Part 2. 격자를 만들어서 가중치 정량화하기
이전글 ( 도시 데이터 선정과 전처리 )
2025.06.02 - [Data Analysis/Project] - [Project] 도시 데이터를 활용한 길거리 쓰레기통 배치 최적화 해보기 - 데이터 전처리 및 시각화
[Project] 도시 데이터를 활용한 길거리 쓰레기통 배치 최적화 해보기 - 데이터 전처리 및 시각화
Part 1. 데이터 수집과 전처리, 그리고 시각화프로젝트 개요마포구의 가로 쓰레기통을 더 효율적으로 배치할 수 없을까?그런 생각에서 출발해 서울시와 마포구에서 제공하는 공공데이터들을 수
c0mputermaster.tistory.com
마포구 전체에 100m 간격 격자 생성
- geopandas 라이브러리와 SHP 파일을 사용하여 마포구 그리드 생성
- shapely, geopandas를 이용해 마포구 전체를 격자로 나눠봤다.
→ 약 100m 간격의 Grid 셀 생성
→ 각 셀에 중심 좌표(lat/lon)를 계산하여 분석 단위로 사용
사용 데이터: BND_ADM_DONG_PG.shp
- 내용: 대한민국 전체의 읍/면/동 단위 행정경계 정보를 담고 있는 Shapefile 형식의 데이터
- 대한민국 읍면동 SHP 데이터를 기반으로 마포구 16개 행정동을 필터링
- 마포구 전체 영역을 기준으로 약 100m 간격의 격자(Grid) 를 생성
- 각 격자 셀에 대해 중심 좌표 계산 및 초기 가중치 항목 컬럼 준비
import geopandas as gpd
from shapely.geometry import box, Point
import numpy as np
import os
# SHP 파일 로드 및 마포구 필터링 ( shp 데이터가 대한민국 전국 범위 )
shp_path = os.path.join("BND_ADM_DONG_PG", "BND_ADM_DONG_PG.shp")
gdf = gpd.read_file(shp_path)
mapo_dongs = [
'공덕동', '아현동', '도화동', '용강동', '대흥동', '염리동', '신수동',
'서강동', '서교동', '합정동', '망원1동', '망원2동', '연남동',
'성산1동', '성산2동', '상암동'
]
mapo_gdf = gdf[gdf['ADM_NM'].isin(mapo_dongs)].copy()
mapo_gdf = mapo_gdf.to_crs(epsg=4326)
# 격자 생성
mapo_union = mapo_gdf.geometry.unary_union
minx, miny, maxx, maxy = mapo_union.bounds
step = 0.001 # 약 100m 간격
grid_polys = []
x_range = np.arange(minx, maxx, step)
y_range = np.arange(miny, maxy, step)
for x in x_range:
for y in y_range:
cell = box(x, y, x + step, y + step)
if mapo_union.intersects(cell):
grid_polys.append(cell)
grid_gdf = gpd.GeoDataFrame(geometry=grid_polys, crs=mapo_gdf.crs)
grid_gdf['center'] = grid_gdf.geometry.centroid
grid_gdf['lat'] = grid_gdf['center'].y
grid_gdf['lon'] = grid_gdf['center'].x
# === 가중치 항목별 컬럼 ===
grid_gdf['commercial_weight'] = 0.0 # 상권 원본 값
grid_gdf['commercial_spread'] = 0.0 # 확산된 상권 영향
grid_gdf['population_weight'] = 0.0 # 동별 생활인구 수
grid_gdf['park_influence'] = 0.0 # 공원 주변 영향
grid_gdf['illegal_influence'] = 0.0 # 무단투기 영향 (감소요인)
grid_gdf['total_weight'] = 0.0 # 종합 가중치 (최종)1단계: 상권 기여값 격자화 및 시각화
- 상권 기여값이 포함된 점 데이터를 각 격자에 매핑
- 각 격자 안에 포함되는 점들의 기여값 평균을 계산하여 commercial_weight 컬럼에 저장
- 최대값 기준으로 정규화한 결과는 commercial_norm 컬럼에 저장
- Folium 지도로 시각화 (진한 파랑 → 낮은 기여값, 연한 파랑 → 높은 기여값)
# 위도·경도 기준 각 점을 Point로 변환
df_all['geometry'] = df_all.apply(lambda row: Point(row['경도'], row['위도']), axis=1)
points_gdf = gpd.GeoDataFrame(df_all, geometry='geometry', crs=mapo_gdf.crs)
# 격자별 포함되는 점들의 상권 기여값 평균 계산
for i, row in grid_gdf.iterrows():
