전처리 및 시각화
Folium 라이브러리를 사용힌 시각화
folium은 Python 기반의 지도 시각화 라이브러리로, 복잡한 자바스크립트 없이도 HTML 상에서 인터랙티브한 지도(Map) 를 쉽게 생성할 수 있음
https://python-visualization.github.io/folium/latest/getting_started.html
Getting started — Folium 0.19.7 documentation
Make this Notebook Trusted to load map: File -> Trust Notebook
python-visualization.github.io
import pandas as pd
import folium
df_bins = pd.read_csv("mapo_street_bins_with_coords.csv")
df_bins = df_bins.dropna(subset=["위도", "경도"])
m = folium.Map(location=[37.56, 126.91], zoom_start=14)
for _, row in df_bins.iterrows():
popup_html = folium.Popup(
f"<div style='width: 200px;'>{row['세부위치']}</div>",
max_width=200
)
folium.Marker(
location=[row["위도"], row["경도"]],
popup=popup_html,
icon=folium.Icon(color="green", icon="trash", prefix="fa")
).add_to(m)
m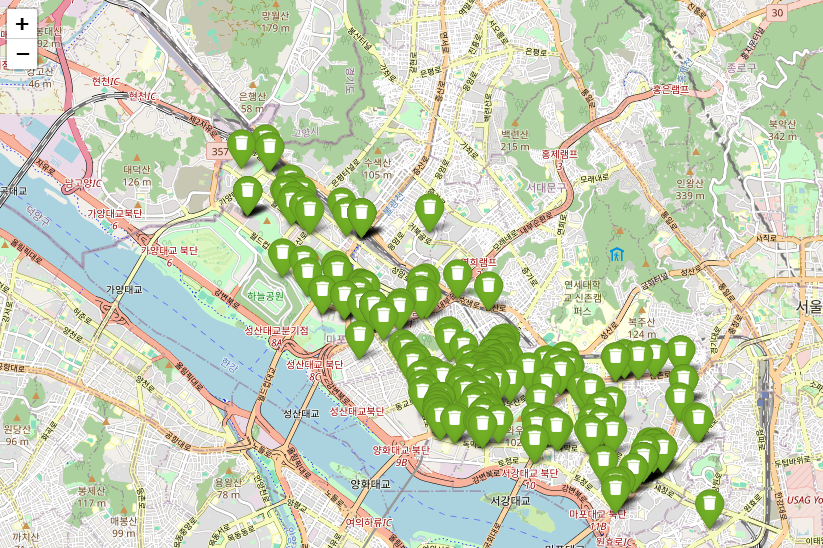
2-1. 상권 데이터 → 히트맵 만들기
folium과 HeatMap을 활용해 2020~2024년 마포구의 쓰레기 유발 상권을 시각화했다.
분석 목적
- 일평균 매출이 높고, 총점(쓰레기 유발 점수)이 높은 업종은 쓰레기통 설치가 필요할 가능성이 크다
- 연도별로 데이터를 시각화하여 쓰레기통 설치 수요 지역의 변화를 관찰할 수 있음
- 데이터 불러오기
- mapo_sales_trash_score_2020_2024.csv 파일을 불러와 연도, 위도, 경도, 일평균_매출_금액, 총점 컬럼 사용
import pandas as pd
import numpy as np
from folium.plugins import HeatMap
from IPython.display import display, HTML
df_all = pd.read_csv("mapo_sales_trash_score_2020_2024.csv", encoding='cp949')
df_all = df_all[['연도', '행정동', '위도', '경도', '당월_매출_금액', '총점']].dropna()
df_all['기여값'] = df_all['당월_매출_금액'].apply(lambda x: np.log1p(x)) * df_all['총점'] * 2
summary = df_all.groupby(['연도', '행정동'])['기여값'].sum().reset_index()
summary = summary.sort_values(['연도', '기여값'], ascending=[True, False])
- 히트맵 가중치 계산
- 총점(총점)을 히트맵의 강도(weight) 로 사용
- 매출(일평균_매출_금액)은 복제 개수(count) 로 사용하여, 매출이 클수록 점이 많이 찍혀 밀도가 높게 표현됨
- 가중치 = log(1 + 일평균_매출_금액) × 총점 × 2 → 매출이 높고 총점이 높을수록 쓰레기 유발 영향이 크다고 가정 ( 초기 설계에서서 가중치를 일편균_매출_금액 * 총점으로 했을때 일평균 금액이 너무 커 총점이 무시되는 경향을 확인하여 다음과 같이 설계)
- 연도별 히트맵 생성
- folium의 HeatMap을 사용하여 지도 위에 쓰레기 유발 상권을 표시
max_sale = df_all['당월_매출_금액'].max()
max_count = 8
# 확산산 함수
def jitter_coordinates(lat, lon, count, spread=0.0025):
return [
[lat + np.random.uniform(-spread, spread),
lon + np.random.uniform(-spread, spread)]
for _ in range(count)
]
# 연도별 히트맵
maps_html = []