contained_points = points_gdf[points_gdf.geometry.within(row['geometry'])]
if not contained_points.empty:
grid_gdf.at[i, 'commercial_weight'] = contained_points['기여값'].mean()
# 정규화
max_val = grid_gdf['commercial_weight'].max()
grid_gdf['commercial_norm'] = grid_gdf['commercial_weight'] / max_val if max_val else 0
# 시각화
m = folium.Map(location=[37.55, 126.94], zoom_start=13)
folium.GeoJson(mapo_gdf, name='마포구 경계').add_to(m)
for _, row in grid_gdf.iterrows():
norm = row['commercial_norm']
intensity = int((1 - norm) * 255)
color = f"#{intensity:02x}{intensity:02x}ff" # 진한 파랑일수록 낮은 값
folium.GeoJson(
row['geometry'],
style_function=lambda feature, color=color: {
'fillColor': color,
'color': 'black',
'weight': 0.2,
'fillOpacity': 0.6
},
tooltip=f"상권 기여값: {row['commercial_weight']:.1f} / 정규화: {norm:.2f}"
).add_to(m)
m # 주피터 노트북에서 지도 출력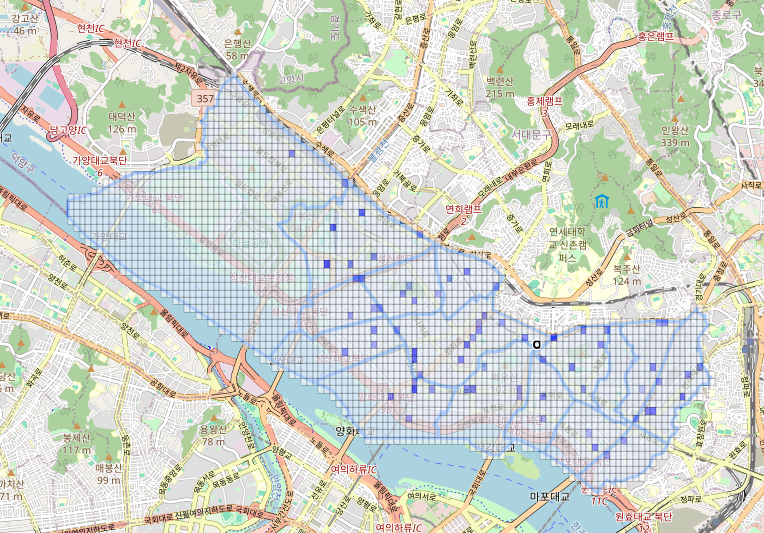
- 확산 처리:
- 각 점의 기여값을 기준으로 반경 300m(bandwidth=0.003) 이내에 있는 다른 격자들에게 가중치 분포.
- 거리 기반 가중치 산정 ( 가우시안 필터 ) → 가까울수록 더 많은 영향을 줌.
- KDTree: 각 격자 중심에서 반경 bandwidth (약 300m) 내에 있는 다른 격자를 찾기 위해 사용
from scipy.spatial import cKDTree
coords = np.array(list(zip(grid_gdf['lon'], grid_gdf['lat'])))
tree = cKDTree(coords)
# 확산 계산
weights = grid_gdf['commercial_weight'].values.copy()
spread_weight = np.zeros_like(weights)
bandwidth = 0.003 # 약 300m
for i, (lon, lat) in enumerate(coords):
idxs = tree.query_ball_point([lon, lat], r=bandwidth)
for j in idxs:
dist = np.linalg.norm(coords[i] - coords[j])
influence = np.exp(-(dist**2) / (2 * (bandwidth**2)))
spread_weight[j] += weights[i] * influence
# 저장 및 정규화
grid_gdf['commercial_spread'] = spread_weight
max_val = grid_gdf['commercial_spread'].max()
grid_gdf['commercial_spread_norm'] = grid_gdf['commercial_spread'] / max_val if max_val else 0
m = folium.Map(location=[37.55, 126.94], zoom_start=13)
folium.GeoJson(mapo_gdf, name='마포구 경계').add_to(m)
for _, row in grid_gdf.iterrows():
norm = row['commercial_spread_norm']
intensity = int((1 - norm) * 255)
color = f"#{intensity:02x}{intensity:02x}ff"
folium.GeoJson(
row['geometry'],
style_function=lambda feature, color=color: {
'fillColor': color,
'color': 'black',
'weight': 0.2,
'fillOpacity': 0.6
},
tooltip=f"상권 확산값: {row['commercial_spread']:.2f} / 정규화: {norm:.2f}"
).add_to(m)
m # 주피터 노트북에서 지도 출력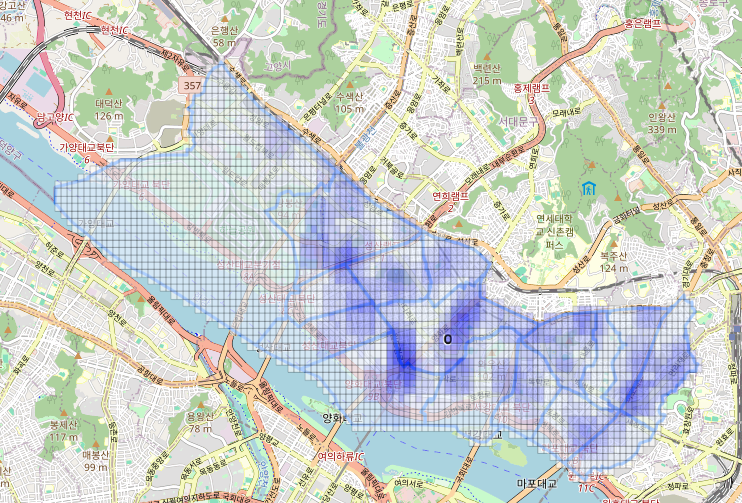
2단계: 마포구 생활인구 기반 격자 가중치 부여
- 마포구 행정동별 생활 인구 분포를 기준으로 격자(Grid) 단위로 가중치를 부여
- 이렇게 얻어진 격자별 가중치는 쓰레기통 수요가 높은 지역을 파악하는 데 활용
- 최종적으로 grid_gdf['population_weight'] 컬럼에 저장
사용 데이터
- mapo_population_by_hour_2020_2024.csv
from shapely.geometry import Point
# mapo_gdf에 '행정동'과 '평균생활인구수'가 있다면 제거
if '행정동' in mapo_gdf.columns or '평균생활인구수' in mapo_gdf.columns:
mapo_gdf = mapo_gdf.drop(columns=[col for col in ['행정동', '평균생활인구수'] if col in mapo_gdf.columns])
# 생활인구 데이터 불러오기 및 동별 평균 계산
pop_df = pd.read_csv("mapo_population_by_hour_2020_2024.csv", encoding='cp949')
dong_avg = pop_df.groupby('동명')['시간별평균생활인구수'].mean().reset_index()
dong_avg.columns = ['행정동', '평균생활인구수']
# mapo_gdf에 평균 인구수 병합
mapo_gdf = mapo_gdf.merge(dong_avg, left_on='ADM_NM', right_on='행정동', how='left')
2-1. 2020~2024 평균 마포구 동별별 생활 인구수 확인
- 생활 인구수가 가장 많은 동을 기준으로 순위를 매겨 직관적으로 확인 할 수 있도록 Top 5를 확인
top5 = mapo_gdf[['ADM_NM', '평균생활인구수']].sort_values(by='평균생활인구수', ascending=False).head(5)
print("평균 생활인구수 상위 5개 동:")
print(top5.to_string(index=False))
평균 생활인구수 상위 5개 동:
ADM_NM 평균생활인구수
서교동 69925.407424
상암동 47953.643544
공덕동 37885.517480
성산2동 35625.182178
용강동 27573.857400
2-2. 시각화 및 가중치 부여
- 정규화를 통해 population_norm 컬럼을 생성하고 시각화
# 격자별로 해당 동의 인구수를 population_weight에 할당
for i, row in grid_gdf.iterrows():
point = row['center']
for _, dong in mapo_gdf.iterrows():
if dong['geometry'].contains(point):
grid_gdf.at[i, 'population_weight'] = dong['평균생활인구수']
break
# 결측값은 0으로
grid_gdf['population_weight'] = grid_gdf['population_weight'].fillna(0)
# === 생활인구 정규화 ===
max_val = grid_gdf['population_weight'].max()
grid_gdf['population_norm'] = grid_gdf['population_weight'] / max_val if max_val else 0
# === folium 지도 시각화 ===
import folium
m = folium.Map(location=[37.55, 126.94], zoom_start=13)
folium.GeoJson(mapo_gdf, name='마포구 경계').add_to(m)
for _, row in grid_gdf.iterrows():
norm = row['population_norm']
intensity = int((1 - norm) * 255)
color = f"#{intensity:02x}{intensity:02x}ff"
folium.GeoJson(
row['geometry'],
style_function=lambda feature, color=color: {
'fillColor': color,
'color': 'black',
'weight': 0.2,
'fillOpacity': 0.6
},
tooltip=f"생활인구수: {row['population_weight']:.1f} / 정규화: {norm:.2f}"
).add_to(m)
m # 주피터 노트북에서 지도 출력

3단계: 공원 및 무단투기 다발지역 시각화
- 마포구 내 공원 위치와 무단투기 다발 구역을 지도 위에 시각화하여, 향후 쓰레기통 배치에 영향을 줄 수 있는 요소로 분석
# 지도 생성
m = folium.Map(location=[37.55, 126.94], zoom_start=13)
# 1. 공원 좌표 표시 (연두색)
parks_df = pd.read_csv("mapo_park_locations.csv", encoding='cp949')
park_coords = parks_df[['위도', '경도']].dropna().values # 공원 위도/경도
for _, row in parks_df.iterrows():
folium.CircleMarker(