for year in range(2020, 2024):
df = df_all[df_all['연도'] == year].copy()
expanded_data = []
for _, row in df.iterrows():
lat, lon = row['위도'], row['경도']
sale = row['당월_매출_금액']
score = max(int(row['총점']), 1)
ratio = sale / max_sale
count = max(1, int(ratio * max_count))
jittered = jitter_coordinates(lat, lon, count=count)
expanded_data.extend([[p[0], p[1], score] for p in jittered])
m = folium.Map(location=[37.55, 126.94], zoom_start=13)
HeatMap(expanded_data, radius=25, blur=25, max_zoom=13, min_opacity=0.2).add_to(m)
m_html = m._repr_html_()
maps_html.append(f"<div style='width: 32%; display: inline-block; vertical-align: top; margin: 5px;'><h4>{year}년</h4>{m_html}</div>")
first_row = ''.join(maps_html[:3])
second_row = ''.join(maps_html[3:])
display(HTML(f"<div>{first_row}</div><div style='margin-top: 20px;'>{second_row}</div>"))
- 총점 × log(1+매출) × 2 로 가중치 계산
- 가중치 기반으로 연도별 히트맵 생성
for year in summary['연도'].unique():
top5 = summary[summary['연도'] == year].head(5)
print(f"\n {year}년:")
print(top5[['행정동', '기여값']].to_string(index=False))- 분석 결과 : 각 연도 상위 5개 동을 콘솔로 출력해봤더니, 서교동이 압도적 1위로 유지 중이었다.
- 서교동은 5년 연속 기여값 1위를 차지함
- 홍대입구, 합정 등의 핵심 상권 포함
- 식당가, 유흥업소, 카페·음식점 밀집 지역
- 망원1동/망원2동, 서강동, 공덕동도 해마다 높은 순위를 유지
- 서강동: 신촌, 이대, 경의선 책거리 등 젊은층 유입
- 공덕동: 상업시설 밀집 + 교통 허브(마포역/공덕역)
- 망원 지역: 망리단길, 망원시장 등 핫플레이스 증가
3-1. 상권 영향력 (spread)
상권 기여값을 중심으로 주변 셀에 확산 영향력을 가우시안 필터로 퍼뜨림.
→ 가까울수록 높은 영향력, 먼 셀일수록 낮아지는 방식.
3-2. 유동 인구 가중치
행정동별 평균 인구수를 각 격자에 할당
→ point in polygon 방식으로 셀 중심이 어느 동에 속하는지 판단해서 인구수 할당
3-3. 공원 영향력
공원 중심 좌표 기준으로 주변 300m 셀까지 확산
→ 가까울수록 긍정적 영향력을 높게 줌
3-4. 무단투기 영향력
무단투기 지점을 중심으로 100m 이내 셀에 부정적 영향력 부여
→ 음수로 처리하여 청결도에 악영향을 주는 요소로 계산
다음은 이 전처리된 데이터들을를 가지고 geopandas 라이브러리와 SHP 파일을 사용하여 마포구 그리드를 만들어 가중치를 부여하여 줄 예정이다.
2025.06.02 - [Data Analysis/Project] - [Project] 데이터를 활용하여 가중치 그리드 만들기
[Project] 데이터를 활용하여 가중치 그리드 만들기
Part 2. 격자를 만들어서 가중치 정량화하기 이전글 ( 도시 데이터 선정과 전처리 )2025.06.02 - [Data Analysis/Project] - [Project] 도시 데이터를 활용한 길거리 쓰레기통 배치 최적화 해보기 - 데이터 전처
c0mputermaster.tistory.com
'Data Analysis > Project' 카테고리의 다른 글
| [Project] 도시 데이터를 활용한 길거리 쓰레기통 배치 최적화 해보기 (2) | 2025.06.04 |
|---|---|
| [Project] 데이터를 활용하여 가중치 그리드 만들기 (0) | 2025.06.02 |