location=[row['위도'], row['경도']],
radius=6,
color='green',
fill=True,
fill_color='lightgreen',
fill_opacity=0.7,
tooltip=row.get('공원명', '공원')
).add_to(m)
# 2. 무단투기 다발 구역 표시 (빨간색)
illegal_df = pd.read_csv("mapo_illegal_dumping_hotspots.csv", encoding='utf-8')
illegal_coords = illegal_df[['위도', '경도']].dropna().values # 무단투기 위도/경도
for _, row in illegal_df.iterrows():
folium.CircleMarker(
location=[row['위도'], row['경도']],
radius=6,
color='darkred',
fill=True,
fill_color='red',
fill_opacity=0.7,
tooltip=row.get('장소', '무단투기 지역')
).add_to(m)
m # Jupyter Notebook에서 지도 출력
3-1. 공원 영향력 계산
- 공원의 위치를 기준으로 인근 격자에 거리 기반 영향력을 계산. 거리 기반 확산(Gaussian)을 통해, 가까운 격자일수록 높은 영향력을 부여
- 확산 범위 300m
# 격자 중심 좌표 배열
grid_coords = np.array(list(zip(grid_gdf['lon'], grid_gdf['lat'])))
tree = cKDTree(grid_coords)
park_influence = np.zeros(len(grid_gdf))
bandwidth = 0.003 # 약 300m 확산
for lat, lon in park_coords:
idxs = tree.query_ball_point([lon, lat], r=bandwidth)
for i in idxs:
dist = np.linalg.norm(grid_coords[i] - [lon, lat])
influence = np.exp(-(dist**2) / (2 * bandwidth**2))
park_influence[i] += influence
# 정규화화
grid_gdf['park_influence'] = park_influence
max_val = park_influence.max()
grid_gdf['park_influence_norm'] = park_influence / max_val if max_val else 0
# 공원 영향력 시각화
m = folium.Map(location=[37.55, 126.94], zoom_start=13)
folium.GeoJson(mapo_gdf, name="마포구 경계").add_to(m)
for _, row in grid_gdf.iterrows():
norm = row['park_influence_norm'] # 0 ~ 1
intensity = int((1 - norm) * 255)
color = f"#{intensity:02x}ff{intensity:02x}" # 초록
folium.GeoJson(
row['geometry'],
style_function=lambda feature, color=color: {
'fillColor': color,
'color': 'black',
'weight': 0.2,
'fillOpacity': 0.6
},
tooltip=f"공원 영향력: {row['park_influence']:.2f} / 정규화: {norm:.2f}"
).add_to(m)
m # 지도 출력
3-2. 무단투기 영향력 계산
- 무단투기 지점에서 인근 격자에 음수 영향력(Gaussian Spread)을 확산시켜 청결도에 부정적 영향을 부여
- 확산 범위 100m
illegal_influence = np.zeros(len(grid_gdf))
# 확산 파라미터
bandwidth = 0.001 # 약 100m
for lat, lon in illegal_coords:
idxs = tree.query_ball_point([lon, lat], r=bandwidth)
for i in idxs:
dist = np.linalg.norm(grid_coords[i] - [lon, lat])
influence = np.exp(-(dist**2) / (2 * bandwidth**2))
illegal_influence[i] -= influence
# grid_gdf에 저장 및 정규화
grid_gdf['illegal_influence'] = illegal_influence
max_abs_val = np.abs(illegal_influence).max()
grid_gdf['illegal_influence_norm'] = illegal_influence / max_abs_val if max_abs_val else 0
m = folium.Map(location=[37.55, 126.94], zoom_start=13)
folium.GeoJson(mapo_gdf, name="마포구 경계").add_to(m)
for _, row in grid_gdf.iterrows():
norm = row['illegal_influence_norm']
if norm == 0:
color = "#ffffff"
else:
intensity = int((1 + norm) * 127.5)
color = f"#ff{intensity:02x}{intensity:02x}" # 붉은 계열
folium.GeoJson(
row['geometry'],
style_function=lambda feature, color=color: {
'fillColor': color,
'color': 'black',
'weight': 0.2,
'fillOpacity': 0.6
},
tooltip=f"무단투기 영향력: {row['illegal_influence']:.2f} / 정규화: {norm:.2f}"
).add_to(m)
m # 지도 출력
4단계: 요소별 정규화 및 종합 가중치 계산
- 상권, 인구, 공원, 무단투기 영향력을 각기 정규화하고, 가중치를 적용하여 total_weight를 계산
from sklearn.preprocessing import MinMaxScaler
# 정규화 스케일러
scaler = MinMaxScaler()
# 요소별 정규화
grid_gdf['pop_norm'] = scaler.fit_transform(grid_gdf[['population_weight']])
grid_gdf['comm_norm'] = scaler.fit_transform(grid_gdf[['commercial_spread']])
grid_gdf['park_norm'] = scaler.fit_transform(grid_gdf[['park_influence']])
# 무단투기 영향은 음수이므로 절댓값 정규화 후 다시 음수 부호 적용
illegal_abs_norm = scaler.fit_transform(np.abs(grid_gdf[['illegal_influence']]))
grid_gdf['illegal_norm'] = -illegal_abs_norm # 다시 음수로
# 가중치 비율 설정
w_pop = 0.2
w_comm = 0.4
w_park = 0.2
w_illegal = 0.2
# 가중합 계산
grid_gdf['total_weight'] = (
w_pop * grid_gdf['pop_norm'] +
w_comm * grid_gdf['comm_norm'] +
w_park * grid_gdf['park_norm'] +
w_illegal * grid_gdf['illegal_norm']
)
# 음수 제거
grid_gdf['total_weight'] = grid_gdf['total_weight'].clip(lower=0)
최종 계산된 total_weight 값을 folium을 사용하여 지도 위에 시각화
- 가중치 비율:
- 상권 확산: 0.4
- 유동 인구: 0.2
- 공원: 0.2
- 무단투기: -0.2
→ 네 가지 요소를 더해서 total_weight 컬럼 생성
import folium
# 지도 생성
m = folium.Map(location=[37.55, 126.94], zoom_start=13)
folium.GeoJson(mapo_gdf, name="마포구 경계").add_to(m)
# 최대값 기준 정규화 (색상 조절용)
max_val = grid_gdf['total_weight'].max()
for _, row in grid_gdf.iterrows():
norm = row['total_weight'] / max_val if max_val else 0
intensity = int((1 - norm) * 255)
color = f"#{intensity:02x}{intensity:02x}ff"
folium.GeoJson(
row['geometry'],
style_function=lambda feature, color=color: {
'fillColor': color,
'color': 'black',
'weight': 0.2,
'fillOpacity': 0.6
},
tooltip=f"Total Weight: {row['total_weight']:.3f}"
).add_to(m)
m # 주피터 노트북에서 지도 출력

최종적으로 folium 지도를 통해 시각화하여, 마포구 내에서도 쓰레기통 설치 수요가 높은 지역과 그렇지 않은 지역이으로 가중치를 통해 확인할 수 있었다. 다음에는 연도별 추세를 분석하고 적절한 쓰레기통 개수 예측하여 최적의 쓰레기통 위치를 찾아볼 것이다.
'Data Analysis > Project' 카테고리의 다른 글
| [Project] 도시 데이터를 활용한 길거리 쓰레기통 배치 최적화 해보기 (2) | 2025.06.04 |
|---|---|
| [Project] 도시 데이터를 활용한 길거리 쓰레기통 배치 최적화 해보기 - 데이터 전처리 및 시각화 (2) | 2025.06.02 |